64-Bit Arm Incarnation Employs Dynamic Code Optimization
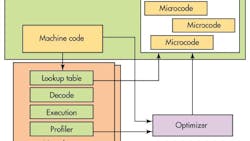
NVidia often takes an interesting approach with its technology, and the firm’s upcoming dual-core Tegra K1-64 is no different. It employs the Denver CPU architecture that implements ARM’s ARMv8 64-bit architecture (see “ARM Joins The 64-bit Club”), but does so much differently than most other ARMv8 platforms.
NVidia has an ARMv8 ISA license rather than a Cortex-A57 core license. There are others that have taken this approach as well. This means that the resulting processor needs to match the ARMv8 ISA, but it can be implemented much differently than ARM’s Cortex-A57 design.
Denver’s code morphing approach is similar to that found in Transmeta processors available almost a decade ago (see “Low-Power VLIW CPU Delivers Speedy x86 Upgrade”). Code morphing is also known as dynamic code optimization. The technique is similar to Java’s just-in-time (JIT) compilers. In both cases the object code is converted into microcode instructions that are cached. The conversion takes place once, and then the microcode can be executed repeatedly without additional overhead.
This file type includes high resolution graphics and schematics when applicable.
The Denver cores run their own microcode directly. ARMv8 instructions are converted to this microcode before being executed (see the figure). An on-chip, 1K look-up table is used to check if a microcode sequence has already been generated by an Optimizer program and placed into the optimization cache.
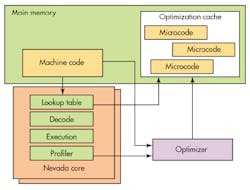
The optimization cache is 128 Mbytes and it is stored in main memory. The cache is only accessible by the hardware and the Optimizer. The latter is also hidden from the system. It is written in microcode, so it does not have to use the conversion process that the ARMv8 instructions need. The Optimizer can run on either core when they are idle. It can also be interrupted. It handles management of the cache in addition to performing the optimized code conversion.
The code sequences in the cache are matched to the jump transitions of the ARMv8 instructions. This allows a block to be selected and run sequentially.
The reason for these gyrations is that the code generated by the decoder may be less efficient than what is generated by the Optimizer. It can take into account all the execution units available as well as timing and power details.
The Denver core can execute more than 7 ARMv8 instructions per cycle when using optimized code. The cache delivers a 32-byte “parcel” to the instruction scheduler every cycle. The parcel is actually a series of variable length instructions that will be passed onto the execution units.
The profiler provides information to the Optimizer program about what blocks to optimize and how to ensure the code is being executed. Frequently used blocks get more optimization.
The platform targets mobile devices that need to be very power-efficient. It also addresses applications that need the performance usually found in a 64-bit x86 platform.
About the Author

William G. Wong
Senior Content Director - Electronic Design and Microwaves & RF
I am Editor of Electronic Design focusing on embedded, software, and systems. As Senior Content Director, I also manage Microwaves & RF and I work with a great team of editors to provide engineers, programmers, developers and technical managers with interesting and useful articles and videos on a regular basis. Check out our free newsletters to see the latest content.
You can send press releases for new products for possible coverage on the website. I am also interested in receiving contributed articles for publishing on our website. Use our template and send to me along with a signed release form.
Check out my blog, AltEmbedded on Electronic Design, as well as his latest articles on this site that are listed below.
You can visit my social media via these links:
- AltEmbedded on Electronic Design
- Bill Wong on Facebook
- @AltEmbedded on Twitter
- Bill Wong on LinkedIn
I earned a Bachelor of Electrical Engineering at the Georgia Institute of Technology and a Masters in Computer Science from Rutgers University. I still do a bit of programming using everything from C and C++ to Rust and Ada/SPARK. I do a bit of PHP programming for Drupal websites. I have posted a few Drupal modules.
I still get a hand on software and electronic hardware. Some of this can be found on our Kit Close-Up video series. You can also see me on many of our TechXchange Talk videos. I am interested in a range of projects from robotics to artificial intelligence.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: