11 Myths About In-Memory Database Systems

What you’ll learn:
- Where in-memory databases are used (spoiler: everywhere!).
- Suitability of in-memory databases for microcontrollers.
- Risks and mitigation of data loss.
- How an in-memory database is different than database cache.
Steven Graves, president of McObject, debunks some of the myths and misinformation surrounding in-memory database technology.
1. In-memory databases will not fit on a microcontroller.
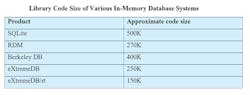
In-memory databases can and do fit on microcontrollers in a wide range of application domains, such as industrial automation and transportation. In-memory database systems can be quite compact (under 500K code size) and, as mentioned in the answer to Myth #3 below, use the available memory quite frugally. A microcontroller in an embedded system often doesn’t manage a lot of data (and so doesn’t require a lot of memory), but the data is still disparate and related, so it therefore benefits from database technology.
For reference, the table below shows some publicly available code-size estimates for a few different in-memory database systems. Keep in mind that code size depends on the target CPU, compiler, and compiler optimizations employed.
2. In-memory databases don’t scale.
There are two dimensions to scalability: horizontal and vertical. Vertical scalability means getting a bigger server to handle a growing database. While RAM is certainly more expensive than other storage media, it’s not uncommon to see servers with terabytes of memory. Ipso facto, in-memory databases can scale vertically into the terabytes.
Horizontal scalability means the ability to shard/partition a database and spread it over multiple servers while still treating the federation as a single logical database. This applies equally to in-memory databases.
3. In-memory databases can lose your data (aren’t persistent).
In the absence of any mitigating factors, an in-memory database does “go away” when the process is terminated, or the system is rebooted. However, this can be solved in several ways:
- Snapshot the database before shutdown (and reload it after the next startup).
- Combine #1 with transaction logging to persistent media to protect against an abnormal termination.
- Use NVDIMM (RAM coupled with flash, a supercapacitor, and firmware to dump the RAM to flash on power loss and copy back to RAM on restart).
- Use persistent memory a la Intel’s Optane.
4. In-memory databases are the same as putting the database in a RAM drive.
False. A true in-memory database is optimized to be such. A persistent database is optimized to be such. These optimizations are diametrically opposed. An in-memory database is optimized to minimize CPU cycles (after all, you use an in-memory database because you want maximum speed), and to minimize the amount of space required to store any given amount of data. Conversely, a persistent database will use extra CPU cycles (e.g., by maintaining a cache) and space (by storing indexed data in the index structures) to minimize I/O because I/O is the slowest operation.
5. In-memory databases are the same as caching 100% of a conventional database.
Also false. Caching 100% of a conventional database will improve read (query) performance but will do nothing to improve insert/update/delete performance. And, maintaining a cache means having extra logic that a persistent database needs for a least-recently-used (LRU) index—an index to know if a requested page is in cache, or not (a DBMS doesn’t “know” that you’re caching the entire database; it needs to carry out this logic regardless), marking pages as “dirty” and so on.
6. In-memory databases are only suitable for very few, and specific, use cases.
In-memory databases are utilized for almost any workload you can imagine. Common applications include consumer electronics, industrial automation, network/telecom infrastructure equipment, financial technology, autonomous vehicles (ground/sea/air), avionics, and more.
7. In-memory databases are more susceptible to corruption.
In-memory databases are no more susceptible to corruption than any other type of database, and perhaps less so. Databases on persistent media can be “scribbled on” by rogue or malevolent processes, corrupting them. Operating systems offer more protection to memory than file systems provide to files.
8. An in-memory database will crash if it becomes full.
A well-written in-memory database will handle an out-of-memory condition as gracefully as a well-written persistent database handles a disk becoming full. Ideally, an in-memory database doesn’t allocate memory dynamically; rather, memory is allocated up-front and memory required for the in-memory database is doled out from that initial memory pool as needed.
Such an approach eliminates the possibility of allocating more memory than that permitted by user/system limits. It also eliminates the possibility of a memory leak affecting other parts of a system that an in-memory database operates in.
9. An in-memory database can consume all system memory.
A well-written database shouldn’t allocate memory dynamically for storage space (general-purpose heap could be a different story). Storage space (memory) for an in-memory database should be allocated one time on startup. If it fills up, the in-memory database system should report that fact and allow the application to determine next steps (prune some data, allocate additional memory, graceful shutdown, etc.).
10. In-memory databases are very fast, therefore suitable for real-time systems.
Real-time systems break down into two classes: soft real-time and hard real-time. In-memory databases can be suitable for soft real-time systems. Hard real-time systems require more than just speed—they require determinism. That, in turn, requires a time-cognizant database system, i.e., one that’s aware of, and can manage, real-time constraints (deadlines). It also has become fashionable to advertise in-memory databases as “real-time,” which has become synonymous with “real fast” but has no relationship to soft or hard real-time systems.
11. It doesn’t make sense to have an in-memory client/server database.
Refer to Myth #1. An in-memory database that’s sharded/partitioned practically requires a client/server architecture. Therefore, client application(s) can be isolated from the physical topology of the distributed system, including any changes to it (e.g., to scale it horizontally).
About the Author
Steven Graves
President, McObject
Steven Graves co-founded McObject in 2001. As the company’s president and CEO, he has both spearheaded McObject’s growth and helped the company attain its goal of providing embedded database technology that makes embedded systems smarter, more reliable, and more cost-effective to develop and maintain.
Prior to McObject, Mr. Graves was president and chairman of Centura Solutions Corporation, and vice president of worldwide consulting for Centura Software Corporation; he also served as president and chief operating officer of Raima Corporation. He’s a member of the advisory board for the University of Washington’s certificate program in Embedded and Real Time Systems Programming.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: