Flex Logix Takes an FPGA Approach to AI

Flex Logix is known for its embedded FPGA (eFPGA) like its EFLX GP14LPP. It can handle chores like crunching deep-neural-network (DNN) and convolutional-neural-network (CNN) models. However, like many FPGAs, this tends to be suboptimal compared to a dedicated machine-learning (ML) accelerator. There are advantages to using an FPGA since other, related logic can surround such a system, and FPGAs provide a level of flexibility and performance not found in software.
Still, the components within an FPGA can be advantageous to ML designers—in fact, many similarities exist between a dedicated ML accelerator and an FPGA. This is where Flex Logix’s NMAX (Fig. 1) comes in. It’s embedded IP like Flex Logix’s eFPGA solutions. And like an eFPGA, it has a regular, scalable layout, but the tiles are much larger to accommodate the additional logic and communication needed for ML applications.
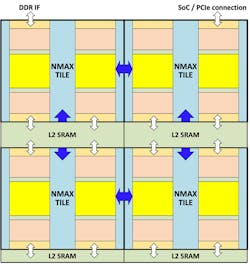
1. Flex Logix’s NMAX is a tiled machine-learning accelerator that can be scaled to handle larger applications. Communication between adjacent tiles is managed by the ArrayLINX interconnect.
Each tile is designed to handle a subset of an ML model or similar application, as these are programmable hardware blocks. Communication between adjacent tiles is handled by the ArrayLINX interconnect.
The shared L2 SRAM is scalable and provides a slower yet larger alternative to the SRAM contained in within the NMAX tile. The L2 SRAM typically contains all of the weights for each layer within an ML model, while the weights for the currently active computation are in the tile’s memory. This approach minimizes the memory traffic needed to update the weights throughout the model’s computation, which is typically the bottleneck in other ML accelerators that utilize external DRAM. The ability to keep the weight storage closer to the computation engine is critical to the system’s overall efficiency, but more on that later.
Each tile includes the EFLX logic, Flex Logic’s FPGA logic, and the NMAX clusters all surrounded by the XFLX interconnect (Fig. 2). The latter is akin to the FPGA routing logic but optimized for NMAX. It ties into the ArrayLINX communication between tiles. Data can move in any direction through the array. The EFLX logic is used to customize the system and typically includes a state machine to manage the ML processing and communication. The L1 SRAM is key to the system’s efficiency since it can be scaled to handle weights and activation information based on the application.
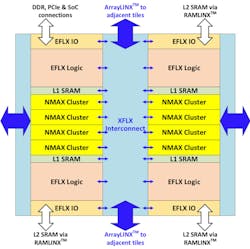
2. Each NMAX tile includes multiple NMAX computational clusters, EFLX FPGA logic for configuration, XFLX interconnects, and local SRAM.
Access to the L2 SRAM is done using RAMLINX connections available to the EFLX FPGA logic rather than the ArrayLINX connection. This allows the control logic to quickly move new activation and weight configurations into the L1 RAM and eventually into the NMAX clusters where the 8- and 16-bit matrix manipulation is done.
A tile delivers 1 trillion operations per second (TOPS). It also requires about a tenth the power of competing systems with a similar cost reduction. Now this is where things get interesting. Numerous ML systems provide benchmark results for models like ResNet-50. Many results will include the batch size because this is key to understanding how these benchmarks are run. The batch size indicates how items are presented to the system before details like the weights and activation data must be changed.
Batching actually makes a lot of sense for training and cloud-based inference when multiple data streams are used. However, a large batch size is useless in terms of inference when a single item, like the current frame from a camera, is being processed. In this case, more useful information about a high frame rate is needed using a batch size that’s one, or low values such as for four surround-view cameras. Again, this is where NMAX stands out (Fig. 3).

3. NMAX shines as the batch size moves to one, which is what’s needed by most edge-node inference applications.
NMAX can deliver over 1200 frames/s if the model fits solely into L1 and L2 SRAM. The note in the diagram about one or two DRAMs is because two will provide additional bandwidth. Of course, a DRAM will have much more storage available and can hold lots of models, but that’s rarely needed in an edge application. In these cases, the amount of DRAM used is actually a fraction of the smallest available DRAM.
This comes back to the dilemma embedded developers always face: Finding parts that match the requirements of their system when those requirements are outside of the mainstream. NMAX can work with DRAM and most applications will likely include it. However, most of the storage will be used for other information like buffering input data.
When discussing ML accelerator efficiency, it’s necessary to consider the MAC efficiency since systems rarely run at 100% efficiency. For example, a MAC can only do its thing if the weights for the computation are available, the data coming in is available, and there’s space to store the results. Even using a MAC that has zero overhead will result in a slow system if the other factors incur lots of overhead. That’s why having weights available in local memory are key to system efficiency.
The performance numbers for NMAX are impressive. A 6-×-6 array of tiles delivers performance on par with NVIDIA’s Tesla T4 (Fig. 4). That would be one tiny chip versus a rather large PCI Express card. On the other hand, the T4 excels at training as well, where NMAX doesn’t have the same types of advantages as it does for inference. Still, its MAC is only running at 58% efficiency while turning out 34 GB/s of throughput with its SRAM and 32 ms of latency. A 12-×-12 array delivers almost 100 TOPS with 67% MAC utilization and only 8 ms of latency. The results are for tests using the YOLOv3 model with a 2048- × 1024-pixel image stream, a batch size of one, and a pair of 4-Gb LPDDR4 DRAMs. The top end is almost 10X faster than a GPU while still be configurable hardware.
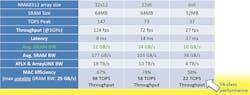
4. A 6-×-6 NMAX array delivers performance that rivals NVIDIA’s Tesla T4 Tensor Core GPU.
These days, ML models on the edge doing inference are more apt to be like the YOLOv3 model that tracks up to 80 classes of objects. Likewise, many applications will need a batch size of one, with a single camera and a frame rate of at least 30 frames/s. It’s something a system-on-chip (SoC) with an NMAX array can easily handle. The only platform that comes close at this point is Habana’s Goya, which also targets edge inference.
Flex Logix’s NMAX neural-network compiler takes models from frameworks like Caffe and TensorFlow and maps them to the array, splitting things as necessary to fit into the allotted memory and computational arrays.

About the Author

William G. Wong
Senior Content Director - Electronic Design and Microwaves & RF
I am Editor of Electronic Design focusing on embedded, software, and systems. As Senior Content Director, I also manage Microwaves & RF and I work with a great team of editors to provide engineers, programmers, developers and technical managers with interesting and useful articles and videos on a regular basis. Check out our free newsletters to see the latest content.
You can send press releases for new products for possible coverage on the website. I am also interested in receiving contributed articles for publishing on our website. Use our template and send to me along with a signed release form.
Check out my blog, AltEmbedded on Electronic Design, as well as his latest articles on this site that are listed below.
You can visit my social media via these links:
- AltEmbedded on Electronic Design
- Bill Wong on Facebook
- @AltEmbedded on Twitter
- Bill Wong on LinkedIn
I earned a Bachelor of Electrical Engineering at the Georgia Institute of Technology and a Masters in Computer Science from Rutgers University. I still do a bit of programming using everything from C and C++ to Rust and Ada/SPARK. I do a bit of PHP programming for Drupal websites. I have posted a few Drupal modules.
I still get a hand on software and electronic hardware. Some of this can be found on our Kit Close-Up video series. You can also see me on many of our TechXchange Talk videos. I am interested in a range of projects from robotics to artificial intelligence.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: