More Details Emerge About Arm’s Machine Learning

Arm is definitely targeting deep-neural-network (DNN) machine-learning (ML) applications with its proposed hardware designs, but its initial ML hardware descriptions were a bit vague (Fig. 1). Though the final details aren’t ready yet, ARM has exposed more of the architecture.
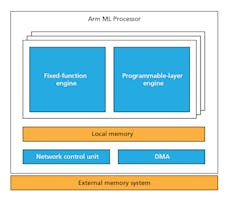
1. Arm’s original description of its machine-learning hardware was a bit vague.
The Arm ML processor is supported by the company’s Neural Network (NN) software development kit that bridges the interface between ML software and the underlying hardware. This allows developers to target Arm’s CPU, GPU, and ML processors. In theory, waiting for the ML hardware will allow a critical mass of software to be available when the real hardware finally arrives. Most of the differences between the underlying hardware are hidden by runtimes and compilers.
In a sense, this is the same approach Nvidia is taking with its CUDA platform that targets a range of its GPUs. These GPUs are similar, but each has slight differences hidden by the CUDA support. Having their own framework makes it difficult for developers to move to different platforms. CUDA handles more than just artificial-intelligence (AI) and ML applications. Developers targeting higher-end ML tools like TensorFlow can usually move from platform to platform including Arm’s ML processor.
Nvidia’s NVDLA
Nvidia has also released the NVIDIA Deep Learning Accelerator (NVDLA) as open-source hardware. NVDLA is used in the company’s Xavier system-on-chip (SoC) designed for automotive and self-driving car applications.
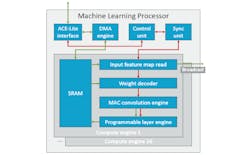
2. The machine-learning processor developed by Arm consists of an array of compute engines with MAC convolution and programmable layer engines.
The ML processor incorporates an array of up to 16 sophisticated compute engines (Fig. 2). Each engine has its own local memory that’s used by the modules to process DNN models. The flow is typical for DNN implementations, starting with weights being applied to incoming data, processing via the MAC convolution engine, and then results processed by the programmable layer engine (PLE). The MAC convolution engine has 128 multiple-accumulate (MAC) units.
The PLE (Fig. 3) is a vectorized microcontroller that processes the result of the convolution. It’s more like a RISC platform optimized for wrapping up the processing of a layer for a section of a DNN model that has many layers. The processing requires many iterations through the system, which will be processing sections in parallel. The PLE handles chores such as pooling and activation.
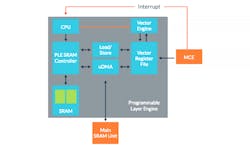
3. The Arm programmable layer engine is essentially a vectorized microcontroller designed to handle neural-network layer operations.
At TOPS Speed
Arm’s initial implementation is designed to deliver 4.6 tera operations/s (TOPS). The version designed for high-end mobile devices is designed to deliver 3 TOPS/W using 7-nm chip technology. The design is scalable, allowing it to be employed with Arm’s range of microcontroller and microprocessor designs. The system is designed to scale from 20 gigaoperations/s (GOPS) for the Internet of Things (IoT) to 150 TOPS for high-end enterprise applications. Of course, low-end platforms will not be as powerful, but will use much less power.
Part of the challenge of nailing down a final design is how to address details such as the type and magnitude of the weights involved in the DNN. The datatypes may be as small as one bit, and a number of tiny floating-point formats are being used in ML research.
More details are expected later this year. In the meantime, though, developers are already using Arm CPU and GPU platforms for ML tasks.

About the Author

William G. Wong
Senior Content Director - Electronic Design and Microwaves & RF
I am Editor of Electronic Design focusing on embedded, software, and systems. As Senior Content Director, I also manage Microwaves & RF and I work with a great team of editors to provide engineers, programmers, developers and technical managers with interesting and useful articles and videos on a regular basis. Check out our free newsletters to see the latest content.
You can send press releases for new products for possible coverage on the website. I am also interested in receiving contributed articles for publishing on our website. Use our template and send to me along with a signed release form.
Check out my blog, AltEmbedded on Electronic Design, as well as his latest articles on this site that are listed below.
You can visit my social media via these links:
- AltEmbedded on Electronic Design
- Bill Wong on Facebook
- @AltEmbedded on Twitter
- Bill Wong on LinkedIn
I earned a Bachelor of Electrical Engineering at the Georgia Institute of Technology and a Masters in Computer Science from Rutgers University. I still do a bit of programming using everything from C and C++ to Rust and Ada/SPARK. I do a bit of PHP programming for Drupal websites. I have posted a few Drupal modules.
I still get a hand on software and electronic hardware. Some of this can be found on our Kit Close-Up video series. You can also see me on many of our TechXchange Talk videos. I am interested in a range of projects from robotics to artificial intelligence.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: