Crossbar Delivers ReRAM AI Accelerator

Lots of companies are vying for the top spot in machine-learning (ML) acceleration that entails lots of crunching of small numbers and weights. However, that’s not the only aspect of an ML model. At the end of this inference process, the system must still do the final lookup to deliver the matching information. This is often done by the host processor.
Crossbar’s ReRAM-based AI accelerator (Fig. 1) speeds this last step of the process, offloading the job from the host processor. Though the chore can be incorporated into an AI accelerator chip, it tends to be a bit different than processing the layers in an ML model. It’s also something that works quite well as a separate device, as Crossbar’s chip uses a simple SPI interface.

1. Crossbar’s SPI-based chip includes a bunch of ReRAM and a programmable comparator designed to handle matching chores at the end of a deep-neural-network model.
The accelerator can also be cascaded since it’s essentially a very advanced content-addressable memory (CAM). In fact, the device could be used for other applications even though it’s initially targeted at artificial-intelligence (AI) applications.
The advantage of ReRAM is its low power requirements and non-volatility. Most applications will simply load it up once and not change the memory contents unless there’s a system upgrade. The chip is fed data streams that are matched, and the results are returned.
The chip can be configured to handle different operations and data lengths, but it’s not really a programmable device. This is similar to most ML accelerators that do the heavy lifting. The models can change; however, this is more of a configurability aspect rather than a device that runs an arbitrary program.
A single chip is designed to handle billions of object lookups/s (OLUPS) that puts the typical CPU to shame while using a fraction of the power needed to perform similar operations (Fig. 2). The chip fares better with smaller object lengths, since it can perform a fixed number of comparisons. But, the number it can do simultaneously is based on the number of bits involved. Fewer bits means more objects comparisons. The typical length in ML applications these days is about 128 bits.
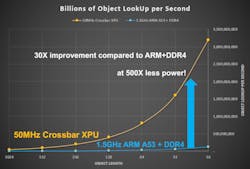
2. The accelerator can deliver significant object lookup improvements while consuming less power than processor-based solutions.
ReRAM operation is fairly simple, and its non-volatile nature is an advantage in this type of application. Programming a bit involves the creation of a conductive filament between the cell’s electrodes (Fig. 3). This is done via electro-migration of ions.
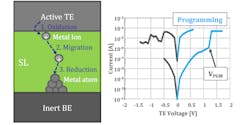
3. ReRAM programming creates a filament between electrodes using electro-migration of ions through the switching layer.
The erasure of a bit (Fig. 4) reverses the process and removes the filament. As a result, the resistivity of the cell goes up.
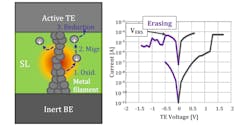
4. Erasing a ReRAM cell is accomplished by reducing the ions breaking the conductive path.
The chip uses a 66-MHz serial interface. The system provides deterministic operation supporting object lengths from 16 bits to 1 kbit. It handles 1K to 64K objects/macro that can measure the Manhattan or cosine distance between the memory contents and an incoming object. The accelerator is capable of performing 3 billion OLUPS or 53 billion OLU/W. It supports classification systems like kNN, RBF, CBIR, and Softmax. Crossbar has been providing select customers with a USB dongle that contains one of the chips.

About the Author

William G. Wong
Senior Content Director - Electronic Design and Microwaves & RF
I am Editor of Electronic Design focusing on embedded, software, and systems. As Senior Content Director, I also manage Microwaves & RF and I work with a great team of editors to provide engineers, programmers, developers and technical managers with interesting and useful articles and videos on a regular basis. Check out our free newsletters to see the latest content.
You can send press releases for new products for possible coverage on the website. I am also interested in receiving contributed articles for publishing on our website. Use our template and send to me along with a signed release form.
Check out my blog, AltEmbedded on Electronic Design, as well as his latest articles on this site that are listed below.
You can visit my social media via these links:
- AltEmbedded on Electronic Design
- Bill Wong on Facebook
- @AltEmbedded on Twitter
- Bill Wong on LinkedIn
I earned a Bachelor of Electrical Engineering at the Georgia Institute of Technology and a Masters in Computer Science from Rutgers University. I still do a bit of programming using everything from C and C++ to Rust and Ada/SPARK. I do a bit of PHP programming for Drupal websites. I have posted a few Drupal modules.
I still get a hand on software and electronic hardware. Some of this can be found on our Kit Close-Up video series. You can also see me on many of our TechXchange Talk videos. I am interested in a range of projects from robotics to artificial intelligence.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: