CCIX: Cache Coherent Interconnect for Accelerators

The Cache Coherent Interconnect for Accelerators standard, or CCIX (pronounced “see 6”), is built on PCI Express (PCIe) to provide a chip-to-chip interconnect for high-speed hardware accelerators. It targets applications such as machine learning and FPGAs. The standard works with PCIe switches and in conjunction with the PCI Express protocol to provide a high-bandwidth, low-latency interconnect.
CCIX has just been announced, so hardware is in the future. It also means that processors will need to support it to take advantage of accelerators or even memory. More on memory later.
Originally PCIe was designed to be a peripheral interconnect that replaced the PCI bus, which had replaced the ISA bus. PCIe is a multilane, point-to-point interconnect that can scale from one lane to many. The top end is typically x16, and these connections are typically used to support GPUs. PCIe is utilized to move data between a peripheral and the host using memory-oriented, load/store functional semantics, but there’s no concept of cache coherency between the host and peripheral memory areas.
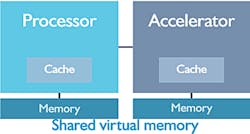
1. CCIX brings cache-coherent, shared memory to a system via PCI Express.
On the other hand, CCIX brings the idea of shared memory and cache coherency between the host processor and the accelerator/peripheral (Fig. 1). This support requires a different protocol, similar to those used in multiprocessor systems that provide a cache-coherent memory environment.
So why not use those connections to attach accelerators?
Most, probably all, of the multiprocessor cache interconnects are proprietary and tuned for the processors involved. It would be possible to attach additional devices, but then the support would be dedicated to a particular vendor. PCIe is a common interconnect on these systems and its switch-based expansion is ideal for supporting multiple CCIX accelerators. The CCIX architecture builds on this (Fig. 2).
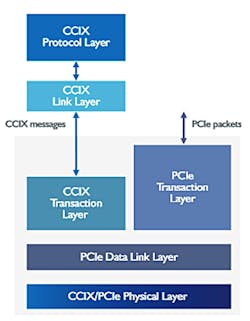
2. The CCIX protocol operates in parallel to the conventional PCI Express protocol using PCI Express data link and physical layers.
A CCIX accelerator supports both the CCIX transaction layer and the PCIe transaction layer. The latter is used for discovery and configuration of the accelerator, while the CCIX side handles the memory transactions. This allows standard PCIe support to be used to negotiate the speed and width of the PCIe connection. The PCIe side can also be employed to configure the accelerator.
CCIX supports a range of connection topologies (Fig. 3), but the underlying PCIe tree structure remains. The more complex system is where the CCIX support provides cache-coherent memory support across accelerator connections.
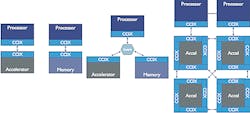
3. CCIX supports many different topologies, although there’s still the underlying PCIe tree structure.
So what kind of device is a CCIX accelerator? FPGAs are one type of device that fits in this slot. Memory is another. In all cases, the accelerator has some memory that’s shared with the overall system. This means that there’s one addressing scheme and all devices and hosts have access to all of the memory. This is cached NUMA architecture, so there will be delays between when an operation starts and finishes. Though keeping latency low is important, coherency is paramount.
The system essentially implements the heterogeneous system architecture (HSA) found in AMD’s Accelerated Processing Unit (APU) that combines its CPUs and GPUs into a common memory architecture. The difference is that CCIX is on built on an open standard, PCIe. There are numerous HSA implementations, but they are proprietary. HSA provides a common memory access environment like CCIX.
CCIX may eventually have a major impact on how systems are designed, including how memory is attached to the system. One challenge with memory on the motherboard is that it’s limited by the memory channels and slots. Off-board storage is usually behind a controller such as a PCIe-based NVMe device or a disk-oriented SAS or SATA device. CCIX would allow byte-addressable, cache-coherent memory to be added via PCIe that can be placed on PCIe cards, or via PCIe cable expansion to another board. The amount of memory that could be added is then limited by the PCIe switch and cabling system—not the size of the motherboard.
CCIX will likely have a significant effect on future GPU architectures as well as machine learning. This connection will allow vendors to deliver CCIX-compatible devices that can be used by any host that supports CCIX. Configurations will vary from boards that contain both the host and with one or more CCIX devices to expansion systems that already utilized PCIe. In fact, only the host and CCIX devices need to know about the CCIX protocol, since it’s transparent to any cabling or PCIe switches within the system.
CCIX has many adopters. It remains to be seen how this will play out in the long run, but FPGA implementations already exist.

About the Author

William G. Wong
Senior Content Director - Electronic Design and Microwaves & RF
I am Editor of Electronic Design focusing on embedded, software, and systems. As Senior Content Director, I also manage Microwaves & RF and I work with a great team of editors to provide engineers, programmers, developers and technical managers with interesting and useful articles and videos on a regular basis. Check out our free newsletters to see the latest content.
You can send press releases for new products for possible coverage on the website. I am also interested in receiving contributed articles for publishing on our website. Use our template and send to me along with a signed release form.
Check out my blog, AltEmbedded on Electronic Design, as well as his latest articles on this site that are listed below.
You can visit my social media via these links:
- AltEmbedded on Electronic Design
- Bill Wong on Facebook
- @AltEmbedded on Twitter
- Bill Wong on LinkedIn
I earned a Bachelor of Electrical Engineering at the Georgia Institute of Technology and a Masters in Computer Science from Rutgers University. I still do a bit of programming using everything from C and C++ to Rust and Ada/SPARK. I do a bit of PHP programming for Drupal websites. I have posted a few Drupal modules.
I still get a hand on software and electronic hardware. Some of this can be found on our Kit Close-Up video series. You can also see me on many of our TechXchange Talk videos. I am interested in a range of projects from robotics to artificial intelligence.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: