What’s the Difference Between an In-Memory Data Grid and In-Memory Database?

Download this article in PDF format.
Increasingly, companies are facing performance and scalability issues for their applications. Users want fast, real-time, and trusted data to make enhanced business decisions, while technology management wants to lower cost and improve operational efficiency.
Despite technical improvements over the years, such as processors or processor cores doubling and quadrupling, enterprises still face unpredictable workloads, increasing data volume and usage, and poorly designed applications. Performance will continue to top the list of data challenges as organizations look to manage growing data volumes, eradicate latency in response times, integrate fragmented data, and juggle data-platform complexity.
What’s an In-Memory Data Grid (IMDG)?
IMDGs are designed to provide high availability and scalability by distributing data across multiple machines. The rise of cloud, social media, and the Internet of Things (IoT) has created demand for applications that need to be extremely fast and capable of processing millions of transactions per second.

Hazelcast’s IMDG 3.9 in-memory computing platform.
After testing, the Hazelcast IMDG was revealed to be the fastest open-source IMDG (Redis 3.2.8/Jedis Client 2.9.0 vs Hazelcast IMDG 3.8 Benchmark), and thus gives applications the capability to quickly process, store, and access data with the speed of RAM. To quickly summarize, Hazelcast shards and distributes data across a cluster of servers, its characteristics are as follows:
- The data is always stored in-memory (RAM) of the servers.
- Multiple copies are stored in multiple machines for automatic data recovery in case of single or multiple server failures.
- The data model is object-oriented and non-relational.
- Servers can be dynamically added or removed to increase the amount of CPU and RAM.
- The data can be persisted from Hazelcast to a relational or NoSQL database.
- A Java Map API accesses the distributed key-value store.
Hazelcast’s IMDG can be used in various ways, depending on an organization’s deployment strategy, security concerns, or usage patterns. For instance, it can be used as a client-server or an embedded architecture—it’s easy to deploy and brings a resilient and elastic memory resource to all applications. It’s currently seeing broad usage, with hundreds of thousands of installed clusters and over 23 million server starts per month.
Many companies that historically would not have considered using in-memory technology because it was cost-prohibitive are now changing their core systems’ architectures to take advantage of the low-latency transaction processing possible with in-memory technology. In part, this is due to the price of RAM dropping significantly – it has become economically feasible to load the entire operational dataset into memory with performance improvements of over 1000x faster.
So, What’s an In-Memory Database (IMDB)?
An IMDB is a database management system that primarily relies on main memory for computer data storage. It contrasts with database management systems that employ a disk-storage mechanism. An IMDB eliminates the latency and overhead of hard-disk storage and reduces the instruction set that’s required to access data.
Traditional database management systems move data from disk to memory in a cache or buffer pool when accessed. Moving the data to memory makes re-accessing the data more efficient, but the constant need to move data can cause performance issues. Because data in an IMDB already resides in memory and doesn’t have to be moved, application and query performance can be significantly improved.
IMDBs are most commonly used in applications that demand very fast data access, storage, and manipulation, and in systems that don’t typically have a disk but nevertheless must manage appreciable quantities of data.
They Sound Pretty Similar to Me… What’s the Difference?
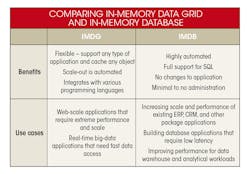
The distinction between an IMDG and IMDB is fairly technical. Data grids tend to use key-value stores as embedded objects on a Java Virtual Machine (JVM), while in-memory databases are optimized for columnar storage. In essence, IMDGs offer a memory fabric that can be used by popular programming languages, such as Java or .NET, to support any application needs. IMDBs, on the other hand, store frequently accessed data or all application data in-memory to support database applications and other workloads.
Forrester defines an IMDB as “database technology that stores either all or partial data in DRAM, either on a single server or distributed across multiple nodes in a cluster to support transactional, analytical, or predictive workloads.” And it defines an IMDG as “data architecture where data is distributed in-memory, SSD, or Flash across many nodes in a cluster that delivers a unified data platform. In-memory data grid allows the flexibility to store, process, and access application objects, data, and metadata using popular programming languages, such as Java and .NET.”
Summing Up
In summary, use an IMDG to accelerate development and deployment of custom applications. IMDGs help accelerate the development of apps that need extreme low-latency data access to critical data. These solutions can scale-out horizontally to deliver unlimited in-memory to support any application.
Use an IMDB to accelerate online transaction processing (OLTP) and online analytical processing (OLAP). IMDBs can dramatically improve performance of existing or new databases that support large mission-critical applications, such as ERP, CRM, SCM, and other OLTP applications. It can also improve performance for data warehouses and analytical workloads by delivering a caching layer.
However, be aware that an IMDB has limitations. The technology was designed to scale up (to add more resources to an existing node), whereas an IMDG is designed to scale out (to add more nodes). For web and mobile apps dealing with concurrent processes, complex queries, or more transactions, the scale-up architecture can reach a breaking point. For scenarios that demand performance, scalability, and reliability, and can manage multiple tens of terabytes across tens or hundreds of servers, scale-out architectures are better supported by IMDGs.

About the Author
Christoph Engelbert
Manager of Developer Relations
Christoph Engelbert is Manager of Developer Relations at Hazelcast. He is a passionate Java developer with a deep commitment for open-source software. Christoph is mostly interested in performance optimizations and understanding the internals of the JVM and the Garbage Collector. He loves to bring software to its limits by looking into profilers and finding problems inside of the codebase.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: