What’s the Difference Between Linux EXT, XFS, and BTRFS Filesystems?

Download the PDF of this article.
Linux supports a range of file systems, including ones used on other operating systems such as Windows FAT and NTFS. Those may be supported by embedded developers but normally a Linux file system like the 4 extended file system (ext4), XFS, or BTRFS will be used for most storage partitions. Understanding the options can help in selecting the right file system for an application.
The Linux file systems covered here include ones that would typically be used in embedded applications. There is also a class of clustered file systems designed for multi-node environments like Red Hat’s Global File System (GFS), GlusterFS, and Lustre.
We start with an overview of features, followed by a more detailed description of each.
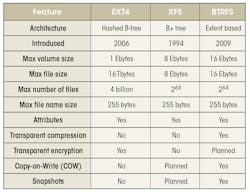
The Extended File System
The Extended File System is actually a family that currently includes ext2, ext3, and ext4. It was the de facto standard for many years and it is still commonly used.
The ext2 file system was introduced in 1993 and supported Linux features like symbolic links and long file names. It can now handle volumes up to 32 Tbytes and file sizes up to 2 Tbytes. It is still used on many flash-based storage systems along with the FAT file system. It lacks the journal system found in ext3 and ext4.
The ext2 file allocation uses a multilevel hierarchy that provides fast access for smaller files (Fig. 1). The first dozen links in a file’s inode reference data blocks for the start of the file. Larger files add a single- and then double-level reference before data is accessible.
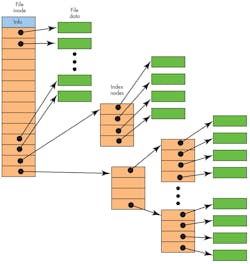
1. The ext2 file system has a file definition (inode) that includes details about the file and links to data nodes with links to index nodes at the end. Small files would not use those.
An ext2 file system can be upgraded to ext3. The ext3 file system adds journaling, online file system growth capabilities, and an HTree indexing system for larger directories. If these features are not used then the ext3 file system matches an ext2 file system.
The ext3 file system does not include newer features like dynamic inode allocation and extents. The advantage is that the file system metadata is in fixed, known locations. There are redundant data structures in place to improve recoverability.
The journaling system for ext3 operates in one of three modes: journal (low risk), ordered (medium risk) and writeback (high risk). The first mode writes metadata and file contents to the journal, effectively saving the information twice. The ordered mode only puts the metadata in the journal and writes the file data exclusively to the file system data structure before the journal entry is committed. The writeback mode makes no guarantee as to when the metadata is committed. This is faster, but affects what can be recovered if a crash occurs.
The ext4 file system adds a number of major features, including file systems as large as 1 Ebyte and files up to 16 Tbytes. Extents replace the traditional block-mapping mechanism used with its earlier siblings. Even though it’s backward compatible, an ext4 file system cannot be mounted as an ext3 file system if newer features like the extent support are enabled.
The ext4 file system supports persistent pre-allocation—useful for applications like streaming media where sequential access performance is paramount. It also supports delayed allocation. The journals are checksummed for improved reliability, and there is a multiblock allocator. File system checking is significantly faster.
The ext4 system was built on the existing infrastructure, making certain features difficult to implement. It does not currently support the secure deletion file attribute. Newer file systems like XFS and BTRFS offer improvements that may or may not be amenable to certain applications.
XFS
XFS is a 64-bit journaling file system initially developed by Silicon Graphics. It is designed for parallel I/O based on allocation groups. This allows a system to scale based on the number of I/O threads and file system bandwidth. It is designed to span multiple storage devices. XFS includes its own volume manager.
It uses B+ trees for the directories and file allocation. The file system is partitioned into allocation groups (AG) that have their own allocation and free space management. Files are allocated used extents (Fig. 2) that use contiguous blocks when possible. The number of extents usually grows as a file’s size increases. XFS can handle variable block sizes, sparse files, and snapshots.
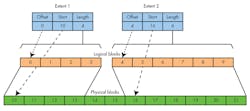
2. Extent-based allocation uses larger continuous blocks for more efficient storage and access. Extents are referenced via a B+ tree.
XFS uses a logging system to track updates. This process can be synchronous or asynchronous with respect to file updates. The former is more-or-less prone to problems when errors occur, but the latter is faster and more efficient when multiple tasks and files are involved. The log can be store on a separate device to further improve reliability. XFS has Data Migration API (DMAPI) that can take advantage of hierarchical storage management services.
One notable feature of XFS is Guaranteed Rate I/O (GRIO). This allows applications to reserve bandwidth. This can be very useful in embedded applications. The file system calculates the available performance and adjusts its operation according to the existing reservations.
BTRFS
The BTRFS file system is based on a copy-on-write (COW) B-tree. According to Chris Mason, the principal BTRFS author, its goal was “to let Linux scale for the storage that will be available. Scaling is not just about addressing the storage but also means being able to administer and to manage it with a clean interface that lets people see what’s being used and makes it more reliable.”
BTRFS is also an extent-based storage system like XFS. It is space efficient for small files and indexed directories, and supports dynamic inode allocation. It handles multiple storage devices and provides support for RAID striping, mirroring and striping+mirroring. BTRFS is also flash drive aware with direct support for the TRIM/discard operations.
The system supports compression, writeable, and read-only snapshots, along with efficient incremental backup. The sub-volume system allows separate internal file system roots as well as quota system implementations. Out-of-band deduplication is supported. These features can be very useful in high-availability embedded systems.
BTRFS has minimal information stored in fixed locations. This is an advantage for ext2/3/4 migration since in-place conversion is possible, assuming that sufficient free space is available. In addition, BTRFS is the underlying storage system for Ceph, an open-source cluster file system.

About the Author

William G. Wong
Senior Content Director - Electronic Design and Microwaves & RF
I am Editor of Electronic Design focusing on embedded, software, and systems. As Senior Content Director, I also manage Microwaves & RF and I work with a great team of editors to provide engineers, programmers, developers and technical managers with interesting and useful articles and videos on a regular basis. Check out our free newsletters to see the latest content.
You can send press releases for new products for possible coverage on the website. I am also interested in receiving contributed articles for publishing on our website. Use our template and send to me along with a signed release form.
Check out my blog, AltEmbedded on Electronic Design, as well as his latest articles on this site that are listed below.
You can visit my social media via these links:
- AltEmbedded on Electronic Design
- Bill Wong on Facebook
- @AltEmbedded on Twitter
- Bill Wong on LinkedIn
I earned a Bachelor of Electrical Engineering at the Georgia Institute of Technology and a Masters in Computer Science from Rutgers University. I still do a bit of programming using everything from C and C++ to Rust and Ada/SPARK. I do a bit of PHP programming for Drupal websites. I have posted a few Drupal modules.
I still get a hand on software and electronic hardware. Some of this can be found on our Kit Close-Up video series. You can also see me on many of our TechXchange Talk videos. I am interested in a range of projects from robotics to artificial intelligence.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: