Bring Deep-Learning Inference to Embedded Applications

Download this article in PDF format.
Deep learning, probably the most advanced and challenging foundation of artificial intelligence (AI), is having a significant impact and influence on many applications, enabling products to behave intelligently like humans. Favored by the introduction of higher-performance computers and systems for parallel computing, deep learning has today become a reality, especially in the field of image recognition and classification, voice recognition, text analysis, and virtual assistants.
In recent years, we have witnessed the development of numerous models and architectures of neural networks (the basic structure on which deep learning is built), which led to the definition of data sets, ready to be used in real applications. Compared to traditional machine learning, deep learning can provide superior accuracy, greater versatility and use of big data.
Sponsored Resources:
- Create your first machine learning application
- Demystifying neural networks (video)
- Bringing the next evolution of machine learning to the edge
Overview of Deep Neural Networks
Models used in deep learning are based on deep neural networks (DNNs), which in turn can use different architectures, such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs). The choice of which architecture to use depends on the specific application: CNNs are particularly suited to image classification, while RNNs are normally used for text or speech recognition.
On a higher level, any deep-learning application can be divided into two phases: training and inference. Training is the process with which the neural network is trained by providing a real set of data and verifying the value (output) predicted by the network. At a practical level, this phase consists of tuning, as accurate as possible, the parameters used by the model. In the case of an image classifier, for example, the network is trained by providing tens of thousands (or more) different images.
After completing the training phase, the network can be installed in the field to perform the inference process, which is to apply the neural network previously trained to a set of real data to infer a result. For example, an image classifier can recognize many categories of everyday objects, animals, transport vehicles, and more.
Training a neural network is a very expensive operation from a computational point of view, and for this reason, it’s not normally performed on the target system. Rather, it’s done offline, using high-performance servers or PCs equipped with multi-threaded GPUs enabled for parallel computing. Note that real-time performance isn’t important at this stage. The inference phase is instead performed directly on the target system (in our case, we will refer to an embedded system) and, therefore, factors such as real-time performance and power absorption are fundamentally important.
Figure 1 shows the entire workflow, including the training and inference stages. It should be noted that before deploying a pre-trained neural network for inference on an embedded system, it’s sometimes necessary to perform a format conversion phase. That process could be needed, for instance, to convert some data from single or double floating-point representation to fixed-point format, achieving greater performance on an embedded system.
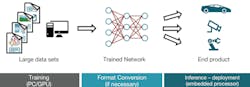
1. In a typical deep-learning development flow, training and inference are usually executed on different processing platforms.
Moreover, additional training data could be collected during the inference run and used to re-train the network model, improving the accuracy level.
Deep-Learning Deployment Workflow
The deployment of a pre-trained neural network on an embedded system that will execute the algorithms is known as inference. Note that choosing to execute deep-learning algorithms directly on an embedded system isn’t random. By shifting intelligence and decision-making capacity as close as possible to the sensors, the system is given greater autonomy and efficiency; response times and data bandwidth required for connection with the central server or the cloud are reduced; and contributions are made to limit power consumption.
The execution of deep-learning algorithms related to inference is a very onerous process from a computational point of view and requires very high bandwidth. The choice of which embedded system to use to implement deep-learning applications must fall on a processor that not only has a high processing capability, but is also able to acquire and process data in real time. Otherwise, the performance would fall below theoretical estimates. The processor must also be equipped with a fair amount of memory, enough to contain the model data and its parameters.
In Figure 2, we can observe the typical flow used to deploy a deep-learning application on a generic embedded system. The first phase of the cycle involves training the neural network model, performed by using one of the different deep-learning frameworks publicly available: Caffe, Keras, Tensorflow, PyTorch, or others. This phase is performed on desktop systems or the cloud, operating in offline mode without strict performance requirements.
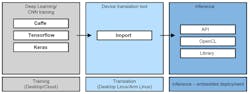
2. This is a development flow for deploying deep learning solutions on embedded systems.
The next phase is the translation—converting the network model into an internal format more suitable for use by the environment available on the target system. The third and final phase consists of the execution of the imported model on the embedded system, using the appropriate APIs and libraries.
Embedded Industrial-Grade Solutions
Oftentimes, a system-on-chip (SoC) is an excellent solution for implementing deep-learning applications on an embedded system. In addition to having a high processing capability, SoCs include numerous peripherals and components that can satisfy even the most stringent requirements of an embedded application. An example of a suitable SoC is the Sitara AM57x family of highly integrated processors developed by Texas Instruments (TI) (Fig. 3).
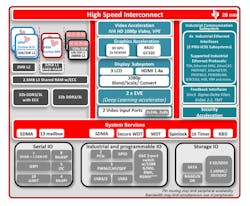
3. Shown is a block diagram of the Sitara AM5749 SoC.
Sitara processors provide industrial-level solutions based on single- or multi-core Arm processors. The AM57x family includes an Arm Cortex-A15 with an operating frequency up to 1.5 GHz and a rich set of dedicated hardware and peripherals for connectivity. Depending on the versions, the AM57x SoC includes one or two C66x digital signal processors (DSPs) capable of performing both deep-learning inference and traditional machine-vision algorithms. If even higher performance is required, two embedded vision engine (EVE) subsystems are available.
In addition, TI provides designers with the Linux-based TIDL (TI Deep Learning) software framework, which enables the execution of inference algorithms in real time, minimizing power absorption. The devices of the AM574x family combine video-acceleration and image-processing features with a set of highly integrated peripherals. The presence of up to two DSP units integrated into the SoC allows developers to keep the high-level control functions separate from the algorithms programmed on the C66x cores, reducing the complexity of the software application.
As can be seen in Figure 3, the SoC is completed by an accelerator module to support encryption and by numerous industrial-level communication interfaces. The AM5749 industrial development kit (IDK) helps simplify development. It can be used to evaluate the Sitara AM574x processor functionalities in several application areas, such as factory automation, drives, robotics, grid infrastructure, and more.
The AM5749 IDK card has six Ethernet ports, four of which can be used concurrently: 2x Gigabit Ethernet ports and 2x 10/100 Ethernet ports belonging to the PRU-ICSS subsystem. The wide availability of peripherals is completed by the presence of 2 GB of DDR3 RAM, a Profibus connection, EtherCAT and RS485 connectors, onboard eMMC, Mini PCIe, USB3, and HDMI connectors.
Deep-learning applications require embedded systems able to provide high computing capabilities, flexibility, availability of advanced peripherals, and high performance while operating in real time. Sitara SoCs in the TI AM57x family have all of these features, making them valid systems for the development, debug, and deployment of advanced applications in the field of artificial intelligence.
Sponsored Resources:
About the Author
Maurizio Di Paolo Emilio
Maurizio Di Paolo is the author of Microelectronic Circuit Design for Energy Harvesting Systems, a book covering the design of microelectronic circuits for energy harvesting, broadband energy conversion, and new methods and technologies for energy conversion.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: