“Reinforcement Learning” Fuels the Rise of Adaptive Controllers
What you'll learn:
- Why engineers look to incorporate adaptive and self-tuning approaches into system design.
- What is reinforcement learning and how does it work?
- Some approaches for successfully integrating RL into design and operation.

Industrial process control has traditionally relied on fixed-parameter controllers such as proportional integral derivative (PID) and model-based approaches like model predictive control (MPC). While these methods are well understood and robust, they often struggle to maintain optimal performance in nonlinear, time-varying, or poorly modeled systems.
One promising technique for adaptive and self-tuning control is reinforcement learning (RL), which enables controllers to learn optimal policies directly from interaction with the process. RL can be integrated into industrial control systems through hybrid architectures, highlighting safety and real-time considerations, and by applying appropriate hardware implementation.
Modern industrial processes operate under increasing uncertainty due to raw material variability, equipment aging, and changing operating conditions. Classical control strategies are typically tuned for nominal conditions, requiring periodic returning as system dynamics drift. While adaptive-control techniques exist, they often depend on explicit process models and predefined adaptation laws.
Reinforcement learning offers a data-driven alternative. By learning control policies that maximize a reward function, RL enables continuous adaptation without explicit system identification. The figure contrasts the conceptual difference between traditional feedback control and RL-based control architectures.
Fundamentals of Reinforcement Learning for Control
In reinforcement learning, an agent interacts with an environment by observing system states, applying actions, and receiving rewards. Over time, the agent learns a policy that maps observed states to optimal actions. In a process control context:
- States include sensor measurements or estimated variables.
- Actions correspond to actuator commands.
- Rewards encode control objectives such as tracking accuracy, energy efficiency, or constraint adherence.
Unlike classical controllers, RL systems continuously update their control policy based on performance feedback. The reward signal forms an additional feedback path that drives learning rather than direct control.
>>Download the PDF of this article

How Does Reinforcement Learning Deliver Self-Tuning Control?
One of the most practical industrial applications of RL is self-tuning control. Instead of directly manipulating actuators, the RL agent adjusts parameters of an existing controller.
A common example is RL-based PID tuning. The PID controller remains in the primary control loop, while the RL agent operates at a supervisory level. The agent evaluates transient and steady-state performance and incrementally updates controller gains.
This architecture minimizes risk, preserves existing safety certifications, and allows for deployment in legacy systems without major structural changes.
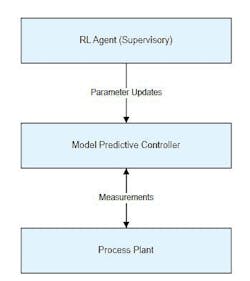
Pure RL control, where the learning agent directly drives actuators, is rarely acceptable in safety-critical industrial environments. Consequently, most real-world implementations use hybrid architectures as illustrated in the figure, where RL and MPC are teamed.
Incorporating Safety into Industrial Reinforcement Learning
Safety is a central concern when deploying learning-based controllers. Exploration, a core aspect of RL, can lead to unsafe actions if not properly constrained.
Safety shielding mechanisms can be used to intercept and validate RL-generated control actions before they reach the plant. Unsafe actions are modified or rejected, and the reward function penalizes such proposals. This approach enables learning to proceed without violating hard safety constraints.
Real-Time and Computational Constraints
Control systems often operate with cycle times measured in milliseconds, requiring deterministic execution. Reinforcement learning introduces additional computational load, particularly when using neural networks.
Meeting real-time requirements frequently involves decoupling inference and learning tasks. A hardware architecture can be implemented in which a real-time processor executes the control loop, while an application processor or accelerator handles RL inference and learning at slower rates.
Hardware–Software Co-Design Considerations
For electronic engineers, RL-based control introduces new design challenges. Task partitioning, memory management, and communication latency must all be carefully managed. Satisfying power and performance constraints often requires fixed-point arithmetic, reduced-precision neural networks, and hardware accelerators.
Distributed architectures are also emerging, with RL agents deployed at the edge and higher-level coordination handled via industrial Ethernet or IIoT frameworks.
Deployment and Workflow Limitations
Despite its potential, reinforcement learning isn’t a drop-in replacement for classical control. Stability guarantees are difficult to establish, and learned policies can be difficult to interpret.
Most industrial deployments follow a staged workflow: offline training in a digital twin, extensive validation, limited online learning, and continuous monitoring after deployment. This disciplined approach is essential to manage risk.
In summary, reinforcement learning provides a powerful framework for adaptive and self-tuning control in complex industrial processes. When integrated through hybrid architectures and supported by appropriate hardware/software co-design, RL can enhance performance while preserving safety and reliability.
For electronic engineers, understanding how learning-based controllers interact with real-time constraints and embedded hardware will be critical as intelligent control systems become more widespread.
References
Reinforcement learning algorithms: A brief survey
Discovering state-of-the-art reinforcement learning algorithms
>>Download the PDF of this article
About the Author

Alan Earls
Contributing Editor
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: