How Companies Can Help Engineers and Scientists with Machine Learning

Machine learning is increasingly influencing how we engage with the objects around us, from fitness trackers and digital assistants to our TVs. With mounting pressure to make “smart” consumer products, tech companies are looking to their engineering teams to implement machine-learning algorithms into a growing number of new devices. However, because it’s still largely an emerging technology, many engineers lack the education and training needed to develop and productionize machine-learning algorithms.
I talked with Seth Deland, Applications Product Manager for Data Analytics at MathWorks, about the challenges engineers and scientists encounter when beginning to work with machine-learning algorithms and models, and what companies can do to ensure their engineering teams are successful (Fig. 1).

1. Machine-learning applications have the potential to make an evolutionary impact on numerous industries. (© 1984–2019 MathWorks)
To begin, why is machine learning so important?
While it’s true that machine learning seems to be the engineering industry’s latest buzzword, the technology’s potential is worthy of companies’ time and resources. At a base level, machine learning teaches computers to learn from experience. The algorithms adaptively improve their performance as the number of available data samples increases, which gives models the ability to “learn.”
The ever-growing volume of data collected and analyzed by companies is driving machine learning’s potential within applications ranging from autonomous vehicles and automated industrial equipment, to smartphones and video-streaming services. These applications are becoming a dominant force in the lives of the everyday consumer.
What do engineers and scientists with minimal experience working with machine-learning algorithms need to know before getting started?
Engineers and scientists need to know answers to three questions before they can start building a machine-learning model: What kind of data are they working with? What insights do they hope to derive? How will those insights be applied?
The answers to these questions will determine their path forward—specifically whether they should use supervised or unsupervised learning approaches, and which types of algorithms are suitable to investigate (Fig. 2).
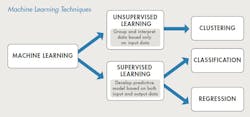
2. One of the first questions engineers and scientists must answer when building a machine-learning model is whether to use supervised or unsupervised learning. (© 1984–2019 MathWorks)
Supervised learning trains a model on known input and output data so it can then be used to predict future outputs. An example of supervised learning is a smartphone health-monitoring app that classifies the user’s daily activities (sitting, standing, walking, running, etc.) based on input data from smartphone motion sensors. Supervised learning is powerful because it provides a path to predict outputs or states that cannot be directly measured or are expensive to measure. However, in order to train a supervised machine-learning model, you need labeled examples. In the smartphone example, this meant collecting data for users explicitly performing each of the activities.
Unsupervised learning is used to draw inferences from data sets consisting of input data without labeled responses. It’s useful for uncovering patterns in data, such as identifying clusters of data points that have similar characteristics. Unsupervised learning is useful because it helps uncover patterns in high-dimensional datasets. An example of unsupervised learning is segmenting color spaces in medical images, which helps pathologists distinguish different tissue types.
If we know the answers to these three questions and the type of machine learning to implement, what’s the process look like for developing algorithms and training a model?
Even though the workflow I’m about to lay out is linear, the process is not. There will be challenges and a lot of trial and error to refine algorithms and models to achieve the highest possible accuracy.
Let’s use the smartphone health-monitoring app as an example. First, get the data. To do this, users can sit holding the phone, log the sensor data, and store it. They can then repeat this for each action they want to classify (walking, running, etc.). Second, preprocess the data. Engineers and scientists can use a data-analysis tool, like MATLAB, to import and plot the data and perform data-cleaning tasks such as identifying and removing outliers. For example, any incidental movements while holding the phone would be removed.
Third, the raw data must be converted into information that can be used by machine-learning algorithm. The engineer would look at different transformations that are applicable to the data to help distinguish between the outputs. For the health-monitoring app, this could entail transforming the data into the frequency domain, as low-frequency data may indicate walking and high-frequency data may indicate running.
Fourth, build and train the model. There are many options for models and algorithms—decision trees, K-nearest neighbors, support vector machines, and many more. Through trial and error, engineers can determine which model and algorithm most accurately classifies the user’s physical activities. They will likely need to try many different approaches to find the best model and gain confidence in their results (Fig. 3).
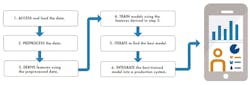
3. Shown is a typical workflow for building a machine-learning model. (© 1984–2019 MathWorks)
Again, the goal is to achieve the highest level of consistent accuracy in classifying between sitting, walking, running, and more. Trial and error will be part of the process, but by following this workflow and iterating on it to improve results, suitable models can be developed even by those with little prior knowledge of machine learning.
You mentioned challenges. Is there a standout challenge engineers and scientists will encounter when it comes to machine learning?
One of the biggest challenges for machine-learning novices involves working with unfamiliar tools or programming languages. Companies can help them overcome this challenge by providing their engineering teams with scalable software tools, like MATLAB, that enable engineers and scientists to work in familiar environments. These tools have point-and-click applications that give users a comfortable way to learn about machine learning, as well as a programming language that gives them the flexibility they need to customize the model for their application. Such tools can accelerate training and enable incumbent engineering teams to quickly develop their own machine-learning algorithms and models.

About the Author

William G. Wong
Senior Content Director - Electronic Design and Microwaves & RF
I am Editor of Electronic Design focusing on embedded, software, and systems. As Senior Content Director, I also manage Microwaves & RF and I work with a great team of editors to provide engineers, programmers, developers and technical managers with interesting and useful articles and videos on a regular basis. Check out our free newsletters to see the latest content.
You can send press releases for new products for possible coverage on the website. I am also interested in receiving contributed articles for publishing on our website. Use our template and send to me along with a signed release form.
Check out my blog, AltEmbedded on Electronic Design, as well as his latest articles on this site that are listed below.
You can visit my social media via these links:
- AltEmbedded on Electronic Design
- Bill Wong on Facebook
- @AltEmbedded on Twitter
- Bill Wong on LinkedIn
I earned a Bachelor of Electrical Engineering at the Georgia Institute of Technology and a Masters in Computer Science from Rutgers University. I still do a bit of programming using everything from C and C++ to Rust and Ada/SPARK. I do a bit of PHP programming for Drupal websites. I have posted a few Drupal modules.
I still get a hand on software and electronic hardware. Some of this can be found on our Kit Close-Up video series. You can also see me on many of our TechXchange Talk videos. I am interested in a range of projects from robotics to artificial intelligence.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: