Machine-Learning Inference Chip Travels to the Edge

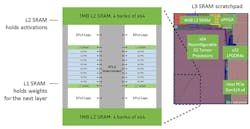
Flex Logix has unveiled its InferX X1 machine-learning (ML) inference system, which is packed into a 54-mm2 chip. The X1 incorporates 64 1D Tensor processing units (TPUs) linked by the XFLX interconnect (Fig. 1). The dual 1-MB level 2 SRAM holds activations while the level 1 SRAM holds the weights for the next layer of computation. An on-chip FPGA provides additional customization capabilities. There’s also a 4-MB level 3 SRAM, LPDDR4 interface, and x4 PCI Express (PCIe) interface.
The company chose to implement one-dimensional Tensor processors (Fig. 2), which can be combined to handle two- and three-dimensional tensors. The units support a high-precision Winograd acceleration option. This approach is more flexible and delivers a high level of system utilization.

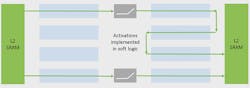
The simplified concept and underlying embedded FPGA (eFPGA) architectural approach allows the system to be reconfigured rapidly and enables layers to be “fused” together. This means that intermediate results can be given to the next layer without having to store them in memory, which slows down the overall system (Fig. 3). Moving data around ML hardware is often hidden, but it can have a significant impact on system performance.
The inclusion of an eFPGA and a simplified, reconfigurable TPU architecture makes it possible for Flex Logix to provide a more adaptable ML solution. It can handle a standard confv2d model as well as a depth-wise conv2d model.
The chips are available separately or on a half-height, half-length PCIe board (Fig. 4). The PCIe board includes a x8 PCIe interface. The X1P1 board has a single chip while the X1P4 board incorporates four chips. Both plug into a x8 PCIe slot. The reason for going that route rather than a x16 for the X1P4 is because server motherboards typically have more x8 slots than x16 and the throughput difference for ML applications is minimal. As a result, more boards can be packed into a server. The X1P1 is only $499, while the X1P4 goes for $999.

The X1M M.2 version is expected to arrive soon. The 22- × 80-mm module has a x4 PCIe interface and will be available in 2021. It targets embedded servers, PCs, and laptops.
About the Author

William G. Wong
Senior Content Director - Electronic Design and Microwaves & RF
I am Editor of Electronic Design focusing on embedded, software, and systems. As Senior Content Director, I also manage Microwaves & RF and I work with a great team of editors to provide engineers, programmers, developers and technical managers with interesting and useful articles and videos on a regular basis. Check out our free newsletters to see the latest content.
You can send press releases for new products for possible coverage on the website. I am also interested in receiving contributed articles for publishing on our website. Use our template and send to me along with a signed release form.
Check out my blog, AltEmbedded on Electronic Design, as well as his latest articles on this site that are listed below.
You can visit my social media via these links:
- AltEmbedded on Electronic Design
- Bill Wong on Facebook
- @AltEmbedded on Twitter
- Bill Wong on LinkedIn
I earned a Bachelor of Electrical Engineering at the Georgia Institute of Technology and a Masters in Computer Science from Rutgers University. I still do a bit of programming using everything from C and C++ to Rust and Ada/SPARK. I do a bit of PHP programming for Drupal websites. I have posted a few Drupal modules.
I still get a hand on software and electronic hardware. Some of this can be found on our Kit Close-Up video series. You can also see me on many of our TechXchange Talk videos. I am interested in a range of projects from robotics to artificial intelligence.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: