The Essentials of AI Edge Computing
This video is part of TechXchange: AI on the Edge. You can also check out more TechXchange Talks videos.
NXP Semiconductors provides a range of hardware and software tools and solutions that address edge computing, including support for machine learning (ML) and artificial intelligence (AI). The company's new eBook, Essentials of Edge Computing (PDF eBook), caught my eye because of chapter 4, which discusses the AI/ML support.
I was able to talk with Robert Oshana, Vice President of Software Engineering R&D for the Edge Processing business line at NXP, about the eBook and AI/ML development for edge applications. Robert has published numerous books and articles on software engineering and embedded systems. He's also an adjunct professor at Southern Methodist University and is a Senior Member of IEEE.
You can also read the transcript (below) for the video (above).
Links
Interview Transcript
Wong: Machine learning and artificial intelligence are showing up just about everywhere, including on the edge where things can get a little challenging. Rob, could you tell us a little bit about machine learning on the edge and why it's actually practical to do now?
Oshana: So first of all, in general, processing provides a certain number of benefits over direct cloud connectivity. One is latency. For example, by processing on the edge, you don't have to send information back and forth to the cloud. So latency is a big concern and when you apply that concept to machine learning, it makes even more sense.
Machine learning inherently involves a lot of data. You would want to do as much of that inferencing either on the end node or on the edge, as opposed to trying to send information back and forth to the cloud. So latency is clearly a benefit.
Also just connectivity, there's many applications for machine learning that are done in the areas where you actually don't have connectivity to the cloud. A couple that I've been involved in recently. One is medical, where certain types of medical of sort of physical areas of the world don't have reliable connectivity to the cloud, but you still want to do some machine learning on the edge there in order to make real-time intelligent decisions,
And another area where I have some experience in is oil and gas, where same concept here in the middle of nowhere, doing some logging and looking at a bunch of data coming back and forth, and you want that intelligent kind of ML (machine learning) done in real time.
And if you don't have that connectivity, you know, obviously you're going to be limited. So that's one reason why it's gaining a lot of popularity. When you need that latency real time, and then also you know, when you do machine learning, let's say in the cloud, there's your it's big iron stuff and you're leveraging high-end compute, high-performance computing, multiple GPUs in the whole kind of, you know, just go green, if you will.
Being able to do that more efficiently on the edge, where you've got limited memory but also limited power processing and power, you can do it more efficiently.
It's a great initiative but again, you don't have to leverage all that heavy horsepower in the cloud. These are a couple of reasons why I think it's gaining in popularity if you do this on the edge.
Wong: Okay. Well, could you talk us a little through the development flow for this?
Oshana: Pretty much the same for the edge as it is on the cloud.
You know it well, in many cases it is this diagram (Fig. 1) I've got here at this high level. The development flow shows the main components of ML (machine learning) development and, you can see, first of all, just by looking at this very quickly, you can see it's pretty complicated.
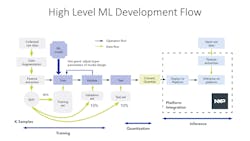
There's a lot of stuff going on with the data which is shown in the green there, lots of data flow related to the data and also lots of operations with the black arrows, and, overall, it's a pretty complicated picture.
You can start doing this in the cloud or you can do actually much of this on the edge. So our edge-based toolkit eIQ allows developers to actually bring their own model and begin doing a lot of the steps on an edge, like on a PC, and deploy directly to the edge without having to get the cloud involved.
However, we know that many developers, scientists want to start in the cloud. In fact, this next diagram that I'm showing here, this is the workflow and the edge ML (machine learning) tools.
What it shows on the left is that between an embedded developer or even a data scientist or some ML expert, they may want to start in the cloud where they're comfortable. Maybe they have a very large model they need to build or they're just familiar and comfortable with starting in the cloud.
We give them that ability to do that. You can also do very similar things on the edge if you wanted to. We provide both options in the sense that if someone wants to start and build their model in the cloud, using some of the sophisticated tools in the cloud will provide an easy way of deploying that model to the edge. And that's what's shown on the left, through the cloud, down to the edge or even to an end. So we make it easy.
One of the things about these ML flows, as you can see, they're pretty complicated. We're trying to provide an ease of use, kind of an out-of-box experience that makes it a lot easier so you don't have to go through all kinds of detailed steps or you know, everybody doesn't have to be an email expert. When you deploy down to the bottom there where you actually have an actual application and inferencing running on an edge processor, an edge device, or an end node.
This is where we optimize the machine learning, the inferencing, to fit in smaller footprints like memory, to run at low power and also under as few cycles as possible using some of the sophisticated frameworks that are out there today.
Wong: Could you talk about some of the major AI frameworks that you support and why would you use one versus the other.
Oshana: Let me let me first start by just showing this slide here (Fig. 2) that shows some of these frameworks. Some of them are pretty, pretty popular like TensorFlow and even TensorFlow Lite, developed by what our approach, by the way, is to leverage some of the best-in-class technology that's out there in the community and in the open community.
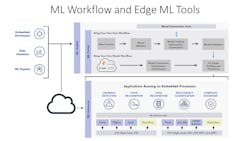
So we work very closely with Google, with Facebook for GLOW, which is an ML compiler, but to your point, some of these frameworks, like TensorFlow and then TensorFlow Lite, provide a lot of very good high-performance libraries and also kind of an ease of use of the abstract out of some of the complexity for the developer so they don't have to know the details of some of the algorithms for the needs of that kind of abstraction.
PyTorch, another framework that we support, also provides a level of ease of use with some very sophisticated algorithms for developing certain types of models. When you get down to the inferencing, even something like TinyML, which is optimized to run in very small footprints of memory and processing cycles, is becoming very, very popular.
So one of the things that we look for, and the reason we support several of them, is depending on the type of applications or building the type of sophistication you want and the algorithms, the type of deployment scenario you want from a footprint perspective and ease of use.
We support several of these different frameworks. Again, our approach is to leverage the best-in-class in the open community and then what we do is we optimize them to run very efficiently on the different types of ML processing elements.
Wong: Okay. Well, since you had the slide up, can we talk a little bit about the range of AI hardware and what level of sophistication would you find in each level?
Oshana: Yeah, so good question. So as you can see in this diagram, actually, our approach is to support ML on multiple different types of processing elements.
So in other words, starting on the left, if you want to do ML on a normal kind of Arm CPU, we provide the software stack to do that. And there's some benefit, not as efficient, but still someone may decide to run part of their ML algorithms on a CPU.
But look at the other ones.
The DSP (is) obviously inherently signal processing-oriented. Some of the the root kernels of even malware are in the form signal processing. So we provide some support for DSP. You know that some of the early IML started with GPU processing and a GPU has some parallelism and other structures optimized to do certain forms of machine learning on a GPU.
So we support that on the neural processing units, or I kind of generically call that an ASIC, something that's very optimized to neural-network processing, a multilayer perceptron with an MPU, you can get very specific. As far as the types of algorithms supported, the memory usage, the parallelism.
And so we support some of our internal neural-network processing units in order to accelerate a performance on machine learning.
And then even just for completeness, you could also run this on even a video-processing unit, which also has some optimized structures for machine learning.
And I would be remiss if I didn't mention just now that we're talking about hardware, even some some newer technologies like analog ML where you're kind of eliminating the Neumann bottleneck by doing kind of memory and computation on the same device.
These are showing a lot of promise as well. And so there is quite a range build as far as the hardware that would support it using technologies like GLOW compiler for machine learning we could distribute some of the processing between different elements of processing elements if you wanted to in parallel.
So we're looking at that very closely, as well based on customer kind of use cases, so it's kind of a quick range of hardware support.
Wong: Okay. Were talking about optimization Could you give us some details on how the optimization occurs and also what kind of optimization results can you get?
Oshana: So the optimizations are done mainly to exploit parallelism where it's possible to computational as well. If you look at something like a multilayer perceptron, there is potentially hundreds of thousands of different computations on the biases and on each of the nodes so we provide parallelism in order to do those computations, but we also are doing some memory optimizations with our neural-network processor.
There is more we can do to how we map and allocate memory, and we use memory throughout the different stages of the ML that we can also optimize for memory.
And then on the power side, most ASIC types or CPU or any custom kind of a block provides the opportunity to use different forms of power gating in order to lower overall power consumption (Fig. 3).
We're benchmarking all three of these performance memory and power to try to get to a kind of a sweet spot of where we think our customers want to be in terms of the different applications they're working on.

On the previous page, just to get back to this edge ML picture at the bottom (see Fig. 2), you see that the areas that we're focusing on include anomaly detection, voice recognition, face recognition, and kind of more of anomaly detection, a multi-object classification.
What we're doing there is we've optimized a lot of our hardware and software for these types of generic type applications, and then we're providing frameworks, software frameworks. We call these software packs to allow a developer to get started very quickly with the software structures, the ingress and egress, and the processing for each of these kinds of key areas in order to get started very quickly.
And we've optimized that software to work as closely as possible with the underlying hardware. And that gives us another opportunity to optimize at the software level as well.
Wong: Well, excellent. Thank you very much for providing your insights on machine learning on the edge
Oshana: Thank you, Bill.
About the Author

William G. Wong
Senior Content Director - Electronic Design and Microwaves & RF
I am Editor of Electronic Design focusing on embedded, software, and systems. As Senior Content Director, I also manage Microwaves & RF and I work with a great team of editors to provide engineers, programmers, developers and technical managers with interesting and useful articles and videos on a regular basis. Check out our free newsletters to see the latest content.
You can send press releases for new products for possible coverage on the website. I am also interested in receiving contributed articles for publishing on our website. Use our template and send to me along with a signed release form.
Check out my blog, AltEmbedded on Electronic Design, as well as his latest articles on this site that are listed below.
You can visit my social media via these links:
- AltEmbedded on Electronic Design
- Bill Wong on Facebook
- @AltEmbedded on Twitter
- Bill Wong on LinkedIn
I earned a Bachelor of Electrical Engineering at the Georgia Institute of Technology and a Masters in Computer Science from Rutgers University. I still do a bit of programming using everything from C and C++ to Rust and Ada/SPARK. I do a bit of PHP programming for Drupal websites. I have posted a few Drupal modules.
I still get a hand on software and electronic hardware. Some of this can be found on our Kit Close-Up video series. You can also see me on many of our TechXchange Talk videos. I am interested in a range of projects from robotics to artificial intelligence.