
Machine learning (ML) and deep neural networks (DNNs) are topics that embedded designers are investigating and deploying, according to the recent Electronic Design’s Embedded Revolution survey. Vendors are answering this call with everything from custom hardware to GPGPUs.
Cadence is taking a different approach with its Vision C5 DSP core (Fig. 1). It is designed to accelerate all the chores of a deep neural network system to handle the changing machine-learning arena. It has vector processing units built around 1024 MACs (multiple accumulate units) and a 128-way SIMD VLIW architecture. The system even handles on-the-fly data decompression.
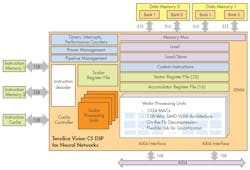
1. Cadence’s Vision C5 DSP is designed to handle neural network applications.
A single core is designed to deliver 1 TMAC/s. It is optimized for DNN applications but the hardware is not configured for any specific algorithm or approach. Instead it allows programmers to implement the most appropriate program of an application. The MAC subsystem can be configured as 1024 8-bit units or 512 16-bit units.
The Vision C5 DSP is complementary to the Vision P6 DSP that is designed to handle video (Fig. 2). A Vision P6 DSP can only deliver 200 GMACs/s compared to the Vision C5 DSP’s 1 TMAC/s. The dual-core system is just one way to design an SoC. Both cores support multicore configurations. The Vision C5 DSP can also operate by itself.
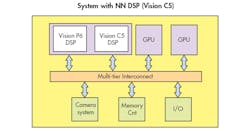
2. The Vision C5 DSP can be paired with Cadence’s Vision P6 DSP that is optimized for vision processing.
A DNN algorithm usually includes a convolution layer, a normalization and max pooling layer, a full connected layer, and another normalization and max pooling layer. These can be easily handled by CPUs and DSPs but an implementation with a hardware accelerator and sometimes a GPGPU will be split across multiple components including a CPU. This means that data needs to be moved between components increasing system overhead and latency. At this point, conventional CPUs lack the efficiency of the Vision C5 DSP when it comes to handling the matrix operations needed for a DNN (Fig. 3).

3. A Vision C5 DSP can take on DNN hardware accelerators while retaining the advantages of a programmable DSP platform.
The Vision C5 DSP builds on Cadence’s Xtensa multi-processor expertise. Tools provide automatic creation of multi-processor SystemC models. These designs support synchronous multiprocessor debugging. The multiprocessor Vision C5 DSP systems can deliver multiple TMAC/s performance allowing systems to scale to meet application requirements.
Cadence reports that the Vision C5 DSP performs six times faster than a GPGPU when running AlexNet data and nine times when using Inception V3 data. Of course, a design’s mileage will vary but this does highlight the advantages compared to the current platforms commonly in use.
The challenge is that the Vision C5 DSP needs to be incorporated into an SoC. Testing can be done on simulators but off-the-self platforms are not currently available whereas there are many GPGPU solutions available. Still, when a designer needs efficient, high-performance machine-learning support, then it is worth checking out the Vision C5 DSP architecture.

About the Author

William G. Wong
Senior Content Director - Electronic Design and Microwaves & RF
I am Editor of Electronic Design focusing on embedded, software, and systems. As Senior Content Director, I also manage Microwaves & RF and I work with a great team of editors to provide engineers, programmers, developers and technical managers with interesting and useful articles and videos on a regular basis. Check out our free newsletters to see the latest content.
You can send press releases for new products for possible coverage on the website. I am also interested in receiving contributed articles for publishing on our website. Use our template and send to me along with a signed release form.
Check out my blog, AltEmbedded on Electronic Design, as well as his latest articles on this site that are listed below.
You can visit my social media via these links:
- AltEmbedded on Electronic Design
- Bill Wong on Facebook
- @AltEmbedded on Twitter
- Bill Wong on LinkedIn
I earned a Bachelor of Electrical Engineering at the Georgia Institute of Technology and a Masters in Computer Science from Rutgers University. I still do a bit of programming using everything from C and C++ to Rust and Ada/SPARK. I do a bit of PHP programming for Drupal websites. I have posted a few Drupal modules.
I still get a hand on software and electronic hardware. Some of this can be found on our Kit Close-Up video series. You can also see me on many of our TechXchange Talk videos. I am interested in a range of projects from robotics to artificial intelligence.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: