Checking Out the Jetson Xavier NX

Nvidia’s Jetson Xavier NX (Fig. 1) is the next in a line of compact machine-learning (ML) accelerated system-on-chip (SoC) modules. The module uses the same form factor of the popular Jetson Nano. The 70- × 45-mm DIMM form factor is ideal for rugged, mobile solutions like drones and robots as well as embedded systems that need artificial-intelligence (AI) applications. The Jetson Xavier NX can deliver more than 21 trillion operations per second (TOPS) while using less than 15 W. It does flip on the cooling fan when drawing this much power.

The SoC has a six-core NVIDIA Carmel 64-bit CPU island that’s compatible with the ARM v8.2 architecture (Fig. 2). The GPGPU architecture is the company’s Volta with 384 CUDA cores and 48 Tensor cores. It’s complemented with a pair of NVDLA Engines; these deep-learning accelerators (DLAs) speed up inference models. The video encoders and decoders can handle multiple data streams up to a pair of 4K video streams. Two CSI-2 MIPI interfaces provide connections to cameras. The vision accelerator is a 7-way VLIW processor.
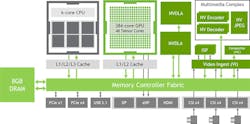
The module has a Micro-SD socket. There’s 8 GB of 128-bit LPDDR4 DRAM.
Looking at the development, the module is placed onto a 103- × 90.5- × 31-mm carrier board (Fig. 3). This exposes Gigabit Ethernet, four USB 3.1 ports, and a USB 2.0 Micro-B port. The system includes Bluetooth and Wi-Fi support courtesy of an M.2 Key-E module. The full-length, M.2 NVMe module plugs in the bottom of the carrier board.

The Jetson Xavier NX is closer to its big brother, the Jetson Xavier, when it comes to INT8 and FP16 computations. The Jetson Xavier has a bit more performance on the FP16 side at 11 TFLOPS. Both are much faster than the Jetson Nano or the earlier Jetson TX2. The Jetson TX2 does 1.3 FP16 TFLOPS and the Nano clocks in at 0.5 TFLOPS.
The Jetson Xavier NX supports all major ML platforms including TensorFlow, PyTorch, MxNet, Keras, and Caffe. Support for the ONNX runtime allows Microsoft ONNX models to work on the system.
Getting Started
Burning Ubuntu Linux on a 64-GB Micro-SD flash drive is the way to start. A number of images can be downloaded from Nvidia’s site, including a demo version that I started with. It actually takes a bit of time to download and program the flash drive, but the company was nice enough to send a kit that already had this done. You can also run inference benchmarks with the utility hosted at https://github.com/NVIDIA-AI-IOT/jetson_benchmarks.git
It also included the NVMe drive, which would not be part of the standard kit. It helps when runhing the demo or do any significant amount of work. A system can work without the NVMe drive if the model and application will fit in RAM and the Micro-SD card. All the benchmarks and individual demo containers work without the NVMe drive. It’s possible to run without the Micro-SD card by using just the NVMe drive.
The collection of tutorials, demos, and training materials from the company continues to grow and improve. The challenge is the learning curve. Demos work out of the box and they’re actually pretty easy to use with other data like images or data streams. There’s a whole section on training, although this works best on a PC that has a Nvidia GPU card like the GeForce RTX 2080 Ti.
It was relatively easy for me to get up and running on the training side since I had done it for the Jetson Xavier using the GeForce RTX 2080 Ti. It pays to get a general understanding of containers and Kubernetes used by Nvidia. The training demos are the same for all of the company’s platforms since most of this will run in the cloud or on a PC. The interference-engine results are run on systems like the Jetson Xavier NX.
Containers actually simplify the training. That along with pre-trained models make the demos easier to use as well as modify. Most work is done in C++ or Python; the plethora of Nvidia ML software works with most programming languages.
Running the Demo
The main demo highlights the capabilities of the Jetson Xavier NX (Fig. 4). Three of the windows analyze video streams. The top left tracks people. The bottom left tracks the limb movement of the people in frame while the bottom right tracks the eyes of the person in the frame.

The upper left demo window is interesting because it is interactive. It works with the USB headset that was included with my package. The machine-learning models involved “analyze voice input,” “determine what question might be posted,” “analyze the descriptive text that has been presented that you can ask about,” and deliver a response.
The interactive demo was impressive, but it was obviously a demo and you will have to perform additional training to meet your needs. For example, it understood that the National Football League was the NFL, but asking what the NFL was resulted in a null response. This wasn’t an issue of the analysis, rather it was the initial conversion from sound to the question. It was tuned to work with words rather than abbreviations or spelling.
The system could easily handle this type of issue; however, it needs to be trained accordingly. These kinds of limitations are understandable given that this is simply a demo and one that’s built on existing models. It highlights what type of jobs you might need to do to build on the demos or to build up a system from scratch. You can access resources used to train on custom language datasets at the NeMo conversational AI page: https://developer.nvidia.com/nvidia-nemo and NeMo Github: https://github.com/NVIDIA/NeMo
The demos and benchmarks do provide a way to gauge the capability of the Jetson Xavier NX and how it might fit into the application you may have in mind. It also highlights how many different ML models the system can handle simultaneously.
Keep in mind that these demos haven’t been optimized. They do put a load on the system, but there’s still a good bit of headroom. The demo shows that the module could be at the center of a very complex robot that recognizes people and their movements as well as interacts verbally.
Overall, moving from another Nvidia platform to the Jetson Xavier NX is a trivial exercise. Starting from scratch and checking out the demos and benchmarks is likewise an easy task. Scoping out capabilities using pretrained models and your own data is a bit harder, but not much.
Much more work will be required when delving into the API level, such as using the ISAAC Platform for Robotics and the matching SDK. Working with cuDNN or TensorRT to build your own models from scratch or tweaking existing models will also require lots more learning and effort. A multitude of tools like ISAAC GEMs include the 2D Skeleton Pose Estimation DNN, the Object Detection DNN, and the Motion Planning for Navigation and Manipulation, just to mention a few.
It’s remarkable what can be done with these tools. Still, they require a better understanding of machine learning as well as picking up the intricacies of dealing with any complex system like these tools.
About the Author

William G. Wong
Senior Content Director - Electronic Design and Microwaves & RF
I am Editor of Electronic Design focusing on embedded, software, and systems. As Senior Content Director, I also manage Microwaves & RF and I work with a great team of editors to provide engineers, programmers, developers and technical managers with interesting and useful articles and videos on a regular basis. Check out our free newsletters to see the latest content.
You can send press releases for new products for possible coverage on the website. I am also interested in receiving contributed articles for publishing on our website. Use our template and send to me along with a signed release form.
Check out my blog, AltEmbedded on Electronic Design, as well as his latest articles on this site that are listed below.
You can visit my social media via these links:
- AltEmbedded on Electronic Design
- Bill Wong on Facebook
- @AltEmbedded on Twitter
- Bill Wong on LinkedIn
I earned a Bachelor of Electrical Engineering at the Georgia Institute of Technology and a Masters in Computer Science from Rutgers University. I still do a bit of programming using everything from C and C++ to Rust and Ada/SPARK. I do a bit of PHP programming for Drupal websites. I have posted a few Drupal modules.
I still get a hand on software and electronic hardware. Some of this can be found on our Kit Close-Up video series. You can also see me on many of our TechXchange Talk videos. I am interested in a range of projects from robotics to artificial intelligence.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: