Edge Processing Brings Audio Source Classification to Smart-Home Apps

What you’ll learn:
- Applications for audio-event and speech recognition in smart-home devices, including audio source classification.
- Benefits of processing audio on the edge.
- Approaches for solving audio-event recognition at the edge.
The implementation of AI and machine learning (ML) in consumer electronics, particularly in smart-home devices, is still just cresting its full potential. However, demand continues to grow as OEMs look for new ways to differentiate and improve the user experience.
New devices and appliances are released into the market every year with increasing AI capabilities, and the data gleaned from these devices enables device makers to assess and learn user habits, as well as predict future usage patterns using ML algorithms. This offers massive improvements to the end-user experience while providing important data to manufacturers and developers.
In a future smart home, AI could automatically control lights, appliances, and consumer gadgets based on predicted routines and by being contextually aware. For example, a smart light will be able to learn the preferences of different persons in the household, recognize their presence based on their voice signatures, and locally adjust a room’s lighting based on that individual’s usage history. Similarly, a smart washer, in addition to having voice control, will automatically be able to sense any load imbalance or water leaks, and adjust the settings or send alerts to prevent failures.
These burgeoning opportunities, though, have been stifled by the bandwidth, latency, and power-consumption challenges they create in smart devices, in addition to privacy concerns and other issues, limiting the current possibilities for product design teams. With voice-control capabilities in a smart assistant, for example, there can be no tolerance for latency—even if there’s a perceived delay of over 200 ms, a user is forced to the repeat their commands to the voice assistant.
Such challenges have driven many device manufacturers to increasingly consider using edge processors in devices to run ML tasks locally. In fact, several market research reports suggest edge-processor shipments will increase by more than 25% driven by the adoption of edge-based ML.
Several classes of ML algorithms can be used to make devices “smart” in a smart-home device. In most applications, the algorithms can recognize the user and the user’s actions and learn behavior to automatically execute tasks or provide recommendations and alerts. Recognizing the user or user actions is a classification problem in ML parlance.
In this article, we’ll briefly discuss audio source classification. By solving the challenges of audio source classification via audio edge processors specifically designed for advanced audio and ML applications, smart-home devices will ultimately make the jump from just smart to useful.
The Role of Advanced Audio and Speech Recognition
A user’s activity in the home is a rich data set of acoustic signals that include speech. While speech is the most informative sound, other acoustic events quite often carry useful information that can be captured in the recognition process.
Laughing or coughing during speech, a baby crying, an alarm going off, or a door opening mid-sentence are examples of acoustic events that can provide useful, contextual data to drive intelligent actions. Smart-home devices that feature advanced audio and speech recognition can recognize users, receive commands, perform detection and acoustic classification of sound events, and invoke actions.
The event recognition process is centered around feature extraction and classification. There are several approaches for audio-event (AE) recognition. The fundamental principle behind these approaches is that a distinct acoustic event has features that are dissimilar to those of the acoustic background.
Audio source classification algorithms detect and identify acoustic events. Thus, the process is split into two phases: the detection of an acoustic event, and its classification. The purpose of detection is to first discern between the foreground events and the background audio before turning on the classifier, which then categorizes the sound.
It’s expected that future smart-home devices will have both AE recognition as well as automatic speech-recognition capability. The figure below illustrates the general concept of such a smart-home system.
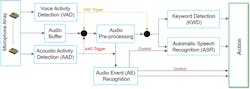
Acoustic-Event Recognition: Source Classification
A variety of signal-processing and ML techniques have been applied to solve the problem of audio classification, including matrix factorization, dictionary learning, wavelet filter banks, and most recently, neural networks. Convolutional neural networks (CNNs) have recently gained popularity due to their ability to learn and identify patterns that are representative of different sounds, even if part of the sound is masked by other sources, such as noise.
However, CNNs depend on the availability of large amounts of labeled data for training the system. And while speech has a large audio corpus due to the large-scale adoption of automatic speech recognition (ASR) in mobile devices and smart speakers, there’s a relative scarcity of labeled datasets for non-speech environmental audio signals. Several new datasets have been released in recent years, and it’s expected that the audio corpus for non-speech acoustic events will continue to grow driven by the increasing adoption of smart-home devices.
Acoustic-Event Recognition: Software and Tools
AE recognition software using source classification is available through multiple algorithm vendors including Sensory, Audio Analytic, and Edge Impulse. These vendors provide a library of sounds on which models are pre-trained, while also providing a toolkit for building models and recognizing custom sounds. When implementing AE recognition on an edge processor, the tradeoff between power consumption and accuracy must be considered—there must be a careful balance to ensure user satisfaction.
Multiple open-source libraries and models also are available. Here, we provide the results for audio-event classification based on YAMNet (Yet another Audio Mobilenet Network). YAMNet is an open-source pre-trained model on the TensorFlow hub that’s been trained on millions of YouTube videos to predict audio events. It’s based on MobileNet architecture, which is ideal for embedded applications and can serve as a good baseline for an application developer.
The table below displays the simulation results of a simple YAMNet classifier that’s less than 200 kB in size. It’s seen that such a small classifier can deliver sufficient accuracy for the detection of a few common audio events both in clean conditions and in the presence of noise.
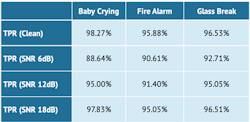
As shown in the table, the True Positive Rate (TPR) performance of the model increases with the signal-to-noise ratio (SNR) of the signal. Note: The data presented in the table is meant only for a high-level illustration of the concept. In practice, application developers spend many hours training and optimizing these models to accurately detect their sounds under their various test conditions.
Matrix operations are critical to executing the various ML algorithms illustrated in the figure. Depending on the type of application, many hundreds of millions of multiply-add operations may need to be executed. Therefore, the ML processor must have a fast and efficient matrix multiplier as the main computational engine.
Dedicated audio edge processors with dedicated accelerators for audio processing and with ML-optimized cores are the key to supporting high-quality audio communication and cutting-edge ML algorithms. These processors can deliver enough compute power to process audio and ML tasks while only using a small percentage of the energy of a generic processor.
Such audio edge processors will make smart-home devices and appliances increasingly more sophisticated by providing new features, while also optimizing on the end user experience. This in turn will help accelerate adoption of the smart home.
Conclusion
Smart-home devices as we know them now will increasingly become both smart and useful devices as the challenges of audio source classification are solved by audio edge processors specifically designed for advanced audio and ML applications. Designers should look for development kits that have pre-configured microphone arrays, pre-integrated and verified algorithms for voice and audio processing, and drivers that are compatible to the host processor and operating systems.
References
Mariscal-Harana, et al (2020). Audio-Based Aircraft Detection System for Safe RPAS BVLOS Operations. 10.20944/preprints202010.0343.v1.
Lopatka, K., Kotus, J. & Czyzewski, A. Detection, classification and localization of acoustic events in the presence of background noise for acoustic surveillance of hazardous situations. Multimed Tools Appl 75, 10407–10439 (2016). https://doi.org/10.1007/s11042-015-3105-4
Temko A., Nadeu C., Macho D., Malkin R., Zieger C., Omologo M. (2009) Acoustic Event Detection and Classification. In: Waibel A., Stiefelhagen R. (eds) Computers in the Human Interaction Loop. Human–Computer Interaction Series. Springer, London. https://doi.org/10.1007/978-1-84882-054-8_7
About the Author
Raj Senguttuvan
Director, Strategic Marketing, Knowles Corp.
Raj is an accomplished innovation and business leader with an electrical engineering background. Raj has over 15 years of experience in new technology development for consumer and industrial applications, emerging business development, and partnerships for several semiconductor companies.
In his role as Director, Strategic Marketing for Knowles, Raj directs audio solutions strategy, drives venture investments and partnerships, and marketing for IoT and consumer technologies including audio processors, algorithms, microphones, sensors, and receivers. He holds an MBA from Cornell University and a PhD in Electrical Engineering from Georgia Institute of Technology.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: