How to Ensure Safe Performance in RTOS Applications

What you’ll learn:
- How to verify RTOS best practices in runtime.
- How visual trace diagnostics can be used to analyze the software design and detect deviations from best practices.
- What is priority inheritance?
Using a real-time operating system (RTOS) in an embedded design is an increasingly popular choice for system developers. As microcontrollers become more powerful, there’s less overhead for running an RTOS along with other advantages. An RTOS provides multithreading and thereby allows for a more modular system with several smaller programs, each with responsibility for a single function like USB, Display, TCP/IP, or Bluetooth. This makes the code easier to understand and maintain, and when done correctly, can be more efficient.
However, multithreading also brings new challenges in software design, debugging, and testing that call for new software development approaches. These potential problems include priority inversion, memory interference, race conditions, deadlocks, live locks, and starvation.
The key challenge is that the static source code doesn’t give the full picture of the dynamic runtime behavior. For multithreaded systems, the runtime behavior is impacted by interference between tasks and timing variations. As a result, emergent properties that aren’t visible in the source code appear only during execution. These issues can be picked up with sophisticated trace tools that highlight both the operation of the tasks and their interactions over time. This can show where tasks are blocking others or hogging resources.
While the tasks may appear to be independent, they may need to access global resources such as data structures or hardware interfaces, which means the order of global events matters. Variations in how the tasks access these resources may cause race conditions and sporadic errors that are difficult to find in the source code. Using a trace tool makes it possible to identify issues such as race conditions, deadlocks, and priority issues.
Identification via a Trace Tool
Let’s look at a very basic example with two RTOS tasks (Fig. 1). This code might have started off as a single loop design and then the developers ported the application to use an RTOS, but without fully understanding the benefits of an RTOS kernel. One thing we can see in the code right away is that the two tasks are running on the same scheduling priority. Therefore, if both are active at the same time, they will alternate in a round robin manner, with the resolution of the OS tick interrupt. We also notice the delay function in TaskB_Periodic; apparently this task is supposed to run every 10 ms.
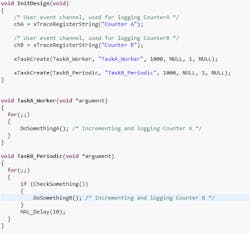
Figure 2 shows a visual trace of the code’s runtime behavior in the Percepio Tracealyzer. On the left is a scheduling trace with a vertical timeline going downward, and in the upper right is a CPU load graph, an overview of how the processor time is distributed between tasks. This diagram has a horizontal orientation, so time flows from left to right.
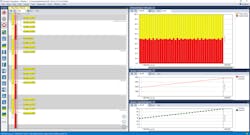
Note that TaskB_Periodic runs 50% of the time. Why is that? We only needed it to run every 10 ms and the code had a delay for that purpose. It turns out that the delay function used, HAL_Delay, isn’t part of the RTOS kernel and doesn’t actually suspend the currently running task. It just blocks the task in a busy waiting loop for the specified amount of time. So, with this implementation, almost 50% of the processor time is wasted.
To fix this, we change the code in TaskB to use vTaskDelay, which is provided by the RTOS. We’ll also raise the priority of TaskB that allows it to preempt TaskA as soon as it wakes up. This way, we can ensure that TaskB can begin executing directly after the vTaskDelay call.
As a result, TaskB now executes every 10 ms, exactly, and only for as long as needed. No busy waiting. Thus, TaskA gets to execute nearly all of the time and we basically doubled the performance of this application by changing just two lines of code (Fig. 3). This is easy to do when you see what’s happening in runtime; otherwise, you might not even be aware of the issue, especially if the code lines in question are scattered deep inside a large codebase.
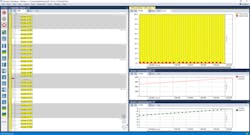
Limit Those Timing Variations
This is a very simple example, but it’s generally true about RTOS-based applications that software timing needs to be as stable and deterministic as possible, which calls for minimizing timing variations. If there are multiple tasks with timing variability and they affect each other, a vast amount of possible execution patterns could cause a chaotic runtime behavior that’s difficult to test and debug with any degree of confidence.
A famous example from the 1980s is the Therac-25 computer-controlled radiation therapy machine. It had numerous software issues, including race conditions, which caused massive overdoses of radiation on at least six occasions. This is an extreme example, but even a well-designed system can occasionally trigger untested execution patterns and produce errors that are nearly impossible to reproduce through static code analysis.
Higher- and Lower-Priority Tasks
Let’s look at another dynamic runtime error that would be all but impossible to detect through code inspection. It’s a fundamental property of an RTOS that higher-priority tasks execute before lower-priority tasks. Low-priority tasks are suspended when a high-priority task knocks on the door and asks for the CPU. Yet, under certain circumstances, the reverse can happen: A high-priority task is forced to wait for a lower-priority task. This problem is known as priority inversion (Fig. 4).
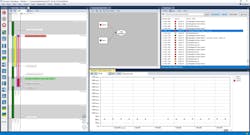
Semaphores are sometimes used to synchronize access to a shared resource. When a task enters a critical section to access globally shared resources, it tries to “take” the semaphore. If the semaphore is already taken, meaning another task is executing the critical section, the RTOS kernel will suspend the task until the other task releases the semaphore.
This relatively common pattern creates a potential problem where a low-priority task holding the semaphore can be preempted by an unrelated medium-priority task. Then all tasks waiting for the semaphore are delayed, even higher-priority tasks. Consequently, a high-priority task must wait for a lower-priority task—in other words, priority inversion.
One high-profile case where a priority inversion caused problems occurred on a NASA spacecraft (Fig. 5). During the Pathfinder mission to Mars in 1997, NASA engineers had overlooked a priority-inversion problem: More than occasionally, a long-running task could block a high-priority task from executing, which then caused a watchdog timer to expire. This resulted in a total system reset during the mission—though the NASA engineers managed to solve the issue in a few days. They were able to reproduce the circumstances on Earth, on a copy of the system, while tracing the system execution and eventually located the problem.

Priority Inheritance
An RTOS feature known as priority inheritance can be used to avoid priority inversions. Inheritance temporarily raises the scheduling priority of the task holding the resource to the same level as the waiting task, which avoids preemptions by middle-priority tasks. This is often provided by mutex objects, which are similar to semaphores but specifically intended for mutual exclusion.
When a high-priority task attempts to take a mutex, it’s still blocked until the holding task releases it. But during this time, the holding low-priority task inherits the priority of the waiting high-priority task. This means a middle-priority task can’t preempt the running task until after it has finished the critical section and released the mutex.
The priority changes can be seen clearly in Figure 6. Without priority inheritance, the middle fragment of the low-priority task wouldn’t have executed (and released the resource) until after the middle-priority task had completed.
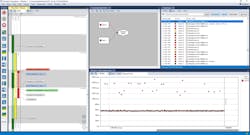
To avoid such problems, many real-time operating systems provide mutex objects where priority inheritance is enabled by default. In the Pathfinder case, the priority inheritance was an option when creating the mutex and the NASA engineers had decided to switch it off to make the mutex operations a bit faster. Apparently, this wasn’t a great idea.
So, using mutexes with priority inheritance to protect critical sections of code, rather than semaphores, can be useful to avoid priority-inversion problems. They may, however, still occur when other shared resources (e.g., message queues) are blocking the execution.
Trace tools such as Tracealyzer provide detailed analysis of a system in operation. Thus, developers can see how tasks are running and how they’re interacting, helping them to identify elusive runtime issues such as priority inversions and thereby enhancing system reliability.
About the Author
Dr. Johan Kraft
CEO/Founder
Dr. Johan Kraft is CEO and founder of Percepio AB. Dr. Kraft is the original developer of Percepio Tracealyzer, a tool for visual trace diagnostics that provides insight into runtime systems to accelerate embedded software development. His applied academic research, in collaboration with industry, focused on embedded software timing analysis. Prior to founding Percepio in 2009, he worked in embedded software development at ABB Robotics. Dr. Kraft holds a PhD in computer science.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: