Stabilize Software Upgrades in Critical Systems

Well-known and generally accepted rules of thumb permeate software development. These include: the productivity ratio between different programmers can be as much as 10:1; the cost of fixing a bug caught in the field is 1000 times greater than fixing the same bug during the requirements analysis phase; requirements are the source of 56% of all defects in a system; and, most pertinent to this article, software is at its least dependable immediately after a new release.
This file type includes high resolution graphics and schematics when applicable.
The increase in failure probability after a new release arises in part from the software changes themselves—new bugs will have been introduced—and from the installation process. Developers of the new software version must anticipate the environment into which the new version will be introduced (company X is upgrading from version 2.3 and uses feature A heavily, whereas company Y is upgrading from version 2.1 and uses only feature B). Anticipating all of those environments is difficult and the installation itself often requires fallible manual intervention.
A quick glance back through news reports reveals telecommunications networks crashing, banks being unable to handle customer transactions, games consoles locking up, and airlines being unable to put passengers on aircraft—all attributed to failures following a software upgrade.
The (Lack of) Evidence
Unfortunately, as Laurent Bossavit points out, well-known ”facts” about the productivity of programmers, the cost of bug fixes, and the contribution of requirements to system defects may be true, but no evidence exists to support them.1 The observations in Bossavit’s book also throw doubt on our acceptance of the increased failure rate immediately following a release—and, as critical systems increasingly depend on software to provide functional safety, it’s important to understand the nature of such failures.
A not-so-encouraging analysis of upgrade failures 2 states that “Although much anecdotal evidence suggests a high frequency of upgrade problems, there is surprisingly little information in the literature characterizing upgrades in detail.” Even the studies that do exist tend to include statements of the form “We did not seek to perform a comprehensive, statistically rigorous survey of upgrade management in the field.”2
The Bathtub Curve
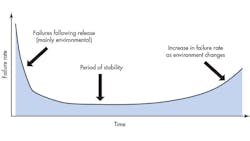
Figure 1 shows the traditional bathtub curve for a software product. Failure rate runs high following the initial release because customers use the product in ways the developers didn’t anticipate and therefore didn’t verify. Once this period passes, the failure rate settles down until changes in the environment (faster processors, changes in memory characteristics, etc.) again invalidate the developers’ assumptions and trigger a rise in failure rate.

To avoid the high initial failure rate, many companies release alpha and beta versions of their products, effectively using the field as a test bed.
Companies rarely release software products once and leave them untouched; rather, it’s common to issue multiple releases (Fig. 2). Each release causes a peak in the failure rate, but hopefully a peak lower than the previous one. The peak arises from bugs present in new function points, from bugs introduced while developers were fixing other bugs in the previous release (another “fact” well known in the software-development community is that, on average, fixing a bug introduces three new ones, one hopes of lesser impact), and from bugs introduced by not considering all of the new product’s potential environments.
As a product matures, each release tends to have fewer new function points, leaving environmental bugs to predominate. This can certainly be seen in the bug reports for the safety-certified products of my employer—careful control of new function points has essentially flattened the curve corresponding to Figure 2 over the last few years.
The spike in the failure rate at each release encourages customers to delay upgrading software until others experience the initial failure spike. One analysis3 of this delay for optimal deployment of security-related fixes states: Upgrade too early and the spike may jeopardize system availability; upgrade too late and hackers may have exploited the security vulnerability to change the dependability of the system.

Available or Reliable?
The term “dependable” incorporates two concepts:
• Available: Does the system respond to requests or, in the case where it must operate continuously to maintain functional safety, does it continue to operate?
• Reliable: Does the system react correctly to the conditions that it’s monitoring?
Designers often conflate these two concepts, but failing to recognize the distinction makes failure analysis difficult because the two actually conflict in many respects. Increasing availability (e.g., by replicating in a 1ooN architecture) will typically decrease reliability and, conversely, increasing reliability (e.g., by using an NooN architecture) will reduce availability. System designers, therefore, must choose between reliability and availability. This raises the question of which is the more important for safety. There is no clear answer—it depends on the purpose of the system and on its design.
Some Numbers
By and large, we only have anecdotal evidence for the frequency and type of failures associated with software upgrades. However, a paper authored by R. Bachwani provides useful numbers.4 He analyzes the 97 genuine bugs that arose in the development of five releases of OpenSSL (4.1p1, 4.2p1, 4.3p1, 4.3p2, and 4.5p1), a system of some 400 files and 50 to 70 thousand lines of code.
Of the bugs found during those release cycles, 40 of the 97 (41%) were caused by the upgrade itself, not by the bug fixing intended for the software upgrade. Of these 40 upgrade bugs, 34 (85%) were caused by factors in the user’s environment (precise version of OS and libraries, state of environment variables, etc.), indicating that the verification performed before release had not considered all of the environmental combinations. The bugs analyzed in the paper were all availability (rather than reliability) bugs.
A Lack of Subtlety
So, is availability or reliability more important in providing continued functional safety? The answer is system-specific—both need to be considered when looking at the effect of a software upgrade. I would argue that reliability problems affect safety more than availability issues, not because availability bugs are less serious, but because they’re typically easier to detect, allowing the system to move to its Design Safe State. A system that simply will not boot—the extreme case of poor availability—should be very safe.
We also have anecdotal evidence that both availability and reliability failures resulting from software updates are rarely subtle: Mrs. Smith receives a telephone bill for several million dollars (reliability); the guidance system sends an aircraft to Belgium rather than Spain (reliability); the entire service provided by a bank disappears (availability); the system with the new software refuses to boot (availability).
It’s not clear whether this lack of subtlety is actually in the nature of software change or we simply don’t notice the $0.13 error in Mrs. Smith’s telephone bill or the error in the guidance system that put the aircraft five meters off course. But, from the limited information that exists, one can argue that an error of several million dollars is more likely than an error of a few cents.
The state space of any software program, particularly one that’s multi-threaded and running on a sophisticated OS, will likely have more states than the universe has nucleons. From the frequent failure of incremental testing (“we have only changed module X, so we only need to run the small subset of our regression test suite that involves X”), we know that even a small step in that state space can result in disproportionally large changes in the output (the so-called butterfly effect). During a software upgrade, the step being taken in the state space is large, particularly if the step is affected by the environment. As a result, the resultant change is unlikely to be subtle.
What Does This Mean for Critical Systems?
We have at least anecdotal evidence that recently upgraded software is associated with an increased failure rate. Those failures are dominated by the incorrect response of the system to environmental conditions, and typically represent large steps in the system’s state space.
This file type includes high resolution graphics and schematics when applicable.
Certified safety-critical software reduces the potential for environmental mismatches, especially when accompanied by a Safety Manual that constrains the software’s use (for instance, the subset of command-line options that users can invoke or the families of processors on which the software may run). These constraints reduce the number of environments that must be verified before release and, thereby, the probability of environmental mismatch.
The large dislocation in the state space caused by the remaining bugs will typically result in easily observable availability problems that, even if missed during verification, will bring the system to its Design Safe State.
In principle, even a small change in the reliability of a safety-critical system could cause a dangerous situation to occur. However, it would seem from the empirical evidence that, while major software upgrades tend to cause availability errors, they are unlikely to cause reliability errors.
Chris Hobbs, software safety specialist, works with the QNX Neutrino OS kernel at QNX Software Systems, specializing in "sufficiently available" software: software created with the minimum development effort to meet the availability and reliability needs of the customer; and in producing safe software (in conformance with standards such as IEC 61508, ISO 26262 and IEC 62304). He earned a B.Sc., Honors in pure mathematics and mathematical philosophy at the University of London.
References
1. Bossavit, Software Engineering: How folklore turns into fact and what to do about it, Leanpub, 2013.
2. O. Crameri, R. Bianchini, W. Zwaenepoel, and D. KostiÄ, Staged Deployment in Mirage, an Integrated Software Upgrade Testing and Distribution System, in Proceedings of the Symposium on Operating Systems Principles, Bretton Woods, 2007.
3. S. Beattie, S. Arnold, C. Cowan, P. Wagle, C. Wright, and A. Shostack, Timing the application of security patches for optimal uptime, in LISA, USENIX, 2002, pp. 233–242.
4. R. Bachwani, Preventing and Diagnosing Software Upgrade Failures, PhD thesis, Rutgers, The State University of New Jersey, Rutgers, The State University of New Jersey, 2012.
About the Author
Chris Hobbs
Chris Hobbs is an OS kernel developer at QNX Software Systems Limited, specializing in "sufficiently-available" software: software created with the minimum development effort to meet the availability and reliability needs of the customer; and in producing safe software (in conformance with IEC 61508 SIL3). He is also a specialist in WBEM/CIM device, network and service management, and the author of A Practical Approach to WBEM/CIM Management (2004).
In addition to his software development work, Chris is a flying instructor, a singer with a particular interest in Schubert Lieder, and the author of several books, including Learning to Fly in Canada (2000) and The Largest Number Smaller than Five (2007). His blog, Software Musings, focuses "primarily on software and analytical philosophy".
Chris Hobbs earned a B.Sc., Honours in Pure Mathematics and Mathematical Philosophy at the University of London's Queen Mary and Westfield College.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: