Memory Partitioning and Slack Scheduling Boost Performance in Safety-Critical Applications

The ability to guarantee that critical tasks have sufficient time to execute is essential for ensuring system integrity and safe operation in safety-critical systems. For developers, managing shared memory resources is key to minimizing worst-case execution times (WCET) for critical tasks.
On-chip cache allows processors to run at on-chip memory bus speeds and increases overall compute power. However, task switching and competition for cache resources can degrade cache performance and dramatically increase WCET. Benchmarks show that WCET can be three times higher than average-case execution time (ACET) on single-core processors and an order of magnitude (or more) higher on multicore processors.
By utilizing cache partitioning, real-time operating systems (RTOSs) such as DDC-I’s Deos can help programmers isolate safety-critical tasks from detrimental cache effects, reducing WCET, increasing the overall CPU time available for time-critical tasks, and streamlining safety certification. Meanwhile, support for slack scheduling enables programmers to harvest the unused time budgeted to time-critical tasks, boosting CPU utilization and performance.
The Setup
Cache maximizes processor performance by enabling programs to utilize high-speed on-chip memory. That advantage, however, only exists when the data for the executing task resides in the cache. Often, during heavy task switching, portions of the cache that were utilized by previous tasks (and now used by the new task) will be written back to main memory and repopulated with data for the new task.
This must happen before the CPU can access memory at chip speeds again. The more frequent the task switching, the greater the overhead for loading and reloading the cache, and the longer the task execution time. The problem is even worse on a multicore processor because no longer is the major impact limited to context switches. Now, multiple cores running multiple tasks may compete for shared cache.
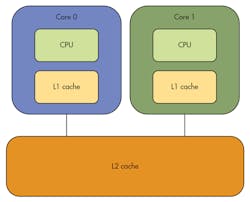
A typical dual-core processor configuration has each core with its own CPU and a small L1 cache (Fig. 1). Both cores share the large L2 cache. Applications executing on Core 0 compete for the entire L2 cache with applications executing on Core 1. (Note that applications on the same core also compete with one another for the caches.) If application A on Core 0 uses data that maps to the same cache line or lines as application B on Core 1, then a collision occurs and must be corrected by the hardware.
Suppose application A’s data resides in L2, and B accesses data that happens to map to the same L2 cache line as A’s data. At that point, A’s data must be evicted from L2 (including a potential “write-back” to RAM), and B’s data must be brought into cache from RAM. The time required to handle this collision increases B’s execution time. Then, suppose application A accesses its data again. Since that data is no longer in L2 (B’s data is in its place), B’s data must be evicted from L2 (including a potential “write-back” to RAM), and A’s data must be brought back into cache from RAM. The time required to handle this collision increases A’s execution time.
Typically, A and B will encounter collisions infrequently, and their execution times will be average case (ACET). Occasionally, however, their data accesses will collide at a high frequency, and the worst-case scenario will occur (WCET). This scenario may occur infrequently. Yet developers of certifiable, safety-critical software must budget application execution time for worst-case behavior, as safety-critical tasks must have adequate time budget to complete their intended function every time they execute. With the potential for multiple applications on multiple cores to generate contention for L2, WCETs on multi-chip packages (MCPs) are often considerably higher than ACETs. This leads to a great deal of budgeted but unused time, resulting in significantly degraded CPU availability for time-critical tasks.
This file type includes high resolution graphics and schematics when applicable.
Cache Partitioning
Cache partitioning makes it easier to bound and control interference patterns by reducing L2 cache contention, reducing WCET and increasing CPU utilization. By setting aside dedicated sections of the cache for critical tasks (or groups of tasks), developers can reduce interference and provide timely, deterministic access to cache. This reduces WCET, decreasing the amount of time that must be budgeted for critical tasks and maximizing the guaranteed execution time available to safety-critical tasks.
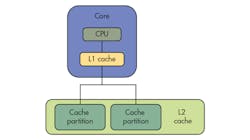
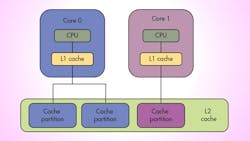
In single-core operation, a large L2 cache can be separated into multiple partitions, allowing developers to isolate critical tasks from non-critical tasks (Fig. 2). In a multicore configuration, the L2 cache may be partitioned so each core has its own partition or partitions and data used by applications on Core 0 will only be cached in Core 0’s L2 partitions (Fig. 3). Similarly, data used by applications on Core 1 will only be cached in Core 1’s L2 partitions.
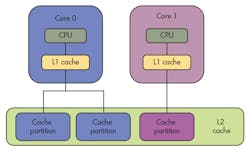
This partitioning eliminates the possibility of applications on different cores colliding with each other when accessing the L2 cache. Limiting cache interference in this way reduces each application’s WCET, bringing it closer to its ACET. It also makes application execution times more deterministic, which enables time budgets to be set more tightly, keeping processor utilization high for time-critical tasks.
Test Environment
To verify the efficacy of cache partitioning, actual flight software was used as a test application. The resultant execution times were measured over 1600 frames. The tests were run in single-core mode, which limits the cache impact on critical tasks to context switches.
Also, the tests were run with and without a cache trasher application, which evicts test application data/code from L2 and dirties L2 with its own data/code. In effect, the cache trasher puts L2 into a worst-case state in which multiple applications run concurrently and compete for the shared L2 cache.
Each test application was executed under multiple scenarios.
In scenario 1, the test application competes for the entire L2 cache along with the RTOS kernel and a variety of tools. There is no cache partitioning or cache trashing. This test establishes baseline average performance. Each test executes with average to minimal L2 contention.
Scenario 2 also omits cache partitioning, but adds cache trashing. Here, the test application competes for the entire L2 cache along with the RTOS kernel, a variety of debug tools, and the rogue cache trasher. This test establishes baseline worst-case performance. Each test executes with worst-case L2 interference from other applications, primarily the cache trasher.
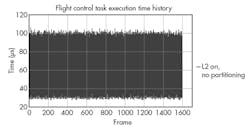
Scenario 1 sets the lower band limit. Scenario 2 sets the upper band limit (Fig. 4). The area between scenario 1 and scenario 2 represents the normal execution band of a fully loaded system. Scenarios 3 and 4 are the same as scenarios 1 and 2, respectively, except the L2 cache is turned off. The red band in Figure 5 shows the performance impact.
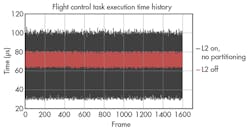
Scenario 3 sets the low end of the band, scenario 4 the high end of the band. The area between represents how a typically loaded system would be expected to perform if the L2 cache was turned off. Note that best-case scenario 3 performance declines with respect to scenario 1 due to the disabling of the L2 cache. Meanwhile, the worst-case response time for scenario 4 (WCET) improves with respect to scenario 2, as the performance penalty of the cache trasher is limited to the L1 cache.
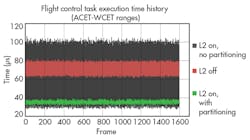
Scenarios 5 and 6, depicted by the green band in Figure 6, add cache partitioning. Partitioning the L2 cache among applications reduces the amount of cache available to each application, reducing average performance. At the same time, though, partitioning the cache also reduces cache contention, which bounds worst-case execution. Cache partitioning strikes a balance, then, enabling applications to benefit from the cache, but in a way that drastically reduces WCET.
It is possible for applications executing in the same cache partition to interfere with each other. However, such interference is much easier to analyze and bound than the unpredictable interference patterns that can occur when applications executing on one or more cores share an entire cache. If necessary, in those situations, applications could be mapped to completely isolated cache partitions.
The benchmark results clearly demonstrate that cache partitioning provides an effective means of bounding and controlling interference patterns in shared cache. Though the benchmarks are run on a single-core processor, the results would only be amplified if the benchmarks were run on a multicore CPU, where multiple cores would contend for the same shared cache during normal process execution. Initial testing on multicore systems shows measured WCET diverging from ACET by a factor of 10 or more when cache partitioning was not used.
Ultimately, worst-case execution times are bounded and controlled much more tightly when the cache is partitioned. This enables application developers to set relatively tight yet safe execution time budgets for the tasks, maximizing processor utilization in both single-core and multicore devices.
Slack Scheduling and Using Slack
Slack Scheduling
Slack scheduling builds on the performance improvement realized through cache partitioning by harvesting the unused time budgeted to time-critical tasks. While cache partitioning reduces the delta between WCET and ACET, time-critical tasks will on average still use less time than they are budgeted. Slack scheduling enables that unused time to be recouped on the fly and make it available to other threads.
At the beginning of any given period or major frame, there is a set of threads (say T1 – Tn) that are ready to run or will become ready to run. There is also a certain amount of unbudgeted time known as headroom or room for growth. Deos takes this unbudgeted time, say 5 ms, and puts it into a slack pool. Think of the slack pool as an account for banking slack time. Deos then starts scheduling threads and gives them control of the CPU.
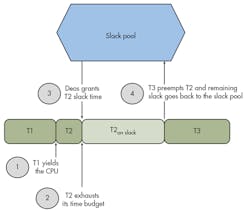
Let’s say that Deos gives control to T1 first and that T1’s WCET time budget is 600 µs (Fig. 7). Let’s also assume that T1 executes and hits its ACET, say 400 µs. Deos will take the remaining 200 µs and add it to the slack pool, increasing the total slack in the pool to 5.2 ms.
Next say that Deos schedules T2 and that T2’s WCET time budget is 200 µs. Further assume that T2 has been declared slack enabled. Once given control of the CPU, assume that T2 uses its 200-µs time budget. If T2 does not yield the CPU (or is not pre-empted), Deos will intervene, noting that T2 is slack enabled, and add the 5.2-ms time in the slack pool to T2’s time budget. T2 can then continue executing on slack time until it exhausts its slack adjusted budget, yields the CPU, or is pre-empted by a higher priority thread like T3. In the latter two cases, any remaining budget is donated back to the slack pool.
Using Slack
So, how does one use slack in a safety-critical system? After all, slack time may not be available when a slack-enabled thread could use it. Further, Deos makes no fairness guarantees regarding allocation of slack. That said, there are ways that slack can be effectively used in certified, safety-critical systems.
Some threads, for example, are simply non-critical. (In DO-178B terminology, they’d have a design assurance level of E.) These threads (e.g., built-in-test) are pure slack consumers. In other words, they have no allocated time budget and run purely on slack.
Other threads fall into the quality-of-service category. They have to meet a minimum performance level, but if time is available, they can provide a better result. A moving map display is a good example. On one aircraft, system safety analysis and human factors showed that the display had to be updated at a 10-Hz rate to avoid jerky movement that could induce eye fatigue in pilots. But even at 10 Hz, the update wasn’t particularly smooth.
The solution was to give the moving map thread enough time to ensure a 10-Hz update rate, but also designate it as slack enabled. By utilizing slack, the thread was able to achieve a 20-Hz or better update rate almost all the time. Consequently, the moving map was very smooth, and pilots loved it.
Slack is also ideal for what are sometimes called anytime algorithms. These algorithms produce good answers in a given amount of time, but produce better answers if given more time. For example, the more time an interpolation algorithm is given to iterate, the more precise the answer it will yield. Again, allocate enough time to generate a “good enough” answer, and use slack when available to generate a better answer.
Slack scheduling is not simply background processing, though it can be used that way. The key distinction is the ability to dispense slack time throughout a period rather than to save it up for use at the end of a period. This distinction enables much more interesting and useful features.
The ability to recover and utilize slack is essential for real-time safety-critical systems, where the need to budget for worst case versus average execution times makes it difficult to utilize available CPU cycles. Slack scheduling is particularly important for multicore systems, where contention for cache and other memory resources greatly increases WCET. Cache partitioning helps alleviate this contention, but the ability to reuse slack is crucial for unleashing the full potential of multicore processors in safety-critical applications.
This file type includes high resolution graphics and schematics when applicable.
Greg Rose is the vice president of product management and marketing at DDC-I. He has over 30 years of experience in marketing, product management, business development, and engineering in embedded software, hardware, and intellectual property licensing. He is a graduate of the Iowa State University, where he earned a BS in electrical engineering.
About the Author
Greg Rose
Vice President of Product Management and Marketing
Greg Rose is the vice president of product management and marketing at DDC-I. He has over 30 years of experience in marketing, product management, business development, and engineering in embedded software, hardware, and intellectual-property licensing. Greg is a graduate of the Iowa State Univ., where he earned a Bachelor of Science in electrical engineering.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: