
This file type includes high resolution graphics and schematics when applicable.
Deep learning, or deep neural nets (DNNs), is the technical craze these days. It is targeting everything from self-driving cars to tagging photos. DNNs are just one of many artificial intelligence (AI) research areas. It has become more popular as processor performance has increased, allowing more complex systems.

âDNNs require matrix number-crunching capabilities found in FPGAs and GPUs. GPUs are now the target for a number of DNN platforms. NVidia’s Tesla P100 GPU (Fig. 1) is designed to tackle applications like deep learning neural nets. The Tesla P100 can deliver 21 TFLOPS of 16-bit floating point that is ideal for DNN applications. It employs CoWoS (Chip-on Wafer-on-Substrate) with HBM2 (high-bandwidth memory version 2) technology. AMD used HBM on its Radeon R9 GPU (see “Best of 2015: High Bandwidth Memory Helps GPU Deliver on Performance ” on electronicdesign.com). The Tesla P100 has four NVLinks, allowing multiple chips to be combined into a single compute node.
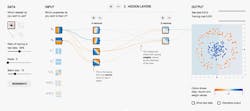
NVidia’s chip supports the CUDA programming environment. The Cuda DNN (cuDNN) runtime targets DNN frameworks like TensorFlow, an open-source software library for numerical computation. You can check out the TensorFlow Playground (Fig. 2) website to see how TensorFlow and neural networks operate by changing variables such as the number of nodes and layers.
DNN will not solve all AI problems and it is not necessarily a magic bullet for applications, but it is a valuable tool that is becoming more practical for general use.
Looking for parts? Go to SourceESB.
About the Author
William Wong Blog
Senior Content Director
Bill's latest articles are listed on this author page, William G. Wong.
The latest blogs have been moved to alt.embedded on Electronic Design.
Bill Wong covers Digital, Embedded, Systems and Software topics at Electronic Design. He writes a number of columns, including Lab Bench and alt.embedded, plus Bill's Workbench hands-on column. Bill is a Georgia Tech alumni with a B.S in Electrical Engineering and a master's degree in computer science for Rutgers, The State University of New Jersey.
He has written a dozen books and was the first Director of PC Labs at PC Magazine. He has worked in the computer and publication industry for almost 40 years and has been with Electronic Design since 2000. He helps run the Mercer Science and Engineering Fair in Mercer County, NJ.
- Check out more articles by Bill Wong on Electronic Design
- Bill Wong on Facebook
- @AltEmbedded on Twitter
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: