What’s the Difference Between Machine Learning Techniques?

Download this article as a .PDF
Artificial intelligence (AI), machine learning (ML), and robots are the sights and sounds of science fiction books and movies. Isaac Asimov’s Three Laws of Robotics, first introduced in the 1942 short story “Runaround,” became the backbone for his novel I, Robot and its film adaptation (Fig. 1). Although we are still far away from achieving what movie producers and sci-fi writers have envisioned, the state of AI and ML has progressed significantly. AI software has also been in use for decades but advances in ML, including the use of deep neural networks (DNNs), are making headlines in application areas like self-driving cars.

AI and ML research has been around since before computers even existed. Of course, they made practical creation and applications possible. The challenge has always been trying to keep up with the hype. Usually the programmers were unable to do so—hence, the many “failures” of AI.
In practical terms, AI essentially went underground, providing everything from expert systems to behavior-based vacuum cleaning robots like iRobot’s Roomba. The latter used an 8-bit microprocessor running a behavior-based rule system. Likewise, e-mail spam filters have been using Bayesian statistical techniques for decades, with varying levels of success.
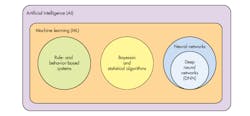
AI is a very large area of research of which machine learning is only one part (Fig. 2). The three examined here will be rule-based systems, Bayesian and statistical algorithms, and neural networks. These are presented in more detail later. There are more machine learning approaches not included in this list.
Learning Styles
In addition to machine learning algorithms, there is the style of machine learning that can be employed. Some algorithms are more amenable to certain styles that include:
- Supervised learning
- Unsupervised learning
- Semi-supervised learning
Supervised learning has labeled training data, such as an e-mail that has been marked as spam. The training process usually generates improved accuracy over time. It is used in algorithms like back propagated neural networks.
Unsupervised learning does not have labeled data, and the result of the training is often unknown. This approach can be used for creating general rules.
Semi-supervised learning includes a mixture of labeled and unlabeled data. This approach is often used when the structure of the data needs to be understood and categorized in addition to allowing predictions to be made.
Rule-based and Decision Tree Systems
Rule-based and decision tree algorithms are the easiest to understand. Rule-based systems consist of a collection of logical rules or conditions based on inputs. A rule is triggered when its conditions are met. The triggered rules may change internal state variables, as well as invoke actions.
For example, a robot may have a number of sensor inputs that detect obstacles by touch, as well as inputs about its movement. A rule might cause the robot to stop if it is moving and an obstacle sensor is triggered.
Rules can generate conflicting actions in which case some priority mechanism needs to be implemented. For example, one rule action may stop a robot, while another wants to change its direction.
A rule- or behavior-based system normally moves from one state to the next, applying all the rules to each state. Not all rules need to be examined depending upon the implementation. For example, rules may be grouped by inputs, and some only need to be examined if an input changes.
Decision trees are a structure rule-based system where each node in a tree has conditions that allow classification by refinement as an algorithm traverses the tree. There are many popular algorithms in this space, including Classification and Regression Tree (CART) and Chi-squared Automatic Interaction Detection (CHAID).
One advantage of these approaches is the ability to backtrack the logic process used to perform an action or reach a conclusion. This is very valuable for debugging, but it can also be useful in the learning process. There is also the possibility of examining rules for proofs.
Finally, a simplistic presentation of a rule-based system where condition A and B invoke action C overlooks the possibility, and often requirement, that the logic involved is binary in nature. Probability can be used in a rule system, as well.
Bayesian and Statistics
Bayes’ theorem describes the probability of a test result based on prior knowledge of conditions that might be related to the result. The theorem relates the chance that an event A happened given the indicator X, Pr(A|X), to the probability of event X given A, Pr(X|A). It allows for correction of measurement errors if the real probabilities are known. Of course, test results come with test probabilities.
There are a number of Bayesian algorithms based on the theorem, including Naive Byes and Bayesian Belief Network (BBN). Like differential equations, the theory can be hard to understand, but the application is usually straightforward. As noted earlier, Bayes algorithms have been utilized in applications like e-mail spam filtering, but they are not limited to this narrow application.
Bayes is only one method that employs probability and statistics. There are also regression algorithms that have been used in machine learning. Popular regression algorithms include Ordinary Least Squares Regression (OLSR), Multivariate Adaptive Regression Splines (MARS), and, of course, linear regression.
There are also variants on regression that are used in machine learning, such as ridge regression. It is also known as weight decay. It is also known as the Tikhonov-Miller method and the Phillips-Twomey method. The variants look to simplify the models to reduce system complexity that provide better generalization support.
Neural Networks
Artificial neural networks (ANNs) have been around for a long time, but their high computational requirements for complex networks has limited the use and experimentation until recently with multicore systems such as GPGPUs providing an economical platform for a variant called deep neural networks (DNNs).
Initially neural networks were of interest as a way of copying biological neural networks like the human brain. The brain is made up of neurons that are connected via an axon to synapse and dendrites on other neurons. The electrical signals from incoming signals are summed by the neuron. A result that exceeds a threshold sends a signal via the axon.
ANNs are built in a similar fashion, but using electronics or software. It takes many neurons to perform useful functions; the human brain has 100 billion. The trick to having something useful is the way the neurons are connected as well, as the weights associated with the neurons.
A basic neural network consists of a set of inputs and outputs with a hidden layer in between (Fig. 3). A DNN has multiple hidden layers. The networks may be the same logically, but the number of inputs, outputs, and hidden layers varies as well as other configuration options. Of course, the key to a system’s operation is the weights associated with the connections and nodes.
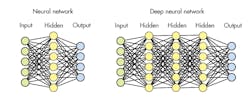
Neural networks require training to generate the weights used in the system. Systems can learn dynamically, but these tend to be more complex as training normally requires more computational horsepower than inference. Training uses a feedback system where an input is matched with outputs and the internal hidden layer weights are adjusted. This process requires more than just a few samples. A system with a large number of inputs like a photo image and a large number of sample sizes will often require a cluster or high end CPU and GPU to create a DNN configuration. On the flip side, a microcontroller may often be sufficient for some applications to utilize a DNN configuration to perform inferences in real time.
FPGAs and specially designed hardware to address neural networks are also available. There is even a hardware-based network on Intel’s compact 32-bit, Quark-based Curie system-on-chip. The advantages of this approach are lower power requirements and higher performance operation.
Google’s Tensor Processing Unit (TPU) is designed to crunch 8-bit matrices that are common in DNN computations (Fig. 4). Unlike number-crunching applications that require double precision floating point, DNN typically has weights that easily fit into 8-bits. The number of nodes tends to be more important than weight precision. The TPU will normally be used for training, but it could be used in the cloud for running lots of inferences.

DNNs have been used for a wide range of applications, from identifying items in an image to voice recognition. These can be done with conventional DNNs, but there are other configurations that provide additional functionality. One of these configurations is convolutional neural networks (CNN).
Convolutional neural networks are feed forward ANNs that may constrain the nodes in three dimensions. CNNs consist of a stack of layers that include a convolutional, a pooling, and a fully-connected layer.
The actual design and configuration of neural networks is a bit more complex than presented here, although training and using the results on an existing system are much simpler. This typically entails providing training input and then deploying the results where a system might be used to identify dogs in photos.
Part of the challenge of using neural networks is that they are essentially black boxes. This can be an advantage, but it essentially hides what is going on inside the system. Properly preprocessing input can also be critical to the success of using neural networks. Likewise, neural networks are not applicable to every application, but they do work very well for many applications.
Finally, it is possible to have a neural network provide feedback on part of the reasoning behind their results, but in general they do not provide this information. That may not be a problem if the accuracy of the inference is sufficient for the application, like being able to identify a dog within a picture at least 95% of the time. On the other hand, a financial advisor might want to know what the credit risk model looks like for recommendations coming out of a neural network.
Neural networks are making many applications practical and there are a lot of platforms, hardware, and software being brought into play. Electronic Design’s recent Embedded Revolution survey and white paper highlighted the number of embedded developers interested in AI (Fig. 5).
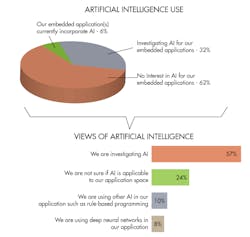
AI and ML have been used productively for decades, even though AI has been criticized for the hype associated with the technology. DNNs and CNNs are currently being hyped, but they too are delivering on the promise. The trick is to understand that there are many techniques that can be used for a particular application, and to do more research to find out which will work best.

About the Author

William G. Wong
Senior Content Director - Electronic Design and Microwaves & RF
I am Editor of Electronic Design focusing on embedded, software, and systems. As Senior Content Director, I also manage Microwaves & RF and I work with a great team of editors to provide engineers, programmers, developers and technical managers with interesting and useful articles and videos on a regular basis. Check out our free newsletters to see the latest content.
You can send press releases for new products for possible coverage on the website. I am also interested in receiving contributed articles for publishing on our website. Use our template and send to me along with a signed release form.
Check out my blog, AltEmbedded on Electronic Design, as well as his latest articles on this site that are listed below.
You can visit my social media via these links:
- AltEmbedded on Electronic Design
- Bill Wong on Facebook
- @AltEmbedded on Twitter
- Bill Wong on LinkedIn
I earned a Bachelor of Electrical Engineering at the Georgia Institute of Technology and a Masters in Computer Science from Rutgers University. I still do a bit of programming using everything from C and C++ to Rust and Ada/SPARK. I do a bit of PHP programming for Drupal websites. I have posted a few Drupal modules.
I still get a hand on software and electronic hardware. Some of this can be found on our Kit Close-Up video series. You can also see me on many of our TechXchange Talk videos. I am interested in a range of projects from robotics to artificial intelligence.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: