Revving Up Machine-Learning Inference

What you’ll learn
- What’s the difference between TensorFlow and TensorRT?
- What are the performance improvements in TensorRT 8?
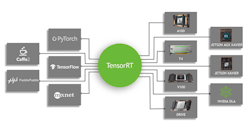
NVIDIA has just released TensorRT 8, which supports the open-source TensorFlow platform originally developed at Google (see figure). TensorRT 8 compiles and optimizes TensorFlow models for NVIDIA hardware, taking advantage of features found on those platforms. For example, the company’s Ampere GPU supports a feature called fine-grain sparsity.
Sparsity is a technique that helps reduce the size of an encoded value. In particular, the weights used in machine-learning models can benefit from reducing the size of the values. They require less space and computations can be more efficient. The trick is to encode the values for a large majority that are contained in the translated version. Likewise, the math used on the values needs to take the encoding into account.
TensorRT 8 provides substantial performance gains, including improved accuracy versus other techniques. For example, the quantization aware training (QAT) support can double the accuracy. This and other transformation optimizations allow TensorRT 8 to double the performance of many models compared to results provided by its older sibling, TensorRT 7.
TensorRT 8 only offers fine-grain sparsity support for newer hardware like the Ampere GPU. Nonetheless, the system still enhances performance for other NVIDIA hardware that doesn’t have hardware sparsity support. The improvements just aren’t as dramatic.
On the other hand, certain models can gain even better performance using TensorRT8. This includes Bidirectional Encoder Representations from Transformers (BERT). BERT is a transformer-based machine-learning technique that’s used for natural-language processing pre-training. Some systems see a performance increase of two orders of magnitude. Thus, analysis using a BERT-Large model takes only 1.2 ms, allowing for real-time response to natural-language queries.
“AI models are growing exponentially more complex, and worldwide demand is surging for real-time applications that use AI. That makes it imperative for enterprises to deploy state-of-the-art inferencing solutions,” said Greg Estes, vice president of developer programs at NVIDIA. “The latest version of TensorRT introduces new capabilities that enable companies to deliver conversational AI applications to their customers with a level of quality and responsiveness that was never before possible.”
About the Author

William G. Wong
Senior Content Director - Electronic Design and Microwaves & RF
I am Editor of Electronic Design focusing on embedded, software, and systems. As Senior Content Director, I also manage Microwaves & RF and I work with a great team of editors to provide engineers, programmers, developers and technical managers with interesting and useful articles and videos on a regular basis. Check out our free newsletters to see the latest content.
You can send press releases for new products for possible coverage on the website. I am also interested in receiving contributed articles for publishing on our website. Use our template and send to me along with a signed release form.
Check out my blog, AltEmbedded on Electronic Design, as well as his latest articles on this site that are listed below.
You can visit my social media via these links:
- AltEmbedded on Electronic Design
- Bill Wong on Facebook
- @AltEmbedded on Twitter
- Bill Wong on LinkedIn
I earned a Bachelor of Electrical Engineering at the Georgia Institute of Technology and a Masters in Computer Science from Rutgers University. I still do a bit of programming using everything from C and C++ to Rust and Ada/SPARK. I do a bit of PHP programming for Drupal websites. I have posted a few Drupal modules.
I still get a hand on software and electronic hardware. Some of this can be found on our Kit Close-Up video series. You can also see me on many of our TechXchange Talk videos. I am interested in a range of projects from robotics to artificial intelligence.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: