Disaggregating Power in Data Centers

What you'll learn:
- The demand for increased compute density.
- An evolution to ±400-V DC distribution to next-generation AI/ML supercomputer racks to meet that demand.
- Challenges and solutions in making the move to ±400-V DC distributed power.
Despite the leaps and bounds in the performance of the underlying silicon, artificial-intelligence (AI) training is pushing the power envelope in data centers. The latest Stanford AI Index Report shows that the most advanced AI models are becoming bigger, reaching up to 1 trillion parameters and 15 trillion tokens.
As a result, model training is taking more time and resources (up to 100 days and 38 billion petaFLOPS, or PFLOPS), while training costs continue to rise (up to $192 million). What about the power required to train one of these models? More than 25 million watts.
This article is part of this special report:

Tech giants like Amazon, Google, Meta, and Microsoft are turning to nuclear energy to keep up with the colossal amounts of power used to train and run AI. But feeding large amounts of reliable power into their sprawling data centers is only half the battle. The real issue arises inside the server racks themselves, where the power electronics are competing over limited space with processors, memory, and networking hardware. As power densities rise, managing this internal distribution efficiently is becoming a critical issue.
Electronic Design’s James Morra discussed the tug-of-war between power and computing with Maury Wood, Vice President of Strategic Marketing at Vicor, who said solving the issue could be as simple as pulling them apart.
How is the underlying architecture of the data center changing to tackle the AI power dilemma?
First and foremost, system designers are making significant efforts to increase compute density, which can be measured in petaFLOPS per liter in EIA-standard 19-in.-wide, or OCP-standard 21-in.-wide, data-center server racks. A single petaFLOP comes out to a quadrillion floating-point operations a second.
A related question is, “Why does higher compute density help to reduce the operating expense of training these large AI models?” In short, it’s because inter-processor memory bandwidth and non-optimal latency is a bottleneck on performance. Large model training requires massive amounts of low-latency memory and non-blocking “all-to-all” network fabrics supporting shared access by the dozens of processors within an AI cluster or “superpod.”
Bringing processors, memory, and network switches in closer physical proximity in a rack increases bandwidth and reduces overall inter-processor communications latency, reducing AI model training time. Specifically, the shorter distances defined by a single rack enable the use of passive copper cables instead of active optical transceivers, which are more expensive and power-hungry thanks to the embedded retimers and DSPs.
A typical 800G QSFP-DD and OSFP transceiver consumes about 15 W. Because these supercomputers use tens of thousands of optical transceivers, the power and cost savings of removing all these components are significant—up to 20 kW per rack.
What additional steps are being taken to balance compute density with power and cost savings?
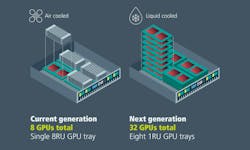
The next generation of AI supercomputers has evolved from fan-forced air cooling to liquid cooling. To pose myself another question, “How does this help to increase compute density?” In the previous generation, each eight-processor tray had ten 80-mm fans and a large heatsink that together required eight rack units (RUs) or a compute density of one GPU per rack unit.
The next generation uses direct liquid cooling with low-profile water block cold plates, with two CPUs and four GPUs per one RU tray. This equates to a processor density of four GPUs per rack unit, a 4X increase.
Liquid cooling also eliminates noise and eases the substantial power drawn by the high-RPM 12-V DC fans in these systems. Additionally, by maintaining lower package case and silicon junction temperatures, direct liquid cooling can improve AI processor mean time between failures. It has been reported to be relatively short in air-cooled AI training systems, increasing down time and operating costs. Higher clock rates are typically also possible in liquid-cooled computer systems compared to air-cooled ones. Both of these outcomes reduce AI model training time and cost.
What else can be done to increase compute density in data centers? What role is power playing?
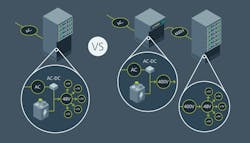
In previous and contemporary generations of AI server racks, which use three-phase 480-V AC (or sometimes 416-V AC) distribution to the racks, up to 30% of the rack space is consumed with AC-DC rectification, DC-DC conversion to 54 V DC, plus battery backup units (BBUs), capacitor shelves, and/or uninterruptible power supplies (UPS).
To increase compute density and to deal effectively with the prospect of racks that consume up to 140 kW or more, hyperscalers are now advocating an evolution to ±400-V DC distribution to next-generation AI supercomputer racks.
The vision is that the rectification, BBU, and UPS functions are moved out of the 48 RU racks, freeing up space for additional compute and networking trays. This achieves a compute density of 36 CPUs and 72 GPUs, for a total of about 720 petaFLOPS per 48 RUs, assuming rack dimensions of 600 mm width, 1,068 mm depth and 2,236 mm height. This new system architecture drives up the compute density to about 0.5 petaFLOPS of training performance per liter.
More than anything, the demand for higher AI training performance at lower cost will drive compute density and subsequently drive the adoption of ±400-V DC power distribution.
How does ±400-V DC distribution to AI server racks reduce system power and cost?
Existing 480-V AC distribution in data centers typically centralizes the BBU and UPS functions, with large BBU/UPS units supporting multiple AI/ML racks through power distribution units (PDUs).
Because these standalone 2-in-1 units receive AC, they must convert to DC to maintain the battery charge. The BBU/UPS units must also convert the battery output back to AC, and this double conversion process (AC-DC then DC-AC) results in power utilization inefficiency and additional hardware cost. With ±400-V DC distribution, no AC-DC rectification function is required at the BBU or UPS.
What are some challenges related to ±400-V DC distribution in AI data centers?
The 400-V DC voltage is not safety extra-low-voltage (SELV) level and, thus, presents safety and regulatory issues that must be managed. Also, to preserve the option for 800-V DC powered operation, three conductors (−400 V, GND, +400 V) must be run to each rack, which adds cost.

Assuming 140 kW per AI rack, this is 350 A at 400 V DC and 175 A at 800 V DC. Currents as high as 350 A likely require 500 MCM gauge copper cable (380 A ampacity at 75°C), while current of 175 A likely requires 3/0 AWG copper cable (200 A ampacity at 75°C). A 500 MCM gauge copper cable for 400-V DC distribution costs about $14 per foot, and 3/0 AWG copper cable for 800-V DC distribution costs about $5 per foot. In large data centers, this almost 3X difference in cable cost is significant.
The cost delta favors 800-V DC distribution, but the 800-V ecosystem is less mature than the 400-V ecosystem, due to use of 400-V DC in EVs. However, automakers are rapidly transitioning to 800-V batteries and DC-DC converters, so the cost issue is dynamic.
One of the biggest challenge areas is handling the high current levels within the rack. Assuming that 400 V DC nominal is converted to 50 V DC nominal using a 1:8 fixed-ratio DC-DC converter, at 140 kW, the conversion yields 2,800 A at 50 V DC. This requires a single silver-plated copper busbar with a cross-sectional area of roughly 1,600 mm2 to achieve the required ampacity for air-cooled busbars. A 2.1-meter-long busbar of this cross-sectional area might have a resistance of 5 μΩ, and might dissipate up to 45 W at 2,800 A at 20°C, assuming continuous 140-kW rack power.
What are the potential solutions, and how are power electronics playing into the shift?
However, it is possible to liquid-cool the vertical busbar using the existing in-rack liquid-cooling infrastructure and substantially reduce its air-cooled cross-sectional area, up to a factor of 5X (resistance and power dissipation increase with temperature). This represents a significant cost and weight savings.
Liquid cooling of the busbars can also provide tighter control over the maximum voltage drop across the busbar. This reduces the input voltage range of the intermediate bus converters and point-of-load voltage regulation burden on the CPU/GPU accelerator compute modules and network ASIC switch modules. Note that the selection of the 50-V DC connectors also becomes more critical when dealing with thousands of amps of current-carrying capacity to ensure minimal thermal losses.
The OCP Open Rack V3 specification, and the ORv3 HPR (High Power Rack) specification, are industry efforts to address the engineering challenges presented by current and next-generation AI supercomputer power and thermal engineering. Designing next-generation AI supercomputer systems will continue to involve navigating a complex set of engineering and economic tradeoffs.
High-density power modules with low thermal resistance and coplanar surfaces for straightforward mating to liquid-cooling cold plates will play a key role in enabling high-voltage DC distribution to AI supercomputer data-center racks.
Read more articles in this special report

About the Author

James Morra
Senior Editor
James Morra is the senior editor for Electronic Design, covering the semiconductor industry and new technology trends, with a focus on power electronics and power management. He also reports on the business behind electrical engineering, including the electronics supply chain. He joined Electronic Design in 2015 and is based in Chicago, Illinois.
Maury Wood
Vice President of Strategic Marketing, Vicor Corporation
Maury Wood is the Vice President of Strategic Marketing at Vicor Corporation. Prior to joining Vicor, Maury held senior roles at Broadcom, NXP, Analog Devices, and Cypress. He earned a BSEE from the University of Michigan and completed various graduate study programs at Northeastern University, Babson College, and MIT. Maury enjoys climbing, backcountry skiing, mountain biking and playing jazz bass.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: