Accelerating Machine Learning Means New Hardware

Machine learning (ML) is only one aspect of artificial intelligence (AI). ML also has many parts to it, but those having the biggest impact now are based around neural networks (NNs). Even drilling down this much doesn’t narrow the field a lot due to the multitude of variations and implementations. Some work well for certain types of applications like image recognition, while others can handle natural language processing or even modification and creation of artwork.
There are deep neural networks (DNNs), convolutional neural networks (CNNs), and spiking neural networks (SNNs). Some are similar while others use significantly different approaches and training techniques. All tend to require more significant amounts of computing power than conventional algorithms, but the results make neural networks very useful.
Though ML applications run on lowly microcontrollers, the scope of those applications is actually limited by the hardware. Turning to hardware tuned or designed for NNs allows designers to implement significantly more ambitious applications like self-driving cars. These depend heavily on the ability of the system to employ NNs for image recognition, sensor integration, and a host of other chores.
Hardware acceleration is the only way to deliver high-performance ML solutions. A microcontroller without ML hardware may be able to run an ML application for checking the motor it’s controlling to optimize performance or implement advanced diagnostics, but it falls short when trying to analyze video in real time.
Likewise, processing larger images at a faster rate is just one ML chore that places heavy demands on a system. A plethora of solutions are being developed and delivered that provide orders of magnitude more performance to address training and deployment. In general, deployment needs are less than systems doing training but there are no absolutes when it comes to ML.
This year’s Linely Spring Processor Conference was almost exclusively about AI and ML. Most of the presentations addressed high-performance hardware solutions. While many will land in the data center, a host of others will wind up on “the edge” as embedded systems.
Wafer-Scale Integration Targets Machine Learning
Creating new architectures are making ML platforms faster; still, there’s an insatiable need for more ML computing power. On the plus side, it’s ripe for parallel computing and cloud-based solutions can network many chips to handle very large or very many ML models.
One way to make each node more powerful is to put more into the compute package. This is what Cerebras Systems’ Waferscale Engine (WSE) does with identical chips, but it doesn’t break up the die (Fig. 1). Instead, the connections between chips remain, making the 46,225-mm2 silicon solution the largest complete computing device with 1.2 trillion transistors that implement 400,000 AI optimized cores. The die has 18 GB of memory with 9 petabytes per second (PB/s) of memory bandwidth. The fabric bandwidth is 100 petabits per second (Pb/s). The chip is implemented by TSMC using its 16-nm process.

Each chip is power-efficient; however, packing this much computing power in a small package leads to lots of heat. Multiple die are put into one water-cooled system. Multiple systems can fit into a standard rack with Ethernet connections, allowing very large systems to be constructed. The interconnect and computational support have been optimized to handle sparse neural networks that are common for most applications.
Spiking Neural Network Hardware
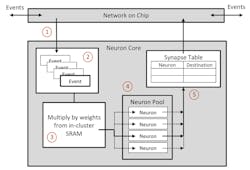
Spiking neural networks (SNNs) have different characteristics than DNNs. One advantage with SNNs is that the support for learning is on par for deployment, whereas DNNs require lots of data and computational capabilities for training compared to deployment. SNNs can also handle incremental training. Furthermore, SNNs require less computational overhead because they only process neurons when triggered (Fig. 2).

BrainChip’s AKD1000 Neural Network SoC (NSoC) can handle both DNNs and SNNs. The architecture supports up to 80 neural processing units (NPUs)—the AKD1000 has 20 NPUs (Fig. 3). A conversion complex implements a spike event converter and a data-spike event encoder that can handle multivariable digital data as well as preprocessed sensor data. The SNN support only processes non-zero events.
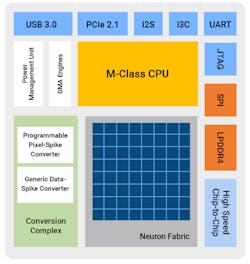
The AKD1000 benefits from sparsity in both activations and weights. It supports quantizing weights and activations of 1, 2, or 4 bits, leading to a small memory footprint. NPUs communicate events over a mesh network, so model processing doesn’t require external CPU support.
Tenstorrent also targets SNN as well as DNN, CNN and other neural network applications with its Tensix cores (Fig. 4). The cores have five single-issue RISC cores and a 4-TOPS compute engine. A packet processing engine provides decoding/encoding and compression/decompression support along with data-transfer management.

As with most SNN platforms, Tensix cores can be used on the edge or in the data center. They provide fine-grained conditional execution that makes the system more efficient in processing SNN ML models. The system is designed to scale since it doesn’t use shared memory. It also doesn’t require coherency between nodes, enabling a grid of cores to be efficient connected via its network.
GrAI Matter Labs also targets this event-driven ML approach with its NeuronFlow technology (Fig. 5). The GrAI One consists of 196 neuron cores with 1024 neurons/core, which adds up to 200,704 neurons. A proprietary network-on-chip provides the interconnect. No external DRAM is needed. The SDK includes TensorFlow support.
CNNs, DNNs, and More
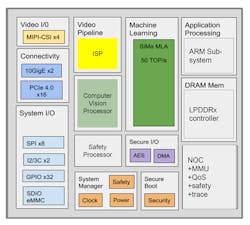
Convolutional neural networks are very useful for certain kinds of applications like image classification. SiMaai optimized its chip (Fig. 6) for CNN workloads. By the way, sima means “edge” in Sanskrit. The chip is also ISO 26262 ASIL-B compliant, allowing it to be used in places where other chips aren’t suitable, such as automotive applications.
Flex Logix is known for its embedded FPGA technology. The company brought this expertise to the table with its nnMAX design and the InferX X1 coprocessor. The nnMAX array cluster is designed to optimize memory use for weights by implementing Winograd acceleration that handles input and output translation on-the-fly. As a result, the system can remain active, while other solutions are busy moving weights in and out of external memory. The chip supports INT8, INT16, and BFLOAT16. Multiple models can be processed in parallel.
Groq’s Tensor Streaming Processor Chip (TSP) delivers 1 petaoperations per second, running at 1.25 GHz using INT8 values. The chip architecture also enables the system to provide this high level of performance by splitting data and code flow (Fig. 7). The 20 horizontal data-flow superlanes are managed by the vertical SIMD instruction flow. Identical east/west sections let the data flow in both directions. There are 20 superlanes with 16 SIMD units each.
Processors and DSPs
Special ML processors are the order of the day for many new startups, but extending existing architectures garners significant performance benefits while keeping the programming model consistent. This allows for easy integration with the rest of an application.
Cadence’s Tensilica HiFi DSP is now supported by its HiFi Neural Network library in addition to the Nature DSP library that handles vector math like FFT/FIR and IIR computations. The 8-/16-/32-bit SIMD and Vector FPU (VFPU) support provides efficient support for neural networks while enabling a custom design DSP to include customer-specific enhancements.
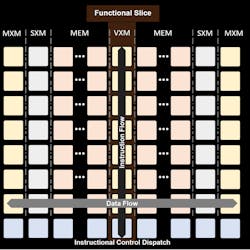
CEVA’s SensPro sensor hub DSP combines the CEVA-BX2 scalar DSP with a NeuPro AI processor and a CEVA-XM6 vision processor. The wide SIMD processor architecture is configurable to handle 1024 8-×-8 MACs, 256 16-×-16 MACs, or dedicated 8-×-2 binary-neural-network (BNN) support. It can also handle 64 single-precision and 128 half-precision floating-point MACs. This translated to 3 TOPS for the 8-×-8 network’s inferencing, 20 TOPS for BNN inferencing, and 400 GFLOPS for floating-point arithmetic.
The DesignWare ARC HS processor solution developed by Synopsys takes the tack of having lots of processors to address the ML support. This isn’t much different than most solutions, but it’s more along the lines of conventional RISC cores and interconnects that are typically more useful for other applications.
AMD isn’t the only x86 chip producer. Via Technologies has its own x86 IP and its Centaur Technology is making use of that. The x86 platform is integrated with an AI Ncore coprocesessor tied together by a ring (Fig. 8). The Ncore utilizes a very wide SIMD architecture organized into vertical slices to provide a scalable configuration, making future designs more powerful. The chip can deliver 20 TOPS at 2.5 GHz.
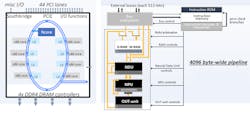
I’ve previously covered the Arm Cortex-M55 and Ethos-U55 combination. The Cortex-M55 has an enhanced instruction set that adds a vector pipeline and data path to support the new SIMD instructions. The DSP support includes features like zero overhead loops, circular buffers, and bit reverse addressing.
Still, as with other architectures, a dedicated AI accelerator is being added to the solution—namely, the Ethos-U55 micro network processor unit (microNPU). It supports 8- or 16-bit activations in the models, but internally, weights will always be 8 bits. The microNPU is designed to run autonomously.
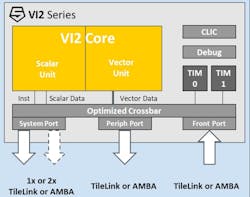
While the V in RISC-V doesn’t stand for vectors, SiFive’s latest RISC-V designs do have vector support that’s ideal for neural-network computational support (Fig. 9). What makes this support interesting is that the vector support can be dynamically configured. Vector instructions work with any vector size using vector-length and vector-type registers. The compiler vectorization support takes this into account. The VI2, VI7, and VI8 platforms target every application space through the data center.
Extending FPGAs and GPGPUs
Xilinx’s Versal adaptive compute acceleration platform (ACAP) is more than just an FPGA (Fig. 10). The FPGA fabric is at the center, providing low-level customization. However, there are hard cores and an interconnect network surrounding it. The hard cores range from Arm Cortex CPUs for application and real-time chores along with AI and DSP support.

I left Nvidia to the end, as the company announced its A100 platform at the recent, virtual GPU Technology Conference (Fig. 11). This GPGPU incorporates a host of ML enhancements, including sparsity acceleration and multi-instance GPU (MIG) support. The latter provides hardware-based partitioning of the GPU resources that allow more secure and more efficient operation. Large-scale implementations take advantage of the third-generation NVLink and NVSwitch technology that tie multiple devices together.

The plethora of machine-learning options includes more than just the platforms outlined here. They reflect not only the many ways that ML can be accelerated, but also the variety of approaches that are available to developers. Simply choosing a platform can be a major task even when one understands what kind of models will be used, and their possible performance requirements. Likewise, the variants can offer performance differences that are orders of magnitude apart. System and application design has never been more exciting or more complicated. If only we had a machine-learning system to help with that.
About the Author

William G. Wong
Senior Content Director - Electronic Design and Microwaves & RF
I am Editor of Electronic Design focusing on embedded, software, and systems. As Senior Content Director, I also manage Microwaves & RF and I work with a great team of editors to provide engineers, programmers, developers and technical managers with interesting and useful articles and videos on a regular basis. Check out our free newsletters to see the latest content.
You can send press releases for new products for possible coverage on the website. I am also interested in receiving contributed articles for publishing on our website. Use our template and send to me along with a signed release form.
Check out my blog, AltEmbedded on Electronic Design, as well as his latest articles on this site that are listed below.
You can visit my social media via these links:
- AltEmbedded on Electronic Design
- Bill Wong on Facebook
- @AltEmbedded on Twitter
- Bill Wong on LinkedIn
I earned a Bachelor of Electrical Engineering at the Georgia Institute of Technology and a Masters in Computer Science from Rutgers University. I still do a bit of programming using everything from C and C++ to Rust and Ada/SPARK. I do a bit of PHP programming for Drupal websites. I have posted a few Drupal modules.
I still get a hand on software and electronic hardware. Some of this can be found on our Kit Close-Up video series. You can also see me on many of our TechXchange Talk videos. I am interested in a range of projects from robotics to artificial intelligence.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: