Embedded FPGA Optimized for Machine Learning and Communication

I go way back to Burroughs B5500 and IBM 360 mainframes, so the chart (Fig. 1) in Achronix’s Speedcore Gen 4 presentation that included the VAX-11/780 caught my eye. The chart highlights the accelerated growth in performance in the 90s and the leveling off after the turn of the century. We’re now in an era when multiple cores is the way to increase performance, because the penalties due to power dissipation prevent continued jumps in clock speeds.

1. Processor performance is starting to level off. (Source: “Computer Architecture: A Quantitative Approach,” by John L. Hennessy and David A. Patterson)
What’s not shown in the chart is where GPGPUs added to the performance boost. GPGPUs increased the number of cores significantly, bringing a matching rise in computational performance.
Machine learning (ML) is that latest consumer of processor performance—and its appetite seems to be insatiable. Multicore CPUs and GPGPUs have been applied to the problem, and dedicated accelerators are being designed and used when possible, but adapting to new ML models can be a challenge for fixed architecture accelerators. This is one area where FPGAs, with their adaptability, come into play. In particular, embedded FPGAs (eFPGAs) may provide the optimum balance between configurability and performance.
Achronix’s latest eFPGA is Speedcore 7t Gen 4. It includes a number of enhancements tailored to high bandwidth and ML applications. These changes also provide a performance boost for conventional FPGA applications as well.
Better Blocks
The first step was the enhancement of the logic blocks available for building a system. Achronix applies a columnar approach to building an eFPGA (Fig. 2). Developers can choose the number and type of blocks used in each column that are knitted together with two types of FPGA interconnects. More on this later.
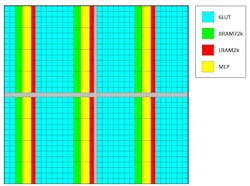
2. Achronix’s column approach to eFPGAs allows developers to choose the type of blocks in each column, such as the new machine-learning processor (MLP) block.
The enhanced logic blocks include an 8-to-1 multiplexer; an 8-bit ALUe that has twice the density of a typical FPGA adder block; an 8-bit, cascadable MAX function; dedicated shift registers; a six-input LUT; and two registers added to the output of a LUT. The six-input LUTs are optimized for efficient LUT-based multiplication of low-precision functions such that the number of LUTs needed for many applications can be cut in half. All of these enhance the support for ML applications and are handy for FPGA designs in general. These are added to the existing set of blocks, including the DSP64 block that’s useful in applications like 5G.
Another new block is the 750-MHz machine-learning processor (MLP) block. It’s optimized for efficient, large-scale neural-network (NN) matrix-vector multiplications. Each MLP block can be configured as a single 16-by-16 multiplier or 16, 4-by-4 multipliers. It supports fixed-point data for inference ML applications as well as Bfloat16, 16-bit floating point, 24-bit floating point, and block floating-point formats for ML training. The block also supports multiple rounding and saturation options. The MLP blocks in a column can be cascaded, providing data interchange that’s faster than using the usual FPGA interconnect.
The two FPGA interconnects mentioned earlier include the conventional FPGA interconnects and a programmable switch fabric. The two work together to provide logic interconnects as well as block-oriented communication bus support. The switch fabric features nodes that have a 4-to-1 bus router. These can be cascaded to provide data movement of an arbitrary size such as an 8-bit byte.
The fabric is much more efficient than using the conventional FPGA routine and LUTs. It implements point-to-point communication, but the connectivity can change on a per-clock-cycle basis and the design tools can include buffer registers as necessary. This is handy for moving data across a large eFPGA.
Support included in Achronix’s ACE design tool handles the routing fabric and the creation of routing and configuration mechanisms. ACE also facilitates eFPGA design by allowing customers to dial in the number of LUTs, memory, LRAM, MLP, and custom blocks. This allows Achronix to deliver a design within six weeks.
Overall, the Speedcore improvements deliver a 60% performance boost in general and a 300% increase for ML applications, all the while cutting power requirements in half and decreasing the area by 65%. Part of this is due to the use of TSMC’s 7-nm transistor technology. Most of the ML improvements are architectural enhancements. That’s one reason why Acrhonix is following up this release with Gen 4 support for 16-nm technology.
The growth of eFPGAs has been substantial, and they provide a significant and optimized option for developers who are designing their own ASICs. Some vendors that support both eFPGAs and commercial FPGAs are rolling this type of functionality into the mainstream FPGAs. However, eFPGAs will always have the advantage since they can dispense with unneeded support while doubling down in other areas.
Of course, the question is: Where will the next performance boost come from after eFPGAs are the norm.

About the Author

William G. Wong
Senior Content Director - Electronic Design and Microwaves & RF
I am Editor of Electronic Design focusing on embedded, software, and systems. As Senior Content Director, I also manage Microwaves & RF and I work with a great team of editors to provide engineers, programmers, developers and technical managers with interesting and useful articles and videos on a regular basis. Check out our free newsletters to see the latest content.
You can send press releases for new products for possible coverage on the website. I am also interested in receiving contributed articles for publishing on our website. Use our template and send to me along with a signed release form.
Check out my blog, AltEmbedded on Electronic Design, as well as his latest articles on this site that are listed below.
You can visit my social media via these links:
- AltEmbedded on Electronic Design
- Bill Wong on Facebook
- @AltEmbedded on Twitter
- Bill Wong on LinkedIn
I earned a Bachelor of Electrical Engineering at the Georgia Institute of Technology and a Masters in Computer Science from Rutgers University. I still do a bit of programming using everything from C and C++ to Rust and Ada/SPARK. I do a bit of PHP programming for Drupal websites. I have posted a few Drupal modules.
I still get a hand on software and electronic hardware. Some of this can be found on our Kit Close-Up video series. You can also see me on many of our TechXchange Talk videos. I am interested in a range of projects from robotics to artificial intelligence.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: