Inference Chips Benefit from a Concurrent Design Approach

Today, all inference accelerators are programmable for the simple reason that every customer believes their model will continue to evolve over time. They know this programmability will allow them to take advantage of enhancements in the future, something that would not be possible with a hard-wired accelerator.
However, customers want this programmability such that they can get maximum throughput for a certain cost and a certain amount of power. This means they have to use the hardware very efficiently. The only way to do this is to design the software in parallel with the hardware to make sure they work together very well to achieve the maximum throughput.
Pieces of the Puzzle
To understand the importance of software in an accelerator, let’s look at the pieces that make up both the hardware and software in a typical inference chip. On the hardware side, every accelerator must have certain basics (see table). What distinguishes a given inference chip is how these pieces are put together by its designers at the various chip vendors.
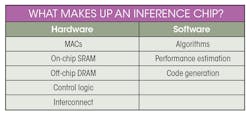
For a company that’s going to run YOLOv3, it takes about 300 billion multiply-accumulates (MACs) to process a single 2-Mpixel image. That’s a lot of MACs. However, the MACs can be grouped in many ways, such as by systolic arrays, one-dimensional systolic arrays, or even individual MACs. The chip also must have on-chip SRAM, because a lot of intermediate activations have to be written, stored, and recycled. And, unless the chip is really big, it’s going to need off-chip DRAM.
Any chip that is relatively economical outside the data center is going to be small enough that it needs DRAM to run models such as YOLOv3. However, different chips will have different amounts of memory, and how they organize that memory will vary. For example, they may couple the memory closely to the compute units in a distributed fashion, or they may choose to have a single large block.
Inference accelerators also need control logic, because something needs to orchestrate the flow of data through the chip and decide what to do, how long to do it, and when to stop. The interconnect is the plumbing in the chip that moves data from memory to compute and back again in a manner that efficiently feeds the MACs.
When you look at the hardware, most people focus on the metric of teraoperations per second (TOPS); rarely do they home in on the software. However, without software, all of these hardware pieces do nothing. You need software for anything programmable to run.
The input to the software is typically a neural-network model. To run properly, a chip needs an algorithm that tells it how to orchestrate the resources feeding that model , so that it’s kept as busy as possible while completing the computation as fast as it can and with minimal power consumption. Another critical software piece is performance estimation. When you run the algorithms, it’s important to know how long it will take to process the frame for that model and image size. The last step is to then generate the code that gets loaded onto the processor to run it.
When Software Comes Last
One of the biggest problems today is that companies find themselves with an inference chip, and while this chip might have lots of MACs and tons of memory, the company can’t seem to get enough throughput out of it. Almost invariably, the problem is that the software work was done after the hardware was built.
That’s why it’s critical that the software be designed in parallel with the hardware, and even more so when you’re designing brand-new hardware such as an inference accelerator—a new type of chip running models that change rapidly. The multitude of architectural tradeoffs demand that designers work with both the hardware and software, going back and forth between them—and this must happen early in the design cycle.
A Typical Case Study
Neural-network models are modular because each layer is processed rather independently. A given layer takes the activations outputted from the previous layer and processes them, generating a new set of activations. As they repeat that cycle, each layer performs a different operation and each operation is a different module that uses resources in a different way. There are also many different types of neural networks, because each uses the hardware and software differently.
When we at Flex Logix undertook development of our chip architecture, customers asked if we could optimize our embedded FPGA to be used for inference. As we began studying models, one of the first things we did was build a performance-estimation model to determine how different amounts of memory, MACs, and DRAM would impact relevant throughput as well as die size.
We initially worked with ResNet-50, which was the popular model at the time. But we quickly realized the images in ResNet-50 were far too small, particularly when they’re being utilized in critical applications such as autonomous driving. Not being able to see an image clearly in that scenario could be disastrous. For such applications, and actually for most applications, they must be able to process megapixel images.
Today, one of the highest-volume applications for inference chips is objective detection and recognition. Flex Logix has built such a chip that’s adept at megapixel processing using YOLOv3. Through tradeoffs, we were able to build a chip that had relatively small amounts of MACs, small amounts of SRAM, and just a single DRAM. Yet this chip, measuring 50 mm2, performs on par with Tesla’s V4 chip, which is 7X larger and far more costly.
We learned that cooperation between software and hardware teams is critical throughout the entire chip-design process—from performance estimation to building the full compiler, as well as when generating code. After the chip designer has completed the hardware’s register-transfer-level (RTL) design, the only way to verify the chip RTL at the top level is to run entire layers of models through the chip with megapixel images. To do so, one must be able to generate all of the code and bit streams that control the device, which can only be done when software and hardware teams work closely together.
Today, customer models are neural networks and they come in Open Neural Network Exchange (ONNX ) or TensorFlow Lite open-source formats. Software takes these neural networks and applies algorithms to configure the interconnect and write state machines that control the movement of data within the chip. This is done in RTL. The front end of the hardware is also written in RTL. Thus, critically, the engineering team that’s writing the front-end design is working at the same level of design abstraction, and writing in similar languages, as the people writing the software.
Software Will Always be Important
Moving forward, hardware designers seeking future improvements will study how the software is evolving and how the emerging models are shifting in a certain direction. Chip designers need to make changes as needed; meanwhile, compilers and algorithms can be improved over time to better utilize the hardware.
In the future, companies will approach chip designers with very challenging models in hopes of attaining new heights in performance that may not be possible with existing solutions. Projects that haven’t taken a concurrent approach to hardware and software design from their inception will fail to deliver the throughput needed for these models. They also will be unable to improve algorithms over time to extend the hardware’s ability to handle the many different classes of models that we expect to emerge in the future.
Geoff Tate is CEO of Flex Logix Inc.
About the Author
Geoff Tate
CEO and Co-Founder, Flex Logix Inc.
Geoff Tate is CEO and co-founder of Flex Logix, Inc. Earlier in his career, he was the founding CEO of Rambus where he and two PhD co-founders grew the company from four people to an IPO and a $2 billion market cap by 2005. Prior to Rambus, Tate worked for more than a decade at AMD where he was Senior VP, Microprocessors and Logic with more than 500 direct reports.
Before joining Flex Logix, Tate ran a solar company and served on several high-tech company boards. He currently is a board member of MRAM maker Everspin. Originally from Edmonton, Canada, Tate holds a Bachelor of Science in Computer Science from the University of Alberta and an MBA from Harvard University. He also completed his MSEE (coursework) at Santa Clara University.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: