What’s the Difference Between Conventional Memory Protection and CHERI?

This article is part of the TechXchange: Cybersecurity.
Members can download this article in PDF format.
What you’ll learn:
- How memory safety issues can expose you to very high cybersecurity damage
- How conventional memory protection leaves plenty of vulnerability.
- How CHERI can rigorously prevent some of the worst memory safety issues.
Most semiconductor companies and OEMs take precautions around processor-based systems, which includes secure boot and encrypting communications of important data. However, relatively little attention has been given to memory safety vulnerabilities like buffer overflows or over-reads when designing systems on chip (SoCs).
Such weaknesses have been exploited time and time again, usually at great cost for users and suppliers of systems. For decades, industry has created billions of lines of unsafe C & C++ code. However, addressing the resulting memory safety risks has been discussed little outside software groups.
Memory vulnerabilities are the primary means for an attacker mount a code injection attack or to steal confidential information such as passwords, financial data, or intellectual property. In its “Cost of a Data Breach Report 2023,” IBM estimates the global average cost of a data breach to be $4.45 million. Some vulnerabilities have cost considerably more, for example, the Heartbleed vulnerability in OpenSSL was conservatively estimated to have cost more than $500 million.
Firmware has been an attractive target for attackers in recent years as a successful attack can access hardware downwards and the main OS upwards. National Institute of Standards and Technology’s (NIST) National Vulnerability Database (NVD) showed a fivefold increase in cyberattacks on embedded systems between 2017 and the end of 2022.
In 2021, Microsoft’s Security Signals report showed that 80% of enterprises had experienced firmware attacks in the previous two years. However, the same report indicated that few companies were investing in preventing firmware attacks.
Major software vendors consistently report memory safety problems. For example, Microsoft’s Security Response Center (MSRC) has stated that consistently ~70% of Common Vulnerabilities and Exposures (CVE) reported relate to memory safety. The percentage of reports has remained consistent for almost two decades. The Chromium project and Ubuntu project have reported 70% and 65%, respectively, which is very consistent with Microsoft’s figures.
In addition, reported memory-related CVEs are becoming more numerous. Memory overflow CVEs more than doubled from 844 in 2013 to 1,881 in 2022. Memory corruption CVEs increased almost sixfold in the same period from 577 to 3,420.
Worst still, memory safety issues are consistently among the most severe software weaknesses identified in Mitre Corp.’s Common Weakness Enumeration (CWE) database.1 Indeed, three rank in the top seven by severity:
- Rank 1: Out-of-bounds Write
- Rank 4: Use-After-Free
- Rank 7: Out-of-bounds Read
Three Severe Memory Safety Cases
Let’s consider the three cases listed above in more detail. The out-of-bounds write and out-of-bounds read weaknesses are examples of spatial-memory safety vulnerabilities. Use-after-free is a temporal vulnerability. All of these vulnerabilities concern the use of pointers, which are integers containing the address of a location in memory.
1. Out-of-bounds write—also known as buffer overflow
Data structures such as arrays or strings are implemented in memory as bounded sequences of bytes known as buffers. Out-of-bounds writes or buffer overflows occur when a process attempts to write data outside the defined bounds of the buffer. The result is that data is written into an area used for some other purpose, resulting in the corruption of that memory. The damage varies depending on how the adjacent memory is being used.
In the simplified example in Figure 1, a buffer is intended to have size 8 and is adjacent to a data area. If the buffer overflows to a data area, then it’s likely that any program using such corrupted data may behave in an anomalous way or perhaps even crash.
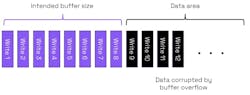
If the overflow is to an area containing executable code, then the vulnerability could allow a code injection attack (Fig. 2). In Figure 1, if the area of memory next to the buffer is used for executable code, then the buffer overflow can be used to write malware into the executable code area.
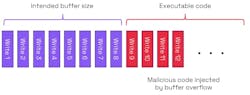
A specific type of attack is known as “stack smashing,” as it deliberately causes a stack overflow. Overflows of buffers on a stack can be exploited to overwrite local variables, return addresses, and function pointers. Such overwriting can be used to point to malware rather than trusted code. Other attacks aim to corrupt the heap by applying buffer overflows to overwrite data structures such as linked list pointers.
2. Out-of-bounds read
The converse of an out-of-bounds write is an out-of-bounds read. In this case, a program requests data from outside the buffer bounds. Because the data that’s read from outside the buffer has nothing to do with the program using the buffer, it could potentially cause a program to crash or behave strangely. Worse still, it’s another mechanism for breaching security.
In the example shown in Figure 3, we again have an intended buffer size of 8, but it’s adjacent to data memory containing confidential information. If the program reads beyond the bounds of the buffer, it will start accessing unrelated confidential data.
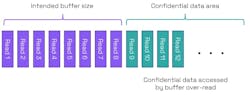
Buffer over-reads have caused real-world cyberattacks, with a well-known example being the Heartbleed vulnerability in OpenSSL. Examples of damage from Heartbleed include:
- Compromising 4.5 million patient records at the Community Health Systems hospital chain.
- Many web-based customer accounts compromised and needing new passwords.
- A single hacker stealing 900 social security numbers from the Canadian Revenue Agency in a short period.
eWeek estimated that the total cost to industry to recover was $500M+. The vulnerability was made public in early April 2014 and a fixed version of OpenSSL was released the same day. However, in January 2017, 180,000 connected devices were still vulnerable almost three years later!
Even today there may be enterprise systems that aren’t correctly patched, according to a blog by TuxCare. They say that there may be uncertainty over which libraries have been patched and inconsistent patching. If just one library isn’t correctly patched, then an organization is vulnerable.
3. Use-after-free
Memory locations can contain different data at different times during program execution. Temporal vulnerabilities relate to when, say, a program uses a certain memory location using a pointer, then later frees the memory and subsequently tries to use the pointer again when it’s no longer valid.
Trying to use a so-called “dangling pointer” is referred to as a “use-after-free” bug. It was a common problem for the Chromium project, accounting for 36.1% of CVEs reported. Temporal vulnerabilities may result in unpredictable behavior as well as being exploitable by hackers. Use-after-free bugs can also lead to memory leaks.
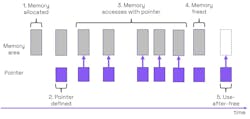
In Figure 4, the following takes place:
- A memory area is allocated using malloc().
- A pointer is defined to address the memory.
- The pointer is used to access the memory.
- The memory is freed using free().
- The pointer is used-after-free.
A similar situation arises if memory is allocated in a function and a pointer is defined to address it. Memory is automatically freed on returning from the function. However, unless the pointer is explicitly set to NULL, it will be a dangling pointer.
It’s important to initialize and then disable pointers consistent with memory allocation and deallocation.
Unsafe Programming: The Root Cause of Memory Vulnerabilities
To understand why memory safety issues are so widespread, it’s necessary to look into how software is developed, and the risks associated with common programming languages.
Software provenance
Before considering programming languages it’s important to remember that most applications today are assembled from multiple code sources (Fig. 5).
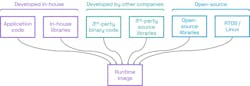
Some software will be developed in-house, whether in the form of application-specific code or in-house libraries. Frequently, third-party software is used for communication protocol stacks and cryptographic algorithms. Many companies rely on open-source libraries and operating systems.
Checking the provenance and programming quality of all sources is generally not practical. Source code also isn’t reviewable when software is supplied as binaries.
C and C++ languages
A huge body of code is written in C and C++, with over 13 billion lines of code on GitHub alone. These languages offer tremendous control over memory, but since memory management is manual, there are great risks of making errors.
The languages were developed when memory was very expensive and having manual control of memory allowed for programmers to achieve better performance with available resources. In the case of C, there were some missing features, including arrays, strings, and writeable function parameters. These limitations have been overcome by using pointers.
Pointers
Pointers are integer variables that handle addresses in memory efficiently and with good performance. By performing operations on the pointer, it’s possible to operate easily on arrays or strings. However, pointers are also used for very different purposes, making it challenging to read C code at times. When a variable is accessed in C, it’s copied into the call stack. But if a variable is large, such as a big array or string, it’s only necessary to copy the pointer rather than the entire variable.
Memory allocation and sizing
To allocate memory, e.g., for a string, the programmer must estimate the amount of memory needed. Of course, if a longer string is required than allocated, then it’s possible to make a new memory allocation and subsequently copy the contents character by character to the new memory before freeing the old one. In practice, programmers have sometimes used guesswork to size their arrays and strings, have not coded bounds checks, and have thus simply hoped for the best.
Pointers use generic integers; there are no automatic bounds checks with C/C++ languages (Fig. 6). Thus, it’s easy to inadvertently create an over-write or over-read. The same applies to temporal problems such as use-after-frees. Lastly, pointers are forgeable, as they can be corrupted. This means that pointers are both powerful and dangerous.
Conventional Approaches to Making Memory Accesses Safer
Given that software tasks need to be protected from buggy or malicious behavior of other tasks, privilege modes, memory protection, and software schemes have been devised to protect memory accesses.
Typically, a CPU has privilege modes defined to protect CPU resources from dangerous usage. In RISC-V, three privilege modes are defined in increasing order of control: user-mode (U-mode), supervisor-mode (S-mode), and machine-mode (M-mode).
Privilege modes help define access to CPU resources, reducing the opportunity to abuse them through malware or buggy programming. They can be regarded as providing a vertical separation between modes.
The RISC-V privileged architecture provides for defining up to 64 physical memory regions. Physical memory access privileges—read, write, execute—can be specified for each region (Fig. 7) by means of machine-mode control registers. This type of memory protection can further be used to separate memory into enclaves or execution environments to separate secure tasks from unsecure ones. This would be implemented in hardware using physical memory protection (PMP).
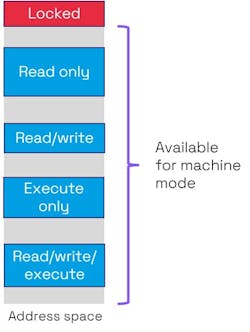
A memory management unit (MMU) also offers memory protection by organizing the memory into pages of a fixed size. This not only can support virtual memory, but it means that pages are isolated from each other, limiting the harm that one process can inflict on another.
Neither an MPU nor an MMU on their own can distinguish between the trust level of the processes that are running. However, defining execution environments can distinguish between trusted and non-trusted processes.
Execution Enclaves
The best-known example of separate execution enclaves is the binary separation into trusted execution environment (TEE) and rich execution environment (REE) as promoted in the mobile phone world.
Memory protection helps ensure that trusted firmware and secure applications have their own memory area and hardware resources. Together, these hardware and software elements constitute the TEE. A rich OS (such as Android) and non-secure applications have access to a separate memory area, forming the REE. If software in the REE area needs to communicate with the secure TEE area, then a well-defined interface is provided.
This separation can be regarded as horizontal in contrast to the vertical separation of privilege modes. More sophisticated schemes have been proposed using more than two enclaves, but the principle of horizontal separation still applies.
Conventional memory protection can ensure that certain processes are accessing separate memory enclaves. However, it fails to deal with finer-grained problems such as checking memory bounds during reads and writes.
Stack Canaries
A well-known example of mitigating memory unsafety with software is the stack canary. If a program is executing and calls a subroutine, the address of the next instruction in the program is pushed onto the call stack and used as a return pointer (RP). When the subroutine finishes execution, the return address is popped from the call stack.
In the event of a buffer overflow, the RP will be overwritten. The RP could end up with corrupt content or, in the event of an attack, could point to malware. A stack canary—analogous to using canaries to detect gas in mines—is a known set of values placed between the stack and the RP (Fig. 8). These values are used to detect a buffer overflow.
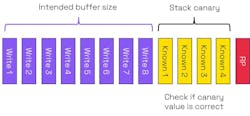
The compiler will define the values to be stored in the stack canary, and those that will normally be randomized. After running the subroutine, if the values in the stack canary don’t match the expected ones, it means that the stack canary has been corrupted. The return will not be executed, and the program will terminate. The canary comes with a memory overhead, but this overhead is relatively small.
Stack canaries suffer from being statistical, meaning that a hacker could exhaustively go through possible values to attack a stack. They’re also susceptible to information leakage.
In a recent Zero Day Initiative (ZDI) meeting in Toronto, there was a competition to investigate the security of commonly used devices. A team compromised the Netgear Nighthawk RAX30 by using a buffer overflow attack. Although the router used a stack canary, they found a way to cause damage before the corrupted canary value was checked, compromising the router and potentially other connected devices. Stack canaries are an example of a coarse-grained software approach to mitigating memory safety.
CHERI Fine-Grained Memory Protection in Hardware
Capability Hardware Enhanced RISC Instructions,2 or CHERI, aims to deal with severe memory safety issues using hardware combined with software. The concept is ISA-independent; the University of Cambridge has created experimental versions for MIPS, Arm v8-A, RISC-V, and x86. CHERI requires the use of additional instructions to handle capabilities as well as extra microarchitectural features.
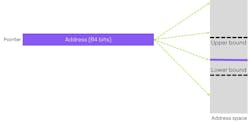
Fundamental to the CHERI approach is to replace pointers with architectural capabilities (Fig. 9). These explicitly handle permissions and use the upper and lower bounds of buffers. Moreover, there are explicit permissions, object types, a sealing flag, and a one-bit tag, which indicates the validity of the capability. The sealing flag makes a capability immutable from further modification, but it can be unlocked by specific instructions such as jump instructions. A capability can be regarded as a "smart pointer."
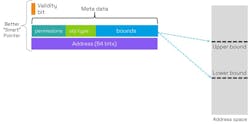
Unlike a pointer, the way in which the capability can be utilized is defined. For example, instruction fetches could be prohibited or loads and stores may be restricted. The object type can be used to “seal” a capability, which means that it can’t be either de-referenced or modified. Finally, lower and upper bounds are defined in the address space for which permitted loads, stores, and instruction fetches are permitted.
CHERI defines rules governing changes to capability metadata. Valid capabilities may only be constructed explicitly from existing valid capabilities using CHERI instructions. Furthermore, when a new capability is constructed, the bounds and permissions may not exceed those of the capability from which it’s derived. These rules are called “provenance validity” and “capability monotonicity,” respectively. A capability therefore acts as an unforgeable token, making it far more robust than a pointer.
During a secure boot, the CHERI architecture initializes the capabilities in hardware, allowing for full address space instruction and data fetching. Further capabilities are derived as part of a chain of trust from firmware to boot loader to OS to application. On top of that, the capability validity tag bits in memory are cleared as part of the boot.
With the bounds of the buffer explicitly included in the metadata, capabilities can be used to deterministically check for buffer bound violations (Fig. 10). This fine-grained memory protection is much more robust than statistical methods like stack canaries or lock/key memory tagging.
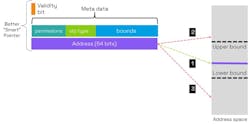
CHERI capabilities can potentially be used to detect use-after-free faults by adding more software and page table enhancements. For example, the Cornucopia capability revocation system3 quarantines free()-d memory and periodically sweeps memory to identify and remove capabilities that permit access to free()-d memory. Note that this approach to capability revocation is deterministic, not statistical.
To implement CHERI on a processor core, it’s necessary to add CHERI instructions and microarchitectural features. Experimental processors have been created using MIPS, Arm, RISC-V, and x86 ISAs. Recently, Codasip announced that CHERI technology was designed-in from the start of its commercial quality 700 series application core development.
From the outset, CHERI has been designed to accommodate legacy C/C++ code. To take full advantage of CHERI’s memory safety features, it’s necessary to recompile code using a CHERI compiler. Nevertheless, a CHERI-compatible processor will be able to run standard C/C++ binaries but without the CHERI features.
CHERI can even complement memory-safe languages like Rust by providing robust runtime memory protection and protecting code that’s declared unsafe. It also allows for "hybrid" code protection, where legacy code is used in combination with memory-safe code by utilizing compartmentalization.
Conclusion
Memory safety problems are widespread and can cause significant security breaches and consequent economic damage. However, they’re rarely discussed by SoC developers, although SoC users and their OEM customers are at risk. Three of the seven most severe CWEs are caused by unsafe usage of pointers.
The underlying cause for these CWEs is that C/C++ don’t check to see if pointers respect the bounds of the data structures that they access. Existing hardware memory protection (MPUs and MMUs) provide coarse-grained protection by limiting access to memory regions to certain tasks. Still, this doesn’t protect against unsafe memory access within a task.
Similarly, software methods to keep memory accesses safer, such as stack canaries, are statistically based and can be hacked.
While memory safe languages provide safety for new code, in practice most software is assembled from in-house, commercially licensed, and open-source libraries. Neither exhaustively checking all code sources nor rewriting all code in a memory safe language is economically feasible.
CHERI provides a hardware solution to memory safety by offering fine-grained memory protection. Pointers are replaced with architectural capabilities that can exhaustively check that buffer bounds are respected. If a processor has CHERI instructions and microarchitectural features, most C/C++ code simply needs to be recompiled with little or no modification using a CHERI-compatible compiler to benefit from enhanced memory safety.
Read more articles in the TechXchange: Cybersecurity.
References
1. “Stubborn Weaknesses in the CWE Top 25,” Mitre Corporation.
2. Robert N. M. Watson, Simon W. Moore, Peter Sewell, Peter G. Neumann, “An Introduction to CHERI,” Technical Report UCAM-CL-TR-941, University of Cambridge, September 2019.
3. Nathaniel Wesley Filardo et al, “Cornucopia: Temporal Safety for CHERI Heaps,” 2020 IEEE Symposium on Security and Privacy.
About the Author

Roddy Urquhart
Senior Technical Marketing Director, Codasip
Dr. Roddy Urquhart joined Codasip in 2020 and is responsible for technical marketing. Previously, he has worked in the semiconductor industry in a variety of roles including IC design, application engineering, professional services management, and marketing. Before Codasip, he was with GEC Research, Mentor Graphics, Synopsys, and Cortus.
He holds a B.Sc. degree in Electronics and Electrical Engineering and a Ph.D. in pattern recognition, both from the University of Glasgow.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: