Power-Efficient Processor Leverages Novel Dataflow Architecture
What you’ll learn
- Why this new architecture was the best thing at CES 2026.
- What is a dataflow architecture?
- Why Efficient Computer’s Electron E1 processor design is so radical.
- How the Electron E1 is able to be so power-efficient.
This is an update from the 2026 Consumer Electronics Show, where I saw Efficient Computer's processor in action. As with many new announcements, we cover them often before silicon is shipping, so the remainder of this article has been up for a couple months.
I cannot stress enough the significance of this chip. It's even more important than NVIDIA's announcement of its latest CPU/GPU, Vera Rubin. While this AI cloud server platform is a major step forward, it's an incremental improvement on our standard processor and GPU architectures.
Efficient Computer's dataflow system is a radical change that works with existing software written in programming languages like C and C++. However, it can do much more, which I will be writing about in the future. The ability to implement parallelism in reorganizable hardware is something that only FPGAs have been able to do, and they're nowhere near as efficient or easy to employ.
The first chip from Efficient Computer is tiny and targets applications that small microcontrollers address, but with a power efficiency that's orders of magnitude better and performance that higher-end solutions only dream of.
So, if you want to see what I thought was the most significant announcement at CES 2026, then read on.
--Bill Wong
My master’s degree work many decades ago was on dataflow architectures. At the time, though, the implementation using conventional programming languages was beyond the hardware capabilities. How times have changed — and not solely for artificial intelligence (AI).
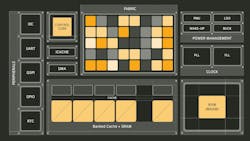
In the video (above), I talk with Efficient Computer’s CEO Brandon Lucia about the company’s Electron E1 (Fig. 1). It uses a custom fabric architecture to implement a programmable dataflow architecture designed to run applications written in conventional programming languages like C, with the effcc Compiler hiding the underlying architecture.
The approach significantly reduces the power requirements by two orders of magnitude even when compared with ultra-low-power microcontrollers like the Texas Instruments MSP430 and Ambiq Micro’s Apollo, which use a conventional, register-based Von Neumann approach. Such power efficiency is important when discussing embedded compute/Internet of Things (IoT) applications, where reducing the amount of power can increase the longevity of a system or allow for more processing power to address new application features.
What is a Dataflow Architecture?
Dataflow architectures aren’t new, but they’re typically implemented in a static fashion to compute a value based on inputs (Fig. 2). Data “flows” through computational units.
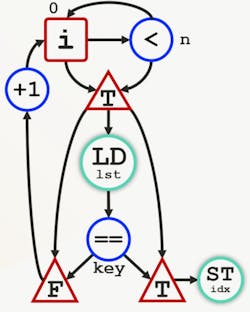
The code for this example is:
for i = 0..n:
if lst[i] == key:
*idx = iA dataflow system is usually synchronous or asynchronous. In the latter case, computations occur as data is supplied, generating results once all of the necessary inputs are valid. Synchronous operation latches the data as it flows through computational units. Things get a bit more complex as control is added to the mix. Any dataflow application that’s more than just numeric manipulation needs control flow.
Dataflow implementations are often found in ASICs and FPGA systems in a more static form, where an algorithm is fixed and applied to a data stream or a fixed set of inputs. This is generally much more efficient in terms of power and performance because operations can be done in parallel and data movement is point-to-point.
A conventional CPU, on the other hand, must move data to and from a register file. On top of that, multiple instructions are needed to specify movement and calculations in a sequential fashion. ASICs and FPGAs can often run with a much lower clock speed while delivering higher throughput than a processor running a sequential program.
Why Efficient Computer’s Electron E1 Processor Design is So Radical
What makes Efficient Computer’s Electron E1 stand out is the programmable nature of the system’s dataflow. The chip has a RISC-V processor (RV32iac+zmmul), but it’s there to manage the computational fabric that makes up the bulk of the system. The RISC-V process powers down when it’s not needed.
The radical aspect comes into play with Efficient Computer’s compiler. It takes conventional code like a C program and allows it to be mapped onto the computational fabric that contains processing elements (PE) and a network-on-chip (NoC). The NoC feeds the PE input and routes the PE outputs as needed. Essentially, the PE outputs are connected to the inputs of the next PE in a calculation.
One might say that sounds like an FPGA. The major differences include the types of functions provided by the underlying fabric. An FPGA works at a logic gate level while the Electron E1 is at a program data unit that includes things like integers and floating-point numbers.
An FPGA can block things out and some include higher-level blocks that provide DSP-level functionality, but these tend to be the exception with the bulk of an FPGA comprising very basic lookup tables (LUTs). The FPGAs don’t use a NoC, although some advanced FPGAs have a NoC to connect its fabric with other components.
So, now we have an application mapped to a PE/NoC fabric. To make things more effective, there are different types of PEs, rather than having complex PEs that could handle different functions and data types as well as load/store (LS) with memory and control flow. In fact, specialization is also part of the NoC, which consists of three different NoCs for configuration, control, and data.
It would be great if an entire application would fit into the fabric, but two issues crop up. One is that an application rarely runs all aspects of the code, even in an application with easily exposed parallelism. The other is fitting large applications onto the fabric.
The answer is to apply an idea from GPUs and implement computation kernels or nuggets of code that will run for a period of time and then be replaced by other kernels. This is especially effective with parallel-processing applications like graphics or AI, but it can work well in other situations like handling interrupts. It all depends on the overhead needed to set up the system and how long it operates.
Efficient Computer’s compiler essentially handles the details of converting the source code into something that implements the application using the dataflow and control flow in the fabric. It also manages how pieces are loaded into the fabric. This is actually a lot harder to do and some interesting issues emerge when it comes to debugging, but we’ll have to leave that discussion for another time.
Listed below are some technical papers that provide more details about the approach taken by Efficient Computer with its Electron E1. The architecture and chips in the papers are precursors to the platform.
MANIC: An Energy-Efficient Architecture for Ultra-Low-Power Embedded Systems
RipTide: A programmable, energy-minimal dataflow compiler and architecture
Monza: An Energy-Minimal, General-Purpose Dataflow System-on-Chip for the Internet of Things
How the Electron E1 is Able to be So Power-Efficient
Part of the trick when designing the dataflow system was to determine where conventional processors spend a lot of time and energy. This turns out to be moving data to and from the register file and handling the instruction flow because the entire register file must be active to access an entry. This is a similar issue with instruction pipelines. A spatial dataflow processor is designed so that these operations aren’t required.
As might be expected, the chip has low-power and deep-sleep modes. It also can run the fabric at 40 or 200 MHz providing 5.4 and 21.6 GOPS, respectively. The Electron E1 has 4 MB of MRAM with DMA support, 3 MB of ultra-low-power SRAM, and a 128-kB ultra-low-power cache.
The effcc Compiler handles C, but other languages like C++, Python, and Rust are on the to do list, as is support for AI in the form of LiteRT and ONNX support.
The peripheral complement, which is similar to regular microcontrollers, includes six QSPI, six UART, and six I2C ports plus 72 GPIO pins. A real-time clock (RTC) is on-board as well, along with clock-generation and power-conversion support via an integrated LDO and buck converter. The power supply is 1.8 V.
Looking under the hood, the Electron E1 is radically different than any other processor on the market. Like a good compiler, effcc hides the underlying architecture from programmers, allowing everyone to benefit from the hardware’s power efficiency.
It will be interesting to see how well the chip will be adopted and its potential growth in the future. You can see how the chip operates using the simulator at the Electron E1 Playground website. This includes presentation of the Fabric as well as a debugger that also shows connections (Fig. 3).
Check out More CES 2026 articles


About the Author

William G. Wong
Senior Content Director - Electronic Design and Microwaves & RF
I am Editor of Electronic Design focusing on embedded, software, and systems. As Senior Content Director, I also manage Microwaves & RF and I work with a great team of editors to provide engineers, programmers, developers and technical managers with interesting and useful articles and videos on a regular basis. Check out our free newsletters to see the latest content.
You can send press releases for new products for possible coverage on the website. I am also interested in receiving contributed articles for publishing on our website. Use our template and send to me along with a signed release form.
Check out my blog, AltEmbedded on Electronic Design, as well as his latest articles on this site that are listed below.
You can visit my social media via these links:
- AltEmbedded on Electronic Design
- Bill Wong on Facebook
- @AltEmbedded on Twitter
- Bill Wong on LinkedIn
I earned a Bachelor of Electrical Engineering at the Georgia Institute of Technology and a Masters in Computer Science from Rutgers University. I still do a bit of programming using everything from C and C++ to Rust and Ada/SPARK. I do a bit of PHP programming for Drupal websites. I have posted a few Drupal modules.
I still get a hand on software and electronic hardware. Some of this can be found on our Kit Close-Up video series. You can also see me on many of our TechXchange Talk videos. I am interested in a range of projects from robotics to artificial intelligence.