FPGAs "Accel" at Automatic Speech Recognition
What you’ll learn:
- What is ASR?
- The challenges facing ASR.
- How FPGAs solve ASR challenges.
Automatic speech recognition (ASR) is the first part of conversational AI where a human interacts with a computer as if it were a real person by talking to it. Bill Jenkins and Electronic Design’s Bill Wong discuss Achronix’s ASR strategy (watch the video above).
ASR technology has come a long way since its inception in 1952 by Bell Labs. The company initially created a digit recognizer called “Audrey” and then a decade later improved it to recognize basic words like “hello,” transforming from a futuristic dream to a ubiquitous and practical tool in our daily lives.
Smartphones, virtual assistants, cars, and smart-home devices all incorporate some form of speech-recognition technology. ASR enables machines to understand and interpret human speech, revolutionizing how we interact with devices and bridging the gap between humans and computers. In this article, we explore the challenges with ASR in a variety of different applications and discuss how FPGAs help overcome them.
Basics of ASR
Researchers have developed algorithms to extract meaningful features from speech such as phonemes. These are the different sounds made with the voice when speaking—there are about 50 in the English language. For the past 15 years or so, machine-learning algorithms have powered ASR functionality with constant improvements in advanced deep-learning methodologies due to enhanced computing capability.
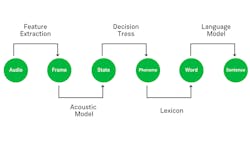
An ASR system has four main components:
- Feature extraction: Word fingerprints that help identify spoken words such as pitch, volume, and accent.
- Acoustic modeling: Turns extracted features into a statistical parametric speech model that’s compared against other models.
- Language model: Helps correct the acoustic model predictions to determine which word sequences are possible using grammar rules and probabilities for certain sounds occurring together.
- Classification or scoring: Rates the most probabilistic output of a word.
Common deep-learning algorithms used for the classification stage are transformer, recursive neural-network transducer (RNN-T), and connectionist temporal classification models (see figure). Transformer models don’t rely on convolutions or recurrence to generate the output, so they tend to be larger and more memory intensive. Because of this, they don’t perform well for real-time applications where a delayed response would be problematic.
Conversely, RNN-T models have all of the components of ASR in one model and doesn’t require a very large decoder graph, as is the case with transformer models, which allows them to be much smaller and more compact to run on edge devices for real-time streaming ASR applications.
On the downside (which doesn’t impact ASR applications), is that everything is done sequentially, meaning you can’t input an entire sentence at once like a transformer model. Thus, in a sentence, you lose the connection of one word to another, though that only matters for natural language processing performed after the transcription has occurred.
Challenges Facing ASR
As you can imagine, even a half of a second delay would be noticeable and annoying. Therefore, for applications like closed captioning of live television or NPR, transcription, virtual assistants, and translation require ultra-low latency.
Imagine you’re watching live television with closed captioning on and the text appearing on the screen was from several seconds ago. It's fine if you can clearly hear the scene, but if you have to read what’s happening, it becomes counterproductive. In the case of translation, if the response takes too long, you would constantly be talking over each other. In many cases, the source for this delay is the added latency of either doing translation with actual humans or automating it on the cloud with much higher latency compute devices such as FPGAs and GPUs.
Call centers have thousands of call agents handling thousands of calls per day. Those calls are transcribed for record keeping. In the case of virtual chatbots, we’ve all experienced the dreaded robot on the other end of the call misunderstanding what you’re saying, having a limited set of options to interpret from, and banging on the “0” key trying to get a live person.
Many applications use the cloud to perform ASR-as-a-service, which can be extremely expensive and limits the uses to applications that don’t require extreme privacy and security measures. This includes medical with HIPPA, financial with GLBA, and even police body-cam footage transcription with the Bill of Rights.
FPGAs Help Solve Those ASR Challenges
Field-programmable gate arrays (FPGAs) perform extremely well with transformer models at scale compared to a GPU. More importantly, though, they’re orders of magnitude more efficient running RNN-T type models for applications that require ultra-low latency at scale.
For example, a single Achronix Speedster7t FPGA running the RNN-T ASR appliance can support up to 4,000 real-time streams of audio in less than 60-ms latency end-to-end. In comparison, leading GPUs have 64 streams at 500 ms for just the inference latency and that doesn’t include the pre- and post-processing and data-movement times.
The FPGAs incorporate a full hardware 2D network-on-chip (2D NoC) that resolves the data ingress, egress, and FPGA bottlenecks. The 2D NoC can sustain 20 Tb/s of data movement from the IO interface, throughout the FPGA fabric, to external DDR4 memory and eight banks of external GDDR6 memory.
In addition, the FPGAs integrate thousands of machine-learning processors (MLPs) capable of 80 TOPS, each with 72 kb of block RAM and 2 kb of register-file memory tightly coupled to the FPGA fabric. This enables algorithms that require recursion or result reuse to do so with extreme performance and low latency, and they don’t need large batches of data to be processed.
Conclusion
For applications that demand numerous real-time streams of speech-to-text with ultra-low latency, the Achronix FPGA ASR solution, consisting of a single server, a Vector Path FPGA card, and ASR acceleration software package, help solve issues either on-premises in your own data center or in the cloud. And it costs less because you can process much faster and with far less resources.
About the Author
Bill Jenkins
Director of Product Marketing
Bill Jenkins is an engineer turned product marketer, who is now the Director of Product Marketing at Achronix. He joined the company after 11 years of working at Altera/Intel PSG in various technical and marketing roles. He led the initial concept and rollout of PSG’s high-level synthesis (HLS) strategy with Open CL, developed Intel’s AI solution strategy to showcase the value of FPGAs across a wide variety of market segments, and developed AI, HPC, radar, and security solutions within the military, aerospace, and government (MAG) business unit. Bill got his BS and master's in electrical engineering, and MBA from the University of Massachusetts Lowell.