AI Can Tame Conferencing’s Hunger for Bandwidth

What you’ll learn:
- Applying AI to video-conferencing devices.
- What is Super-Resolution image expansion?
- The impact of deep-learning networks and specter of generative adversarial networks (GANs).
Video conferencing for virtual meetings, distance learning, or socializing has exploded with the onset of the coronavirus pandemic. Some experts suggest that even after the virus recedes, our reliance on virtual gatherings will remain part of our new normality. If so, the huge bandwidth hunger that ubiquitous video conferencing imposes on the internet—from the core out to the thinnest branches—is here to stay.
Even using modern video codecs, a video conference can be demanding on bandwidth: 1 to 2 Mb/s per participant just to keep those thumbnail images on the screen. And there’s growing evidence that with experience, users become more critical of image quality, longing to see fine details of facial expressions, gestures, and posture that carry so much information in an in-person meeting. This trend limits the ability of apps to use higher compression ratios to reduce bandwidth needs. The fine detail the compression algorithm throws out contains just the cues a skilled negotiator needs most.
AI to the Rescue?
Help with this dilemma can come from a surprising source: artificial intelligence (AI), or more specifically, a branch of AI called deep-learning networks. Today, a machine-learning application called Super-Resolution image expansion—already being explored for delivering high-quality video to 4K UHD television screens—can cooperate with existing video-conferencing apps to significantly reduce their required bit rates.
Here is how it works. Each video-conferencing device in the conference that intends to display high-resolution images would maintain two machine-learning “inference models.” Each model is a block of code and data that’s been trained beforehand, through an exhaustive process in a data center, to perform a particular function. One of the models processes the video from a user’s HD camera before sending it the conferencing app, and the other processes video coming out of the conferencing app before displaying it (Fig. 1).
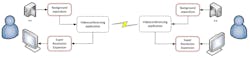
The first model takes in video from the camera frame by frame and isolates the image of the user from the background, reducing the number of pixels that later stages will have to deal with. This simplified video stream then flows on to a normal video-conferencing app, where it’s sampled down to a lower resolution like 480P and then compressed using an industry-standard algorithm such as H.264. The compressed video is subsequently exported. Except for that first step of isolating the user’s image, everything so far has gone as it would in any other video-conferencing scenario.
On the receiving end, the video-conferencing app receives the compressed bit stream, decompresses it into low-resolution video, and sends the video stream to the display subsystem. If the image is to be displayed as a thumbnail—in a multi-party conference, for instance—the video will be displayed directly. The image quality will be good enough for the small size on screen. But if the image is to be larger, the decompressed video is diverted into the second deep-learning model, the Super-Resolution expander.
The Super-Resolution model has been trained using a myriad of images with different faces, lightings, and poses to selectively add back the information that’s been lost when going to low resolution and in compression. The result is a high-quality image of the original user that closely resembles her image in the original HD camera video.
Note that this isn’t the same as decompression. The AI model is adding features into the low-res image that aren’t there, but that human subjects would expect to see, completing the high-resolution picture frame by frame in real-time.
What it Takes
Deep-learning networks, like most kinds of AI, are notorious for their huge computing appetites. Fortunately, most of the computing goes into training the models in the first place—a task done in a data center before the model is shipped to users. Once a deep-learning model is trained, it’s just a reasonably compact block of code and some data files. Both the user-extraction model and the Super-Resolution expander model can be run comfortably on a GPU or a reasonably fast notebook computer.
But as video conferencing becomes more common, the need will grow to use much more modest devices, such as dedicated conferencing appliances, tablets, smart TVs, or set-top boxes. Work on special deep-learning hardware accelerators—chips that vastly increase the number of computations done at the same time while sharply reducing power consumption—has brought these deep-learning models within the range of low-cost, low-power devices.
One example of this work is the Synaptics VS680 system-on-chip (SoC). This multimedia processor SoC combines Arm CPU cores, a GPU, video- and audio-processing subsystems, extensive provisions for security and privacy, and a deep-learning accelerator called the Neural Processing Unit. That latter block can run both the user-extraction and the Super-Resolution expander models at the same time at full video frame rates.
The result is a single chip that substantially reduces bandwidth requirements for video conferencing while maintaining high-quality images, at a price and power consumption suitable for even low-cost displays, streamers, and set-top boxes. And the service is compatible with existing video-conferencing apps.
As use of video conferencing continues to rise, and as it’s utilized by more people in areas marginally served by broadband access—often people without expensive notebook computers—the ability to significantly reduce bandwidth requirements without harming image quality, and to do so on inexpensive devices, will become increasingly important.
The Many Faces of Deep Learning
A deep-learning network model, once designed and trained, can only do what it was trained to do: identify flowers, say, or in our case, pick a person out of her surroundings in a video frame. But the underlying software and hardware that execute the trained model can often handle a wide variety of different kinds of machine-learning models, trained in different ways to perform very different tasks.
For example, the firmware and the Neural Processing Unit hardware in the Synaptics VS680 can perform a wide variety of jobs in a multimedia system. These include recognizing objects, sensing the user’s location and surroundings, or detecting objectionable content or malware in incoming data streams.
The calculations performed by a deep neural network are massive, but fundamentally simple ones. Figure 2 shows the structure of one of the most popular neural networks: MobileNet. It contains a series of convolutions that require massive amounts of multiply-and-accumulate operations.

This makes the problem highly amenable to optimization by custom hardware implementations. MobileNet is a typical network that can be used for multiple image-processing applications. Networks for other tasks are built using similar primitives; that’s why the dedicated Neural Processing Unit in the Synaptics VS680 can deliver high performance to any deep-learning AI task in video, audio, or analytics applications, to name a few.
One recent proposal by a GPU vendor illustrates the not necessarily desirable lengths to which this flexibility can be taken. There’s a category of deep-learning networks called generative adversarial networks, or GANs. They are used, most notoriously, to create deep-fake videos.
Given a detailed photo of a person and a set of parameters specifying the location and orientation of key facial features and body parts, a well-trained GAN will generate a photorealistic image of the person. That image could be in surroundings not present in the original photo, and gestures and expressions could be different from those in the original. String a sequence of such generated images together, and you have a video of the person doing or saying things they never did or said, in a place they may have never been.
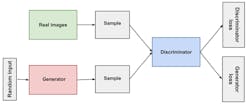
Training a GAN involves two neural networks: a generator, and a discriminator (Fig. 3). The generator will generate random images, which the discriminator will try to tell from real images. The discrepancy between the generated image and the real image gets fed back to the generator during training. Eventually the generator will be able to generate images that the discriminator can’t distinguish from the real ones. The discriminator network is performing image classification and could be based on MobileNet or another network.
Despite the unfortunate obvious use of this technology, it can also be utilized to slash the bandwidth consumer in video conferencing. By using a GAN to generate an image of the user at the receiving end of the connection, you need only send an initial static image and then a stream of data specifying the location and shape of the key features. This stream of data can be significantly smaller than the original high-res compressed video stream.
There are practical issues. For one, because the technique sends a stream of abstract data rather than a stream of standard compressed video, it’s not compatible with existing video-conferencing apps. For another, the security risks of operating a video-conferencing network full of GANs, any of which could be hijacked to create deep-fake images instead of reconstructed ones, would require careful consideration. But the idea illustrates how, once a video-conferencing device is able to execute deep-learning models, imagination is the only limit on the functions it can perform.
Deep-learning inference acceleration hardware like the VS680’s Neural Processing Unit can deploy AI to provide this bandwidth reduction. Such a solution is able to work with existing conferencing services and fit within the cost and power budgets of inexpensive consumer devices. Distance learning and working from home needn’t force us to choose either that users learn to accept terrible image quality, or service providers make deeper investments in network bandwidth. With intelligence, we can have our cake and eat it, too.
About the Author
Pontus Lidman
Principal Software & Security Architect, Synaptics Inc.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: