Habana Enters Machine-Learning Derby with Goya Platform

Habana Labs has emerged onto the machine-learning (ML) stage with its Goya HL-1000 processor (Fig. 1). The x16 PCI Express Gen 4 board has a 200-W TDP and comes with 16 GB of DDR4 ECC DRAM. It’s aimed at ML inference chores with a forthcoming Gaudi processor targeting ML training. In the meantime, Goya can take advantage of trained deep-neural-network (DNN) models to handle inference.

1. Habana Labs’ Goya HL-1000 is based on a VLIW SIMD vector core with Tensor addressing support.
The HL-1000 is designed to manage high-throughput chores with low latency (Fig. 2). Its performance scales well, handling thousands of images per second for standard ML test applications such as ResNet-50. It can process this model at over 15,000 images/s with a 1.3-ms latency while dissipating only 100 W of power. Typical latency in the industry at this point sits at around 7 ms. Keeping power requirements low in an enterprise setting with many boards is critical to minimizing overall system costs. Habana delivers passive as well as active cooled models.
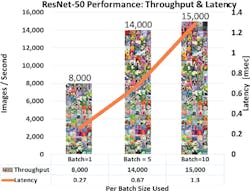
2. The Goya’s performance and low latency are impressive.
The architecture is based on a Tensor Processing Core (TPC) that’s fully programmable in C and C++ using an LLVM-based compiler. The HL-1000 processor is built on a cluster of eight TPCs (Fig. 3). As with most ML systems, the processor includes hardware general-matrix-multiply (GEMM) acceleration. There are special functions in dedicated hardware along with Tensor addressing and latency hiding support.

3. Multiple, fully programmable Habana Tensor Processing Cores populate the Goya HL-1000.
The system exploits on-die memory that’s managed by software along with centralized, programmable DMAs to deliver predictable, low-latency operation. Although targeted at TensorFlow applications, it works equally well with other framework models. The TPC handles 8-, 16- and 32-bit integers as well as 32-bit floating point.
Habana’s SynapseAI software transforms standard AI models to applications that run on the HL-1000 (Fig. 4). The tools can import models from MXNet, Caffe 2, Microsoft Cognitive Toolkit, PyTorch, and Open Neural Network Exchange Format (ONNX). It can also utilize user-supplied libraries; a Python-based front end helps automate system operation. The SynapseAI runtime manages resources on the processor. IDE support includes a debugger and simulator. Among its tools are real-time tracing and performance analysis that can be graphically presented.
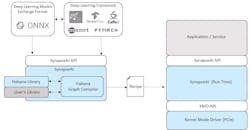
4. Habana’s SynapseAI software transforms standard AI models to applications that run on the HL-1000.
Habana will have lots of competition in this space. Thus, its high performance, lower power, and low-latency characteristics will be key factors in staying ahead of the pack.

About the Author

William G. Wong
Senior Content Director - Electronic Design and Microwaves & RF
I am Editor of Electronic Design focusing on embedded, software, and systems. As Senior Content Director, I also manage Microwaves & RF and I work with a great team of editors to provide engineers, programmers, developers and technical managers with interesting and useful articles and videos on a regular basis. Check out our free newsletters to see the latest content.
You can send press releases for new products for possible coverage on the website. I am also interested in receiving contributed articles for publishing on our website. Use our template and send to me along with a signed release form.
Check out my blog, AltEmbedded on Electronic Design, as well as his latest articles on this site that are listed below.
You can visit my social media via these links:
- AltEmbedded on Electronic Design
- Bill Wong on Facebook
- @AltEmbedded on Twitter
- Bill Wong on LinkedIn
I earned a Bachelor of Electrical Engineering at the Georgia Institute of Technology and a Masters in Computer Science from Rutgers University. I still do a bit of programming using everything from C and C++ to Rust and Ada/SPARK. I do a bit of PHP programming for Drupal websites. I have posted a few Drupal modules.
I still get a hand on software and electronic hardware. Some of this can be found on our Kit Close-Up video series. You can also see me on many of our TechXchange Talk videos. I am interested in a range of projects from robotics to artificial intelligence.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: