Breaking the Von Neumann Bottleneck: A Key to Powering Next-Gen AI Apps

What you’ll learn:
- How to improve the drawbacks of the Von Neumann architecture.
- Benefits of in-memory compute technology.
One of the biggest limitations to co-processor acceleration and advanced functional processing is a situation that limits data exchange between processors. A major drawback of the Von Neumann architecture is a problem that’s commonly referred to as the “Von Neumann bottleneck.” Memory and the CPU are separated in the Von Neumann architecture, so the CPU must fetch data for every operation it performs.
This architecture is even more inefficient in an offload acceleration environment. The performance of such systems is limited by the speed at which data can be exchanged via memory by the host requesting the operations as well as compute engines performing the operations. This creates a bottleneck in system performance that can’t be addressed by increased CPU speeds or just using more cores.
And as datasets expand, the bottleneck gets worse. Typically, a host will send a complex functional operation to an accelerator. To “send” that function, the host CPU must read the data to be operated on and send it to the accelerator card. A Von Neumann-based accelerated system now incurs at least two sets of data movement and likely three if the operating CPU must get the data from working memory.
Von Neumann systems can efficiently perform complex calculations on datasets that can be moved in parallel during the pipelined calculation, but they fall short when it comes to managing larger datasets and real-time operations. This shortcoming is particularly bad for tasks such as search on large datasets that could require packing sufficient queries to make the batch efficient, or as the trained data needs to be constantly loaded into the working memory whereby the pipeline breaks.
Bottlenecks Causing Bog Downs
Today’s datasets continue to grow, and traditional processors and processor accelerators are struggling under the load and slowing down analysis at the system level. The solution to date has been to throw more compute resources with memory at the problem, both at the host and accelerator levels. Even at the chip level, this still incurs the Von Neuman bottleneck. The bottleneck still impedes the processor cores, which can process data only as fast as they receive it.
Here is an example. A high-level application wants some dataset processed. Let’s assume the array is stored in bulk memory and ready for processing. The host CPU must still go get that data from stored memory and put it in its own memory. Then it needs to send the location of the data to a GPU. The GPU now reads that data into its own working memory and implements the instruction that it was given. It writes the results back to its memory and tells the CPU it’s done.
Subsequently, the CPU reads the results from the GPU memory, puts it back to its working memory, and tells the application it’s done—maybe having it read to send to the monitor. This back-and-forth takes a tremendous amount of time and power. Even worse, the GPU remains inactive during periods when the CPU needs to take results and reload memories for its next operation.
In all cases, we have a general-purpose or customer application computer or server that generates a problem (Fig. 1). This problem is sent to a second processing element for faster hardware-based processing.
In a PC, the general-purpose host is the CPU itself and the hardware accelerator may be a GPU card. For a larger data center, the function processing unit would be another server or core server farm, and these may be accelerated by a GPU or array of GPUs. In all of these case,s there is memory (in some cases more than one level of abstraction) between the requestors and the processors (Fig. 2).
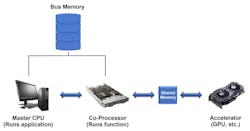
Solution: In-Memory Processors
That’s why a new type of processor is needed, one that computes directly in the memory array. By having the memory array also do compute chores, this type of “accelerated” processor can achieve more than 100X the performance of a standard server while using less power.
In such a processor, the memory within it can be processed in-place. Think of it as a memory read-modify-write operation, where the modify is a compute operation. Indeed, this type of in-memory computing can reduce computation time from minutes to seconds—or even to milliseconds.
The good news is that it’s not theoretical. Such a design exists today, and it’s used to power the next generation of AI applications.
The Von Neumann bottleneck is particularly egregious when you’re dealing with artificial-intelligence (AI) applications. Why? Mostly due to the memory-intensive nature of AI. The operation of AI-related applications depends on the fast and efficient movement of massive amounts of data in memory. Trained databases must be loaded into working memory and vectorized input queries then processed and loaded for comparison functions to operate.
The beauty of in-memory acceleration is that storage itself becomes the processor. By optimizing the storage of large datasets in memory, we can start to enable many exciting new use cases. A good example is image recognition, in which an AI algorithm can take a raw image and accurately identify what’s in that image. When accelerating this image recognition, it becomes more useful. In a system that uses the bulk storage of the trained database and only inputs the query and computes the inference result, we can achieve tremendous gains in efficiency because the database doesn’t move.
AI Algorithm in Action
Let’s give a hypothetical example using Walmart. When walking into your local Walmart, the store would love to know immediately if you’re a regular customer and what you typically shop for so that it can make an instant offer while you’re in the store. How can it do that? First, by using in-store cameras to capture an image of your face, then using AI and image recognition to match that image to identify your customer profile and check your authorization of the service.
Then Walmart can track your movement to see which areas of the store you most commonly frequent and where you spend the most time. This would put Walmart on a better footing even than Amazon, because not only can it map your online dwell time when you visit Walmart.com, it can also map your dwell time when you’re in a physical store. Package all that together and Walmart has the most complete picture possible of its loyalty program customers.
But, again, it all depends on the AI algorithm and being able to recognize a customer’s face immediately when in the store. That facial image gets zapped to the Walmart data center in the cloud. And once the image hits the data center, identification can happen much faster with in-memory acceleration because the Von Neumann bottleneck has been broken.
With this type of processing, Walmart could sift through much larger datasets and do it quickly and more accurately without significantly upgrading its physical plant. Furthermore, large data centers of servers and memory aren’t required to get an identification from a local database. Walmart could bring the processing efficiency down to the edge server in the store. For instance, when a customer is browsing a particular shelf, Walmart could instantly send an offer directly to the customer’s phone in real time, before they walk away.
Timely Real-Time Results
This new in-memory compute technology really shines when organizations need real-time results, particularly from very large, trained databases. If you have all the time in the world to get a result, then the Von Neumann bottleneck isn’t a big issue. But if time is of the essence, the bottleneck is a major drawback because it limits your ability to use insights from the data in a timely manner.
Imagine a child who gets separated from a parent while in that same Walmart store. What if you could figure out immediately that child’s location? With this new in-memory technology, it’s now possible to instantly match the child’s facial image with their physical presence in the store and quickly reunite child with parent before anything bad can happen.
In addition to image recognition, in-memory compute technology is being used to reduce drug-development time through the virtual screening of drug candidates. For instance, in-memory compute can accelerate the searching of libraries of small molecules to find those that are most likely to be biologically active and worthy of further evaluation. Ultimately, this can reduce the number of experiments that need to be done in a lab, significantly cutting the time and cost of drug discovery.
Any big-data workload that’s now hindered by memory bandwidth can benefit from in-memory processors and their ability to quickly search large datasets. The possibilities are endless, with applications such as e-commerce, natural-language processing, and visual search only the start of a future that is, by definition, limitless.
About the Author
Didier Lasserre
VP of Worldwide Sales, GSI Technology
Didier Lasserre is Vice President of Worldwide Sales for GSI Technology. Previously, Lasserre served as Director of Sales for the Western United States and Europe from 1997 to 2002. Prior to joining GSI Technology, Lasserre served as an account manager at Solectron Corp., a provider of electronics manufacturing services, and as a field sales engineer at Cypress Semiconductor.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: