Build Edge AI Systems Using eFPGA Technology


Members can download this article in PDF format.
What you’ll learn:
- The growing role of AI in modern electronic systems.
- How artificial neural networks leverage AI to serve applications.
- How to use eFPGA IP to efficiently deploy edge AI systems.
Artificial intelligence (AI) continues to rapidly evolve and impact more industries on a global scale. From autonomous cars to virtual personal assistants, AI has increasingly integrated into our daily lives. In particular, the use of AI at the edge is becoming widespread, as it enables real-time processing of data near the sensor rather than relying on centralized data centers. Such edge execution of AI allows for a reduction in latency, connectivity dependency, energy consumption, and cost.
Indeed, several hardware options are available for processing data in real-time, such as the central processing unit (CPU), graphical processing unit (GPU), field-programmable gate array (FPGA), system-on-chip (SoC) and application-specific integrated circuit (ASIC). Each of these technologies has its own advantages and disadvantages, and the choice depends on the specific requirements of the target application.
This article delves into details about these technologies and discusses their advantages and disadvantages in the context of edge AI systems. It also shows how the use of embedded FPGAs (eFPGAs) in a SoC or an ASIC represents a very promising solution for deploying AI and other edge applications. And there’s a brief history, along with the basics, of artificial neural networks, as well as a description of how to efficiently use the Menta eFPGA IP to deploy them at the edge.
Artificial Neural Networks at the Edge
Artificial neural networks (ANNs) are the most commonly used models for AI applications. They’re inspired by the structure and functioning of biological neural systems. ANN algorithms have become more popular with applications in several domains, such as object detection, image segmentation and classification, medical image analysis, and natural language processing.
Such success can be attributed to two factors. First, there’s the high-performance computing capabilities of today’s machines based on CPUs/GPUs, which enhanced the training and inference stages of ANNs. Second, a huge amount of open-source labeled data is available to researchers and developers to train and test different deep-neural-network (DNN) models for a variety of applications, thus contributing to their continuous improvement.
Nowadays, the most known AI techniques are deep-learning algorithms, which consist of convolutional neural networks (CNNs), autoencoder (AE), recurrent neural networks (RNNs), spiking neural networks (SNNs), and others. At the end of 1998, Yann LeCun proposed one of the first CNNs, called LeNet, which is applied to a handwritten character recognition task. Figure 1 shows the architecture of the proposed CNN; the different components and layers will be discussed in the following sections.

Since then, CNNs have aroused great interest in the scientific community for image processing. In the early 2000s, the development of the internet allowed for the creation and sharing of many databases of well labeled and structured datasets in various application fields, which led to advanced learning techniques and ANN models.
In 2012, Krizhevsky et al. introduced AlexNet, a DNN that won the ILSVRC challenge with a significant deviation from the results achieved so far. The following year, Zeiler and Fergus won this challenge by proposing an optimization of AlexNet that they called ZFNet.
Szegedy et al. were the winners of the 2014 ILSVRC. They introduced the "inception" modules, reducing the number of parameters in their GoogLeNet by a factor of 15 compared to AlexNet. In the same year, Simonyan et al. of the Visual Geometry Group at Oxford University proposed VGG-like networks using reduced-size convolution kernels (3x3) and won second place in the classification category of the 2014 ImageNet Challenge.
In 2015, He et al. introduced the notion of residues with ResNets, very deep CNN architectures comprising more than 100 layers with interconnections between them. In this context, in 2016, Huang et al. generalized the notion of residue with DenseNet, a network structure with all layers interconnected, thus eliminating the gradient attenuation problems encountered with very deep networks.
From 2016 onward, many works have reduced the complexity of CNN architectures for integration in mobile applications, such as SqueezeNet in 2016, mobileNet V1 in 2017, and then mobileNet V2, NasNet, and EffNet in 2018.
Classification of Neural Networks
Artificial neural networks consist of artificial neuron units that are connected to each other through weighted synapses following various network topologies. ANNs can be classified into several categories, depending on their network topology, data structure and type, and use cases. Examples of the most frequently addressed categories include:
Feedforward neural networks: Best suited for regression and classification tasks, these networks forward input data through multiple processing neural layers without any feedback loops. Examples of feedforward ANNs include the multilayer perceptron (MLP) and CNNs.
Recurrent neural networks (RNNs): Better at time series prediction and sequence modeling through enabling information to be memorized and loop back through the network. In this category, we can cite the simple recurrent neural networks (SRNNs) and long-term memory networks (LSTMs).
Autoencoding (AE) neural networks: Well-suited for feature extraction and dimensionality reduction, they learn to encode input data into a lower-dimensional representation and then decode it into its original size. Within this category, one can cite standard autoencoders, convolutional autoencoders, and variational autoencoders.
Generative adversarial networks (GANs): They generate new data by training two different networks in a game-like fashion, where one network tries to generate new data and the other tries to predict whether it’s real or generated. Examples include vanilla GANs, conditional GANs, and deep convolutional GANs (DCGANs).
Spiking neural networks (SNNs): Unlike traditional ANN categories that use continuous values, SNNs use discrete spikes to represent information and adopt a different computational paradigm. The fact that spiking data is discrete makes SNNs more hardware-friendly than traditional ANNs, but they’re less mature due to their unpopularity.
Feed-Forward Neural Networks
We focus on feed-forward ANNs because they’re the most commonly used AI algorithms. This section describes the functioning and structure of feedforward ANNs by going through MLP and CNN networks and their layer types, and then differentiate learning and inference phases.
Multilayer perception (MLP)
Before presenting CNNs, we can cite the MLP, which is a network composed of an input layer and an output layer and one or several hidden layers. The input layer consists of neurons that transmit input data to the first hidden layer without any computation, acting as buffers. The output layer contains the neurons that represent the different classes of the data recognized by the MLP. Each layer has a number of perceptron neurons that are fully connected to those of its previous layer.
Convolutional neural network
A CNN is quite similar to the MLP, but it has other layer types such as convolutional, pooling, and fully connected layers. The fully connected layers are the same as the hidden layers found in MLPs. Figure 2 shows an example of such a CNN network consisting of convolutional, pooling, and fully connected layers.

A convolutional layer is composed of convolution filters that are applied to an input feature map (FM) to perform some feature extraction. Each filter has its singular synaptic weights that are determined during the learning phase. Those are applied to a given position on the input FM “I” as shown in Figure 3. Applying the filter to the whole input FM results in an output FM whereby the size corresponds to the number of positions.
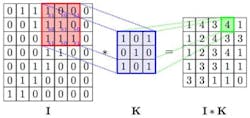
The computation held within the convolution filter consists of multiplying its weights (blue matrix in Figure 3), to the data present on its vision window (red square in Figure 3), to get an output feature (green square in Figure 3). This filter slides over the input FM to compute all of the data on the output FM. Therefore, performing convolution is largely a series of multiply-accumulate (MAC) operations. The convolution kernel is followed by an activation function such as sigmoid, ReLU, and tanh to introduce some nonlinearity and limit the range of its output.
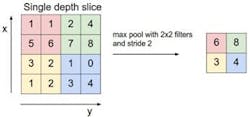
The pooling or subsampling layer’s role is to reduce the size of FMs; they’re applied to input FMs using the similar sliding technique found with convolution layers. One of the most common pooling operations is “max pooling” (Fig. 4). Average pooling or sum pooling could be used as well. Figure 4 shows an example of applying a 2x2 max pooling kernel on an input 4x4 FM, resulting in a 2x2 output FM.
CNNs have two stages: feature extraction represented by the convolution and pooling layers, and a classification stage performed by fully connected (FC) or dense layers. These FC layers, representing the last layers of a CNN, process the flattened output FM of the last feature extraction stage’s layer. As shown in Figure 2, the data of the last FM is flattened before transmitting it to the first FC layer, thus simplifying the connection between these layers. FC layers consist of neurons that are connected to all previous layer nodes.
Learning and Inference for ML and Edge AI
Learning and inference are two important aspects of machine learning and edge AI. While the learning phase involves building and optimizing the neural-network models, inference involves using them to make predictions on new data (Fig. 5). Performing learning on edge devices isn’t ideal due to their limited resources, so this is typically done on centralized servers or in the cloud.
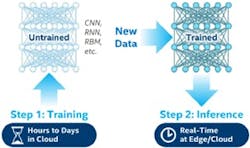
Edge devices are more suited to the inference phase, which matches their limited resources such as memory, processing power, and energy. Moreover, these edge devices (e.g., sensors and cameras) can produce large amounts of data, and sending it to centralized servers for processing may result in latency and network bandwidth constraints. Thus, performing inference on edge devices can reduce the burden on centralized servers, increase response times, and improve the system’s overall efficiency.
Neural networks employ two learning types: unsupervised and supervised. Unsupervised learning uses unlabeled data to detect patterns and structures in data, while supervised learning adapts the neural network's parameters via labeled data. Supervised learning is more commonly used because it results in better performance for most AI applications.
The most known supervised learning algorithm is backpropagation, which is based on calculating a gradient of the error between the desired and actual outputs and then back-propagating it to neurons of previous layers to adjust their synaptic weights. The learning phase results in a network model with fixed synaptic weights that’s then used in the inference phase, where only the forward pass of real data is performed to get the final prediction result.
Edge Deployment of AI Algorithms
The deployment of edge AI algorithms, particularly during the inference phase, has become increasingly common in various applications such as autonomous vehicles, smart cities, and Internet of Things (IoT) devices. Due to the huge amount of data generated at the edge, it becomes very difficult to move data from sensors to the cloud for processing and expect real-time response.
One solution is bringing AI to edge devices for processing data where it’s generated. First, doing so will reduce latency because the processing is performed locally without having to move all of the data to a centralized server. Second, this will improve privacy because sensitive data is processed locally, without sending it to a centralized server—i.e., to avoid network attacks. In addition, it brings more reliability because there’s no dependency on internet connectivity, which can be unreliable in certain environments.
Finally, it helps reduce cost in three ways: edge devices aren’t expensive; cloud servers’ resources may be reduced because they will receive much less data to process; and there’s no need to build up a complete infrastructure to move data around. Different hardware solutions can be used as edge devices to deploy AI algorithms. They can be separated into three categories: general purpose, specialized AI, and programmable systems.
General-Purpose Hardware Targeted at Edge AI
General-purpose processors, including CPUs and GPUs, are widely used for the purpose of edge AI due to their versatility and processing capabilities. Executing AI algorithms using CPU-based designs, unless with large computational infrastructures, results in extended run times. This makes them inadequate when dealing with time-restricted applications. As a result, GPUs have become a popular alternative to CPUs to accelerate the processing and reduce execution time.
Indeed, GPUs provide significant speedups for neural-network inference. They can handle a large number of parallel computations, making them suitable for AI applications that require fast and efficient processing of large amounts of data.
However, when it comes to edge AI, where the hardware resources and power consumption are very limited, it’s difficult to rely on GPU-based systems due to high-power consumption and prohibitive cost. Therefore, the use of general-purpose processing hardware to deploy edge AI algorithms isn’t a good solution for mass production.
Specialized hardware chips, ASICs, have been designed with a specific architecture to accelerate AI applications. Some of these systems are largely used in data centers to train deep-learning algorithms, such as Google Tensor Processing Units (TPUs). Other examples are more dedicated to edge AI, including Intel Movidius Myriad and Google Coral. These ASICs are ideal for AI applications that require real-time processing and low-latency response.
In addition, ASICs can be more cost-effective than using a combination of general-purpose processors and accelerators, especially for high-volume production. However, ASICs have limitations in terms of flexibility and scalability, as they’re designed for a specific function and can’t be reconfigured for different tasks. This is particularly the case with AI algorithms, which are continuously evolving. Moreover, designing ASICs requires significant time and investment, making them less suitable for small-scale or rapidly evolving AI applications.
Reconfigurable Hardware
FPGAs are highly flexible and can be reconfigured to implement custom logic tailored to specific AI algorithms. This makes them well-suited to edge AI applications, where power and resource constraints require efficient and optimized hardware implementations. By programming an FPGA to implement a specific algorithm, designers can achieve significant performance improvements and power-efficiency gains compared to running the same algorithm on a traditional CPU.
eFPGAs are similar to FPGAs, but they’re integrated directly into a SoC design. This makes them useful for edge AI applications where space and power constraints are even more severe. Moreover, they’re a better option in terms of cost for mass production—standalone FPGAs have rapidly become prohibitive in this regard. By integrating an eFPGA into a SoC, designers can implement custom logic directly in the device, reducing the need for external hardware and improving overall system efficiency.
For example, Menta's eFPGA is a programmable-logic IP that can be integrated into SoC devices—it’s integrated directly into the ASIC alongside other IPs and custom logic. This integration brings hardware programming functionality to the ASIC; the integrated eFPGA IP may be reprogrammed at any time during its lifetime. The company’s eFPGA IP can perform a variety of functions such as digital signal processing, image processing, and neural-network acceleration.
As shown in Figure 6, Menta’s eFPGA IP consists of embedded logic blocks (eLB), digital signal processing (DSP), embedded memory blocks (eMB) and embedded custom blocks (eCB). The amount and size of each element can be tuned for customer designs.

eFPGAs vs. Other Comparable Technologies
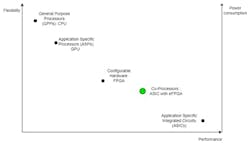
General-purpose processors offer a high degree of flexibility, but with very limited computing performance capabilities. Consequently, they represent a poor solution for edge AI since algorithms require high computing performance due to their parallel and distributed aspects.
Application-specific processors, such as GPUs, have higher performance, but with higher cost and greater energy consumption, which also makes them inadequate for edge AI applications. Indeed, GPUs are generally tasked with processing a huge amount of data in parallel and are used extensively for learning AI algorithms.
The third category concerns the configurable hardware, which provides an RTL-level hardware reprogramming feature unavailable with GPPs and GPUs. Indeed, despite RTL-level programming being more difficult than the high level used with CPUs/GPUs, users may design hardware circuits with the available logic that will be dedicated to the specific AI application. Doing so results in better performance than using general-purpose hardware.
Moreover, high-level synthesis HLS tools make it possible to generate RTL from a high-level language, like C++, which makes it easier to program these FPGAs. From these perspectives, FPGAs represent a better solution for edge AI than CPU/GPU-based systems.
Before discussing ASICs integrating eFPGAs, let's consider ASICs. ASICs are hardware circuits dedicated to a specific application and can’t be modified after manufacturing. As shown in Figure 7, they feature the best performance in terms of computing capacity and energy consumption than all of the other options. However, in the context of edge AI, where algorithms are evolving at a rapid pace, designing such systems is very risky. That’s because they will most likely have a limited lifecycle, since they will not support the eventual novelties of AI models.
Despite a slight increase in power consumption and a decrease in performance, ASICs that integrate eFPGAs represent the best tradeoff between performance, flexibility, and cost, and they’re a good alternative to pure ASICs. This solution enables performance and power efficiency that’s closer to ASICs, and at the same time offers a flexibility feature thanks to the eFPGA IP.
eFPGAs for AI Usage
Here, we present a preliminary work that’s still in progress. It aims to show the relevance of using Menta’s eFPGA IP for AI acceleration in comparison to standalone FPGAs and microcontrollers. In this perspective, a systolic-based convolution engine has been implemented to accelerate CNNs. To do so, RTL code of this engine was implemented and then mapped on two constructed eFPGA architectures.
One possible way of applying convolution to a given matrix A by a filter B and get an output matrix C is shown in Figure 8. It consists of applying filter B to different locations on matrix B starting from the first one located at “a11-a33” and sliding from left to right and top to down by a stride “s” of “1” in the shown example, until the last location “a22-a44.”
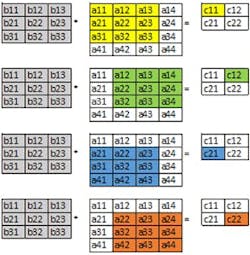
An alternative, more optimized way to calculate matrix “C” is to reshape the involved matrices. Figure 9 shows the steps to perform such optimized convolution. Matrix “AT” is constructed from the original matrix “A,” where each row contains the elements needed to compute a single element of the output matrix. Matrix “B” is also transformed to “BT” in the same philosophy. Then, the convolution is performed as a simple matrix multiplication between matrices “AT” and “BT.”
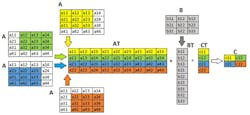
In the systolic-arrays-based convolution engine, this reshaping mechanism is used to feed the processing elements (PEs) forming the engine, with each element of "CT" being represented as a PE. The resulting output matrix "CT" is then transformed back to obtain the expected format of matrix “C.”
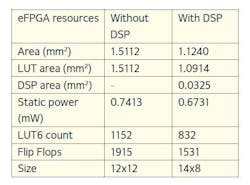
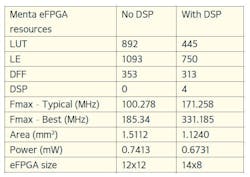
Based on the RTL implementation of this convolution engine, two eFPGA architectures with sufficient resources for mapping have been constructed. To assess the impact of using Menta adaptive DSP blocks for AI tasks, one eFPGA architecture was selected with these DSP blocks and another without (Table 1).
The next step involves synthesizing, placing, and routing the convolution engine on the selected eFPGA architectures using the RTL-to-bitstream tool called Origami Programmer. Figure 10 shows place-and-route graphical representations of mapping the convolution engine on the two selected Menta eFPGA architectures.

Table 2 shows the obtained power, performance, and area (PPA) results from these implementations. The eFPGA with DSP blocks and a size of 14x8 occupies a smaller area and achieves higher maximum frequency than the second eFPGA, which shows the benefit of using Menta adaptive DSPs for accelerating AI algorithms.
The advantages of using Menta DSPs will be more pronounced and significant when dealing with very large and deep neural networks that are commonly used in state-of-the-art AI applications. As mentioned in previous sections, these networks rely heavily on matrix multiplications and accumulations, which can be efficiently handled by the company’s DSP blocks.
Comparing eFPGA Implementation to Standalone FPGAs and MCUs
A comparative study was conducted in which the deployed convolution engine on the Menta eFPGA IP is implemented in two standalone FPGAs, one from AMD and the other from Intel, as well as in a software version on an STM32 microcontroller. Table 3 summarizes the comparison results of the operating frequency and execution time for applying a 3x3 convolution filter to a feature map of 4x4 size. From these results, we observe that the throughput achieved with Menta eFPGA IP and AMD FPGA are similar, and they’re approximately 100 ns faster than Intel's FPGA.

Compared to the microcontroller, which isn’t well-suited for the parallel computing required in ANNs, the eFPGA is approximately 2.45M times faster. Moreover, Menta’s eFPGA IP optimizes hardware resource usage by only allocating the necessary amount, while FPGAs and MCUs have predefined resource amounts.
These results motivated Menta to design its eFPGA-based AI accelerator with the possibility to be adapted to resources and performance constraints of the target application. This is done by varying the processing from parallel to multiplexed and efficiently using the company’s adaptive DSP modules.
Using a RISC-V CPU Coupled with an eFPGA
In partnership with Codasip, Menta proposes a common computing engine in which the latter’s eFPGA is integrated directly into the pipeline of a RISC-V CPU. This enables the addition of new custom instructions after the chip is taped out. In the context of edge AI, this technology provides a promising solution for accelerating neural networks. The instructions of the target application can be executed on two different targets, a standard ALU and an eFPGA.
Thus, simple or standard instructions can be run on the basic ALU, while complex, custom, or other instructions not supported by the ALU can run on Menta’s eFPGA IP. In the context of AI, it’s possible to use the eFPGA to accelerate the computationally intensive parts of AI algorithms such as matrix multiplication, activation functions, new features, etc.
Moreover, the adaptive DSPs are tailored for matrix multiplications which, as previously mentioned, are widely present in ANNs. In addition, users needn’t manage the execution of instructions—i.e., which part goes to the ALU and which part to the eFPGA—because this is handled by the Codasip compiler.
Research Project Case: EPI Face Recognition
Menta is involved in several national and international research projects in which its eFPGA IP is being used to speed up AI algorithms for both mapping AI accelerators and supporting them by performing pre- and post-processing of their coming and outgoing data.
In the European Processor Initiative (EPI) project, an application for face recognition based on the SqueezeNet neural network is implemented on Menta’s eFPGA present in one of EPI chip’s tiles (Fig. 11). A custom AI accelerator is mapped on the Menta eFPGA to run SqueezeNet.
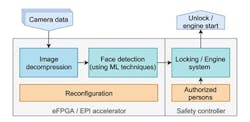
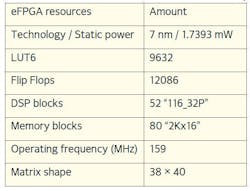
In addition to accelerating the ANN, the Menta eFPGA present on EPI’s chip allows for on-the-fly reconfiguration, e.g., replacing the AI accelerator with an application needed in a driving situation once the ride begins. The obtained simulation results show that the eFPGA, which fits in around 1% the total area of EPI chip, processes an image in approximately 150 ms using an optimized version of SqueezeNet that has about 962 million 8-bit MAC operations. The resources of the selected eFPGA IP are shown in Table 4. Recently, a hardware chip integrating Menta’s eFPGA was embedded in a demonstration autonomous car and used in various driving applications.
NimbleAI, a European project also involving Menta in collaboration with CEA and Codasip, used the eFPGA IP to implement a novel in-memory computing paradigm called CCDM (Coupled Computing Direct Memory). CCDM blocks will be automatically inferred by Menta’s Origami Programmer tool, using them to execute and deploy CNNs and pre- and post-processing present in the project's use cases. This system utilizes Codasip’s CPU to manage and control the execution of the application's instructions on the CCDM engine.
Large ANNs
The Menta eFPGA IP is well-suited for deploying edge AI algorithms that are known for tinyML on both edge devices and edge servers. Indeed, the eFPGA is a generic IP in which the number of logic cells can be configured between 100 to 200k. Thus, when the eFPGA is used to implement an AI accelerator, the occupied logic resources must be within 100 to 200k cells.
Nevertheless, when targeting very large neural networks exceeding that amount, the AI accelerator must be considered as a hard block and the eFPGA IP should be used for pre- and post-processing to better connect with neighboring IPs like memory, CPU, cameras, etc. A simplified schematic representation of such a system is shown in Figure 12.
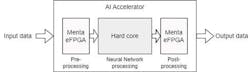
This pre- and post-processing usage of Menta eFPGA IP is already studied and applied in the EPI project (Fig. 13).
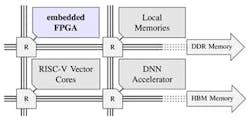
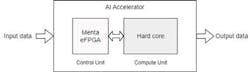
In this same context of large neural networks, we can imagine a second solution (Fig. 14): The AI accelerator is split into a computing hard core that deals with demanding computing operations (e.g., matrix multiplication), memory blocks for saving the parameters of the network, and a controller that ensures a coherent functioning. The eFPGA programmable logic can be then used to implement the controller and integrate the memory and computing blocks through eCBs. Doing so, we get a flexible AI accelerator that can be reprogrammed to handle different neural-network models and support the eventual AI novelties, too.
Benefits of Using eFPGA IP
There are three main benefits derived from using eFPGA IP for AI applications: flexibility, power efficiency, and computing performance. Flexibility is one of the main advantages of using the eFPGA for edge AI applications.
It can be reprogrammed as needed to update the deployed AI application for any change, such as modifying the ANN’s topology, modify its parameters after having better training, support new layers or features, etc. This feature is especially beneficial for edge AI applications, as the data and requirements at the edge can change frequently and the AI field is in a continuous evolution.
In terms of improved power efficiency, eFPGA IP can be optimized to perform specific tasks. This could result in lower power consumption compared to general-purpose processors, which is crucial for edge AI applications.
Finally, the eFPGA can offer high computing performance and low latency, accelerating specific functions in a system such as image recognition and machine-learning algorithms. This can lead to faster and more accurate processing of data at the edge, which ultimately improves the performance of edge AI applications.
Read more articles in the TechXchange: AI on the Edge.
About the Author
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: