
Download this article in PDF format.
Computer vision tries to replicate human perception and associated brain functions to acquire, process, analyze, understand, and then act on an image. But replicating this process is extremely challenging. Why? Let’s look at an example.
Driving back to work from your lunch break, you have a craving for dessert. As your eyes scan passing businesses, your brain applies filters to isolate a business that sells sweets and your favorite dessert items are retrieved from memory, such as “doughnuts,” “candy,” and “cookies.” Once you see a match to your craving, you pull into the shop to get your treat. As you enter the shop, your sense of smell triggers memories of the dessert that you associate with happiness and you visually select that item.
Designers analyze what hardware and software is required to perform this same task. The seemingly simple concept of isolating an image to identify it has taken years of research and development to accomplish. Today, teams using computer-vision hardware and software algorithms coupled with deep learning are seeing success in identifying objects.
However, as of now, computer-vision systems can’t be pointed at a random object and asked, “what is that?” and have it answer with 100% reliability every time. For example, while road testing a self-driving car in Australia, the computer-vision system could not figure out what a kangaroo was.

1. Tractica reports the actual and predicted computer-vision hardware and software market revenue.
You can almost imagine as many products and markets for computer vision as there are uses for the human eye. The combined hardware and software revenue from 2015 to 2022 shows tremendous growth predictions for these markets (Fig. 1).
Semiconductor and component manufacturers, software companies, and product developers are all making major investments in developing computer-vision products supporting these major markets.
Computer-Vision Systems
The basic architecture of a computer-vision system consists of a lens, hardware, and software (Fig. 2). Developers of these systems decide what algorithms are implemented in hardware and which remain in software.
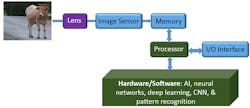
2. A typical computer-vision system architecture consists of a lens, hardware, and software.
Companies are developing computer-vision systems tied to deep-learning systems that live on the edge of the Internet of Things (IoT), in onboard systems, or that perform inference analysis in the cloud. Of particular interest is the processor (or array of processors) used in the computer-vision system.
The deep-learning algorithms perform billions of computations and need to produce results quickly. These systems can employ solutions using CPU/DSP, GPU, FPGA, embedded FPGA, or ASIC technologies. Each has its advantages and disadvantages, and GPUs are currently the technology of choice. But, GPUs consume lots of power and they might be unsuitable for onboard systems. In addition, GPUs don’t allow for flexible hardware configurations tailored to particular algorithms.
Consequently, FPGA and embedded FPGA technology is starting to make inroads into computer-vision processing. If the market demands, implementations using FPGA technologies migrate to ASIC technologies. Teams need a fast way to see how their algorithms perform on any of these technologies before production, without changing their algorithm description.
Why is Computer Vision on the Rise?
Hardware and software improvements continue to drive the computer-vision market as the race to achieve 100% accuracy is underway. Convolutional neural networks (CNNs), which have become the technology of choice for image recognition and classification, have experienced a steady stream of advances that continues forward. It’s only within the past five years that the ecosystem (Fig. 3) has evolved to accelerate computer-vision product development.
3. Tractica reports that a complete computer-vision product-development ecosystem now exists.
Many technical advances contribute to this acceleration, too:
- Deep-learning advances have occurred for statistical analysis of images to successfully identify and classify objects.
- Wireless networks are available to millions of people, with expansion occurring every day.
- High-bandwidth availability to transmit images for processing and analysis is available.
- Massive data storage and access is offered for CNN training.
- Gigantic image databases have been collected for training networks.
- Software stack and open source libraries are available to build differentiated products without reinventing the infrastructure.
- The ability to create custom ICs is easier now with new and improved tools, IP, and multi-project wafer options from the IC fabrication companies.
- CMOS image sensors are now equivalent with CCD sensors and they can be fabricated using the same technology that’s employed for chipsets—for less money.
In addition, key market barriers that provide opportunities for companies to invent new solutions must be overcome:
- Most computer-vision advances take place in research labs of universities and big companies with deep pockets and skilled employees. This means that development costs could be a barrier to entry.
- There’s a shortage of skilled engineers with computer vision and deep learning expertise.
- Many more software engineers populate the workforce than hardware engineers.
- There’s no recognized “killer application” yet for computer-vision products. Some believe this will be self-driving cars.
- Complex CNN algorithms are computationally intensive and consume a lot of power for CPUs and GPUs, limiting onboard (smartphone, drones, or cars) analysis of computer images.
- New algorithms and training solutions change and evolve constantly, making hardware implementations very difficult to complete before the next, better idea comes along.
Hardware Design Focuses on Inference CNNs
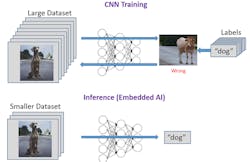
4. It’s important to know the difference between CNN training and inferencing.
Computer-vision systems are commonly implemented using CNNs and they attempt to replicate the way brain neurons interact to recognize images. CNNs are employed in two distinct ways (Fig. 4):
- Training: Using a huge dataset, computer farms run for multiple weeks calculating weights for convolutional filters by applying floating-point numbers.
- Inferencing: Using a smaller dataset, the CNN runs convolutions using the weights from the training to recognize images in real time utilizing fixed-point or integer numbers. The inferencing solution can be implemented in hardware to be deployed in computer-vision systems.
Since many computer vision systems are deployed in cars, equipment, or consumer products, which can’t depend on a lab full of computers, inferencing solutions are the focus of designer teams.
The High-Level Synthesis Solution
Because the world of computer vision coupled with machine learning transforms so rapidly, teams need a way to design and verify an algorithm in hardware, while the specifications and requirements evolve, without starting over every time there’s a change. High-level synthesis (HLS) flows support change by using constraints and directives that guide the process to generate RTL (register transfer language), while leaving the C++ algorithm unchanged. For example, at the last minute, a team decides to change the FPGA technology. That constraint is changed and the HLS tool regenerates the RTL according to the new technology, with no change to the C++ algorithm. This type of late-stage change isn’t possible in traditional RTL flow; yet with HLS, the RTL is rebuilt with a push of a button.
Many years ago, Mentor recognized that design and verification teams needed to move up from the RTL to the HLS level. Working with customers over that time resulted in the Catapult HLS Platform, which offers a complete flow from C++/SystemC to optimized RTL (Fig. 5).
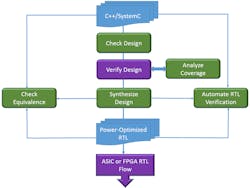
5. The Catapult HLS Platform provides a complete design flow.
The Catapult HLS Platform, a hardware design solution for algorithm designers, generates high-quality RTL from C++ and/or SystemC descriptions that target ASIC or FPGA implementation. The platform, with its seamless and reusable testing environment, makes it possible to check the design for errors before simulation, and supports formal equivalence checking between the generated RTL and the original source. This flow helps accelerate design and verification and deliver power-optimized RTL ready for simulation and RTL synthesis.
The Takeaway
Computer-vision product development provides a wide array of opportunities for design automation, from the design of self-contained systems that include analysis of the images, to the chip development for servers in the cloud that are used to perform deep learning. Custom ASIC, FPGA, and embedded FPGA design flows are well-established, but are seeing a new audience of computer vision and deep-learning developers.
High-level synthesis solutions now enable software algorithm developers to make informed decisions as to which hardware technologies work best for their application without being hardware experts. The HLS flow also helps hardware designers, because they can support constantly evolving architectures. Without a HLS flow, market-leading computer-vision innovation is impossible.
Badru Argawala is General Manager at Mentor, a Siemens Business.

About the Author
Badru Agarwala
General Manager
Badru Agarwala is the General Manager of the Calypto Systems Division since September 2015 at Mentor, a Siemens Business. Badru joined Mentor with the acquisition of Axiom Design Automation Inc. in December 2012. At Axiom, Badru served as the Chief Executive Officer and President; he co-founded the company in 1999. Badru is a co-founder of Silicon Automation Systems (currently Sasken Communication). He also founded and served as President of Frontline Design Automation, acquired by Avant! Corp. in 1997. After the acquisition, he served as Vice President, Front End for Avant!.
Badru's vision for designer productivity improvements stems from his extensive experience working with the design and verification community, in which he has been a pioneer. He holds a Master’s in Computer Engineering from the University of Iowa and a B.S. in Electrical Engineering from the University of Bombay.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: