High-Level Synthesis Uncovers PPA Tradeoffs of Various Hardware Accelerators
A fully programmable digital-signal-processing (DSP) co-processor provides the ultimate in flexibility, making it possible to support many application domains with a single accelerator. For instance, you might switch between processing a video stream and performing voice recognition using the same hardware. A programmable DSP can also adapt to changing standards. This is likely to be the best choice in cases where the power and area budget allows for such flexibility. We’ll call this architecture a programmable accelerator.
This file type includes high resolution graphics and schematics when applicable.
For most applications, however, hard-coded hardware accelerators offer a much more efficient implementation of a single algorithm at the expense of flexibility. For some applications that require extremely low power, such as baseband Long Term Evolution (LTE), it will be the obvious choice. This hardware won’t need to switch application domains. We’ll call this option fixed-function hardware.
A third possible option provides some of the flexibility of a programmable accelerator while still meeting a very tight area and power budget. We’ll call this alternative “configurable hardware.” In this case, the hardware will be limited to a single application domain, but will have configuration registers that allow a host to modify certain aspects of how it processes the data stream.
Finally, extending the programmable DSP with custom instructions targeted at a specific application domain retains the programmable accelerator’s flexibility while reducing power consumption in cases where the workload matches the available custom instructions. We’ll call this a customized programmable accelerator.
Obviously, dramatic differences exist between these architectural options. How can you quickly determine which option delivers the best power, performance, and area (PPA) for your given design? We could write register-transfer-level (RTL) models for all of these options and run a bunch of applications through each to determine the tradeoff, but few development schedules will accommodate that much model development.
For our project, we decided to use high-level synthesis (HLS) to speed up the architectural exploration. We began by evaluating the architecture of a programmable accelerator and a customized programmable accelerator. Then we evaluated the PPA tradeoffs of configurable and fixed-function hardware implementations for some of the same DSP applications.
Evaluation Setup: SystemC Source Code, RTL Simulations, and DSP Algorithms
To conduct our architecture evaluation, we started with some common DSP algorithms used in baseband, video, voice recognition, and PHY processing. We had C code implementations available for each algorithm that was selected. These algorithms were used as test cases for evaluating hardware architectural options.
To express the alternate hardware accelerators, we chose SystemC as the source code for three key reasons: It provides a fast way to express design intent in a manner simpler than an equivalent RTL model; it integrates well with algorithmic C code that’s widely used to define DSP algorithms; and several HLS tools are available that can generate the needed RTL. Once we had RTL for each of the alternate architectures, the existing RTL design tools were able to accurately measure PPA.
First, we designed a fully programmable DSP fabric that could be used for a wide range of applications. Our programmable DSP is written in C code, but features a SystemC class library to allow synthesis into a RTL description. For the programmable DSP, a software toolchain is required to compile the applications into a binary format that can be loaded and run on our hardware. The software toolchain was developed using LLVM and pattern-matching technology. We used this toolchain to compile each algorithmic test case to the executable machine code required by our custom DSP.
With our algorithms in machine code and the hardware implementation of our programmable DSP described in SystemC, we performed design verification by simulating execution of each algorithm on the DSP using behavioral SystemC. Then, using a Cadence HLS tool, we created an RTL implementation of the programmable DSP processor. We performed RTL simulation of the DSP, executing each algorithm to provide the switching activity required for accurate power estimation. Logic synthesis was used to produce a gate-level implementation of the DSP for area estimation.
For a fixed-function hardware accelerator, the test case actually becomes the hardware implementation. This experiment employed a finite-impulse-response (FIR) filter algorithm with 128 taps. We took the public domain C model for this algorithm and embedded it in a SystemC module to add hardware details like pin-level interfaces and concurrency. HLS was used to create an RTL implementation of the algorithm from this SystemC source code. Simulation and logic synthesis on this RTL fixed-function hardware accelerator revealed a massive reduction in area and power compared to the programmable DSP implementation.
For a configurable architecture, we reused the model of the fixed-function hardware just described. An ARM AMBA AXI4 bus slave interface was added to the SystemC model. The AXI4 model, a synthesizable SystemC model developed by Cadence and CircuitSutra, has both TLM- and PIN-level interfaces to support very fast design verification and synthesis. The host processor uses the ARM AMBA AXI4 interface to program the coefficients of the FIR filter. This results in a larger circuit and slightly more power consumption than the fixed-function implementation, but with added flexibility. This configurable accelerator could be applied to a number of different application domains.
Architectural Evaluation
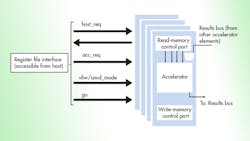
We approached our architectural evaluation with a two-part methodology. One part was the hardware evaluation flow to explore the cost of various instruction/memory configurations. The other was a flexible software flow for mapping various applications to the candidate architecture. The base hardware architecture consists of a host CPU and an accelerator unit (Fig. 1). The accelerator has two memory-controller interfaces (a read and write port controller) and is controlled by a host.
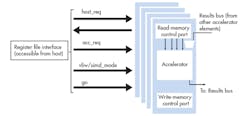
Furthermore, the accelerator consists of a simplified processing element with 1K words of instruction memory, 1K words of data memory, 8 registers, and a 40-bit accumulator with a DSP-oriented instruction set. A “results bus” can feed the result from the execution stage of the accelerator processor to the other accelerators. The host controls the accelerator through a register file.
When arranged in a single-instruction multiple-data (SIMD) configuration under control of the host, each accelerator operates on the same instruction, and data is streamed from the memory as a block. The accelerators can also be arranged in a multiple-instruction multiple-data (MIMD) format; in this mode, the accelerators operate independently and arbitrary memory reads/writes are allowed.
We experimented with the following architectural options to develop an optimal hardware accelerator:
• Varied the number of accelerators to match the amount of parallelism we could extract from the algorithms.
• Varied the memory interface.
• Varied the instruction set to include advanced autonomous DSP instructions.
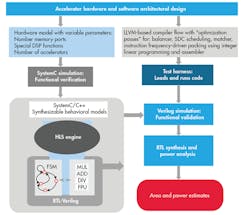
Figure 2 describes our evaluation process. First, we designed an instruction set for individual applications. Then each application was compiled into assembly code, running this against our SystemC model by the test harness. This approach made it possible to create a Verilog RTL model of the hardware with the HLS tool, and run the same assembly code against that Verilog model. We also gained very accurate switching characteristics for doing power analysis. Plus, the Verilog model was synthesized into a gate-level implementation using the RTL synthesis tool. After running all of the tools, we came away with an accurate estimate of power and area for our chosen application.
This flexible software flow included: an XML library enumerating the number of instructions each accelerator can execute, a front end that restructures the control data flow graph produced by a LLVM compiler; a scheduler that exposes instruction-level parallelism within a basic block of instructions; a matcher that maps groups of instructions onto a library of predefined macro instructions expressed in the library; and a resource-driven packer that assigns instructions to accelerators.
Experimenting in Hardware
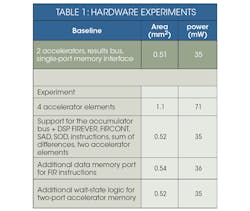
We conducted our hardware experiments using the base architecture, consisting of two accelerators. See Table 1 for results, based on a 45-nm process with a 500-MHz target frequency. The experiments involved:
• Varying the number of accelerator elements. We increased the number of memory ports and replicated the accelerators for a total number of four.
• Adding specialized DSP FIR instructions, including FIRIN and FIREVERIN, for building filters. Here, the accumulator of one accelerator is passed to the next, resulting in a daisy-chain construction of FIR components.
• Adding specialized instructions for sum of differences (SOD), sum of sums (SOS), and sum of absolute differences (SAD) saturation.
• Adding an extra data memory port so that coefficients could be pulled from memory for the specialized FIR instructions.
• Adjusting the memory interface, using four ports versus two.
Ideal Architecture for a Fully Programmable DSP
From those experiments, we determined an ideal architecture for our programmable hardware accelerator. Each accelerator is made up of an array of processing elements (PEs)—each essentially a mini DSP (Fig. 3). Each PE has a memory interface and is mapped into the address space of a host.

The accelerator features:
• SIMD/MIMD modes
• Local instruction memory and data memory
• Support for autonomous FIR instructions (FIREVER, FIRIN), including a memory interface that pumps data through the FIR instructions
• Propagation of unsaturated accumulator results through dedicated “accumulator bus”
• Simplified host interface (The host can read/write to any of the registers for each accelerator)
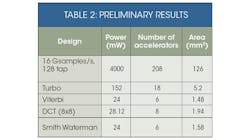
The preliminary results of our final architecture are scaled for a 28-nm process, and each design uses the same target library (Table 2). The 16-Gsample/s, 128-tap FIR required 512 8-tap FIR blocks, with each 8-tap FIR mapped on to one accelerator (with two PEs). The Turbo (LTE) design required 18 accelerators and six memories. The Viterbi design needed six accelerators, each running at 500 MHz.
Introducing complex DSP operations resulted in surprisingly low overhead. We anticipated that adding these instructions would require additional hardware resources in the resultant RTL. However, the HLS tool successfully found a schedule to minimize the use of hardware functional units.
Hard-Coded and Partially Programmable Accelerators
For a hard-coded DSP, the application domain and function of the hardware is fixed. In this case, a hardware implementation can exploit the fact that all coefficients are constant values, and the application C code is directly synthesized into RTL by the HLS tool. For example, the LTE code-block CRC typically includes a hard-coded polynomial, reflected in the structure of an lfsr (24,16, or 8 bit); a programmable implementation would require a generic processor.
To retain some programmability while still reducing area and power, one could instead use a fixed filter chain, but provide programmability for the coefficients (Fig. 4).

Adaptive filtering would be an excellent application for a partially programmable DSP; for instance, the digital pre-distortion filter for an RF power amplifier in a baseband LTE processor. Typical update times are required to be in the order of milliseconds, so a megahertz bus, such as ARM AMBA AXI4, is more than adequate for updating Volterra coefficients. In this case, the partially programmable accelerator may be the only option that will meet both functional requirements as well as size, area, and power limitations.
Using a partially programmable accelerator also streamlines the design flow. The characteristics of the filter can be tested at the input level (SystemC code) and output level (RTL). Evaluating the frequency and time-domain results can provide a view into the quality of the filter implementation.
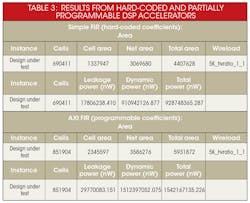
To compare the cost of programmable vs. hard-coded accelerators, we ran the C algorithm for the 128-tap FIR filter through the HLS tool to generate an RTL model. We then ran this fixed hardware implementation through static power analysis. Then, using the same 128-tap FIR filter, we added an ARM AMBA AXI4 slave interface to the SystemC model, synthesized the resulting model to RTL, and ran a static power analysis. Table 3 shows results for hard-coded and partially programmable DSP accelerators.
Hard-Coded vs. Partially Programmable vs. Fully Programmable
Table 4 compares all three implementations for a 16-Gsample/s 128-tap FIR. We can see that a hard-coded implementation for a specific application can significantly save both area and power, at the expense of flexibility. Even the partially programmable option preserves much of the advantage of the hard-coded version, with the added benefit that the hardware can be re-targeted to different application domains.

But perhaps the best choice would be to combine fully programmable and partially programmable accelerators into a customized programmable accelerator. The partially programmable accelerator could then implement fixed instructions for the fully programmable accelerator, offloading some portion of the algorithm. It could greatly improve quality of results (QoR) while still preserving all of a fully programmable accelerator’s benefits.
HLS Tool Turns SystemC Into RTL
Coding style, and how it relates to several factors, was very important for this project. First, there was the question of coding efficiency. Could we write code in a natural “C” coding style and still get good synthesis results? And how did the coding style work for control versus datapath portions of the design?
To illustrate the coding style for control, we can use a portion of the instruction dispatch model:
switch(opcode){
case DMAA:{
HandleDmaa(earg0, earg1, earg2, earg3);
break;
}
case ADD1:{
HandleADD1(earg0, earg1, earg2, earg3);
break
}
case …
}
For our programmable accelerator, it was easy to code the instruction dispatch model as a simple switch statement, depending on the instruction op-code. Each case then represented one of the op-codes for our accelerator. This coding style is natural and extensible. If we wanted to add an op-code, we could simply add another case to the switch. In fact, that’s exactly what we did when adding the FIRIN and FIREVERIN instructions. The HLS tool handled all of the modified state machine’s details.
This represents a good example of the simplicity for coding control in a SystemC model. But what about synthesis efficiency with this coding style? To illustrate synthesis efficiency, consider the source code for the HandleDmaa (double multiply and add to accumulator) function:
sc_uintalu::HandleDmaa( sc_uint arg0, sc_uint arg1, sc_uint arg2, sc_uint arg3) { sc_uint rs3 = rf[arg0]; //read //from register file at address arg0 sc_uint rs2 = rf[arg1]; sc_uint rs1 = rf[arg2]; sc_uint rs0 = rf[arg3]; sc_uint val = rs0 * rs1 + rs2 * rs3; return(val); }
Here, you see that it’s implementing a multiply accumulate. Two multipliers plus one addition operator calculate the result. In our accelerator, several other op-codes also used multipliers and adders. As it turned out, the HLS tool was easily able to determine that those multiply and add hardware elements were in mutually exclusive control branches and, therefore, could be shared. It produced an RTL implementation that shared with whatever control and multiplexing was required for correct operation. We were pleased it did this sharing without requiring a tool directive or some other user intervention.
For an architectural exploration project, it’s critical to have easily configurable source code. The C++ language has many constructs like templates that become quite handy in this respect. We also found it very useful to declare hardware modules as pointers and then use them for loops to construct the netlist. For instance, in the declarative region we can declare a pointer to our module:
module_type * module_name[ACCEL_NUM];
Then in the constructor, we can instantiate the models and hook up the netlist with a for loop:
for(int num = 0; num < ACCEL_NUM; num++){
module_name[num] = new
module_type(const char* name = sc_gen_unique_name(“this_module”));
module_name[num]->clk(sys_clk);
module_name[num]->rst(reset);
etc.
}
As long as ACCEL_NUM is static at compile time, the HLS tool can create an RTL design from this code. This feature allowed us to test many different hardware options from a single set of source code.
Another language feature that simplifies architectural exploration is the handling of arrays. From a simple array dereference, it’s possible to infer any type of memory or register mapping for that array. For instance, in our source code, if we have:
int x = my_array[addr];
then the HLS tool can automatically map my_array to a set of registers or single port memory.
Or, with the help of a directive, it could also be mapped to a dual port memory. All of these architectural tradeoffs can be made with no change to the user’s source code.
For the partially programmable implementation, we used the ARM AMBA AXI4 slave model. The model was constructed using C++ to provide an abstract programmer’s interface for ease of use. It includes both TLM2- and PIN-level models for simulation and synthesis. Since each ARM AMBA AXI4 slave will have a custom set of registers, a custom decoder class has to be written to match ARM AMBA AXI4 addresses to specific hardware registers. The structure of this decoder is primarily a switch/case statement as shown in this code segment:
// The put() method of the decoder is called by the AXI slave interface
// whenever a bus master writes to the address space associated
// with this slave
cds_value put( const sc_uint<32>& address, const sc_uint<32>& data )
{
cds_value result = cds_okay;
// The low 5 bits of the address determine which register is being
// addressed.
switch( address.range(4,0) )
{
case 0:
{ CYN_PROTOCOL("collect_coeffs");
// Address 0 is for all of the coefficients. The master is expected
// to write all 128 coefficients in order since each individual
// coefficient cannot be individually addressed.
local_coeffs.table[count] = ((sc_fixed<36,18>)data)>>8;
count++;
break;
}
case 4:
{ CYN_PROTOCOL("write_coeffs");
// When the master writes address 4 then it has completed writing
// the coefficients. This is also the signal to the filter to start
// processing the data stream.
local_coeffs.table[count] = ((sc_fixed<36,18>)data)>>8;
count++;
coeffs.write(local_coeffs);
// The command channel signals the filter that all of the
// coefficients have been written and it can start processing data.
command.put();
break;
}
case 8:
{ CYN_PROTOCOL("assert_interrupt");
// Address 8 is reserved for signaling the slave that an interrupt
// is pending. This will halt the filter and allow the host to
// reprogram the coefficients.
debug << "assert interrupt" << endl;
int_assert.write(!int_assert.read());
count = 0;
break;
}
default:
{ CYN_PROTOCOL("default");
result = cds_error;
debug << "ERROR: decoder default put:" << address
<< " data: " << data << endl;
break;
}
}
return result;
}
Conclusions
All of our benchmark designs originated from C descriptions. We found it remarkably easy to target all of these algorithms to hardware accelerators. For the programmable hardware, we used a software toolchain to compile the algorithms into executable form. But in the case of the partially programmable and hard-coded accelerators, the C algorithms were directly compiled into RTL. The ease of re-targeting algorithms was actually quite surprising. Very few code modifications were required for any of the algorithms, regardless of the target hardware.
With our chosen HLS flow, we were able to extract parallelism and efficiently implement several DSP functions with minimum hardware. As a result, it was easy to modify the instruction set and test it against our set of applications. We also were able to experiment with complicated instruction control and operations (such as the autonomous FIREVER instruction expressed in terms of C) and let the tool extract the hardware parallelism.
This file type includes high resolution graphics and schematics when applicable.
For HLS, we used the Cadence Forte Cynthesizer tool to synthesize the RTL from our SystemC source code. The tool also provided integrations for running simulation and all RTL synthesis, simulation, and power analysis tools. One of its advantages is the ability to automate data transfer between all of the individual tools. The Cynthesizer solution provided default scripts for running the other tools, helping us customize our own scripts and facilitating the creation of a working design flow.
We wish to acknowledge the helpful discussions with Edvard Ghazaryan, Tigran Sargsyan, and Vigen Gasparyan of RushC LLC Armenia.
About the Author
Steve Anderson
Senior Staff Applications Engineer
Steve Anderson, senior staff applications engineer at Cadence, focuses on high-level synthesis technologies. He also held field applications engineering roles at Summit Design and IKOS Systems, and an ASIC design role at Boeing Aerospace. He earned a bachelor's degree in electrical engineering from the University of Central Florida.
Andy Fox
Sole proprietor of RUSHC
Andy Fox, the sole proprietor of RUSHC, has experience in complex logic design and electronic design automation tool development, especially logic synthesis, logic verification, and algorithms for power optimization and physical logic optimization. Andy holds a joint honors degree in computing and electronics as well as a master's in microelectronics, all from the University of Durham, UK. He also has a PhD in engineering from the University of Aberdeen, UK.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: