BrainChip Enters AI Territory with Spiking Neural Network

It may take a machine to learn about all of the new machine-learning techniques popping up these days. BrainChip is adopting a neuromorphic computing approach that’s different from the other deep neural network (DNN)/convolutional neural network (CNN) solutions already available. BrainChip’s approach uses a technology called spiking neural networks (SNNs) (Fig. 1).
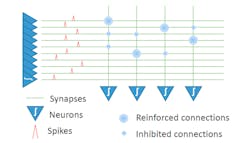
1. Spiking neural networks use asynchronous spikes from neurons to trigger other neurons through reinforced connections.
SNNs differ from DNNs and CNNs (Fig. 2) in training methods and compute requirements. At this point, they’re complementary with some overlap in application areas, but this is likely to change over time. SNNs have some interesting and useful characteristics, including the ability to be trained instantaneously, often called “one-shot learning.”
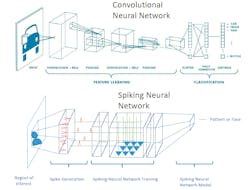
2. CNNs use a high-overhead feature-learning process—it generates weights used in a classification process that can identify multiple items. SNNs use a more efficient training mechanism, but it’s designed to identify a single entity.
SNNs can be very accurate and have low compute overhead versus DNNs/CNNs for both training and classification. The threshold logic and connection reinforcement of SNNs both exhibit high efficiency, allowing even software implementations to work on lower-end hardware. They also require less hardware to implement accelerators. Figure 3 highlights the differences between the two approaches.

3. Convolutional neural networks tend to be math-intensive with more complex training requirements, while spiking neural networks have less overhead but target more specific classification results.
BrainChip has a software solution called BrainChip Studio that runs on Intel Xeon and Core i7 processors, but its latest offering is the BrainChip accelerator (Fig. 4). The x8 PCI Express board uses Xilinx’s Kintex UltraScale FPGA. Six SNN cores are squeezed into the FPGA, with each core consuming under 1 W while processing at over 100 frames/s. The SSN approach delivers a 7X improvement compared to GPU-accelerated deep-learning classification neural networks like GoogleNet and AlexNet in terms of frames/s per watt. The board uses less than 15 W.
Initially, the accelerator is used with video-surveillance applications that need to identify a particular object. For example, a particular backpack or person may need to be tracked through video streams from dozens of cameras for security purposes. The initial image resolution can be as low as 20 by 20 pixels for patterns and 24 by 24 pixels for facial recognition. This means that the SNN-based search application can be used in low-light, low-resolution, and noisy environments while providing good results. The one-step training means the desired image can be quickly incorporated into the system.

4. The BrainChip Accelerator implements SNNs using Xilinx’s Kintex UltraScale FPGA.
SNN has other applications such as facial recognition, gaming, and visual inspection. Upscaling can help in finding objects; thus, the hardware platform handles upscaling as well as downscaling of up to 16 video streams. The maximum input video stream resolution is 1080p.
Developers will need to determine what kind of neural network will work best for their application. SNNs offer significant advantages if they can be applied to the task, whether using BrainChip’s software or hardware. Applications like augmented reality (AR), where objects of a specific type need to be located within an image, are ripe for SNN support. DNN/CNNs can identify many objects, but oftentimes this isn’t required for an application.

About the Author

William G. Wong
Senior Content Director - Electronic Design and Microwaves & RF
I am Editor of Electronic Design focusing on embedded, software, and systems. As Senior Content Director, I also manage Microwaves & RF and I work with a great team of editors to provide engineers, programmers, developers and technical managers with interesting and useful articles and videos on a regular basis. Check out our free newsletters to see the latest content.
You can send press releases for new products for possible coverage on the website. I am also interested in receiving contributed articles for publishing on our website. Use our template and send to me along with a signed release form.
Check out my blog, AltEmbedded on Electronic Design, as well as his latest articles on this site that are listed below.
You can visit my social media via these links:
- AltEmbedded on Electronic Design
- Bill Wong on Facebook
- @AltEmbedded on Twitter
- Bill Wong on LinkedIn
I earned a Bachelor of Electrical Engineering at the Georgia Institute of Technology and a Masters in Computer Science from Rutgers University. I still do a bit of programming using everything from C and C++ to Rust and Ada/SPARK. I do a bit of PHP programming for Drupal websites. I have posted a few Drupal modules.
I still get a hand on software and electronic hardware. Some of this can be found on our Kit Close-Up video series. You can also see me on many of our TechXchange Talk videos. I am interested in a range of projects from robotics to artificial intelligence.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: