Neural-Network Hardware Drives the Latest Machine-Learning Craze

Download this article in PDF format.
Artificial-intelligence (AI) research covers a number of topics, including machine learning (ML). ML covers a lot of ground as well, from rule-based expert systems to the latest hot trend—neural networks. Neural networks are changing how developers solve problems, whether it be self-driving cars or the industrial Internet of Things (IIoT).
Neural networks come in many forms, but deep neural networks (DNNs) are the most important at this point. A DNN consists of multiple layers, including input and output layers plus multiple hidden layers (Fig. 1). The number of nodes depends on the application; each node has a weight associated with it. An input, such as an image, is supplied at one end and the outputs provide information about the inputs based on the weights.
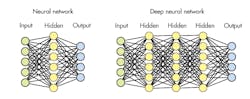
1. Deep neural networks (right) have multiple hidden layers.
The magnitude of the inputs, weights, and calculations done at each node are of no importance in a logical sense. However, they’re crucial in terms of implementation, because this affects the amount of computational performance necessary for a system, as well as the amount of power required to perform the calculations. The fewer bits involved, the lower the performance and power requirements; hence, a more efficient implementation.
As it turns out, the number of bits used to encode weights and calculations done can often be significantly reduced—sometimes to a single bit—although eight bits is typically sufficient. Some implementations even employ small floating-point encodings, since the number of significant digits is less important than a value’s potential range.
Training and Inference
There are different ways to create and implement DNNs. The typical method is to design a network and then train it. Training consists of presenting input data and matching results so that the weights in the nodes within the DNN matrix are adjusted with each new piece of information.
The architecture of a DNN is simple, but not so much when it comes to design and implementation. The overall system results can be affected by a number of issues, from the format, size, and quality of the input to the type of output desired. Likewise, the training process of a successful design assumes that the model will converge over time as more examples are presented. In essence, the system comes to recognize the desired characteristics.
The resulting weights and network model are then used as an inference engine. In this case, there’s no change to the network while in use. Essentially all of the machine learning (ML) for this type of system is done in the training session. A better implementation with more training or a different model can replace an existing implementation if additional input is available.
For example, an image-recognition system in a car could also record images that would subsequently be sent to the cloud for additional training. This would allow thousands of cars to provide information to a cloud-based training system, which in turn would generate an improved model that could be distributed to those cars in the future after testing. It’s probably not a good idea to have a self-direct learning system for each car that would change on its own, because it would be difficult to determine if the training was improving the system or not.
Trained models can often be optimized so that the inference engine employs smaller weights or uses fewer resources. For example, the number of bits utilized for weights and calculations may be reduced but provide the same or similar results. Keep in mind that a DNN is designed to deliver probabilities as results, and it’s possible that false-positive and false-negative results can be generated. The idea of a good design is to minimize or effectively eliminate these, especially in safety-related applications like self-driving cars, but these consequences in other applications may be more than acceptable.
Different Neural Networks
Convolutional neural networks (CNNs) are a specific type of DNN. CNNs are normally used for image recognition. There’s also recurrent neural networks (RNN) designed to address temporal behavior, allowing the system to address problems such as speech and handwriting recognition. RNNs can be used for a variety of audio and video processing applications, too.
Another type of neural network is the spiking neural network (SNN). Unlike a DNN, where information always propagates through the network, an SNN has nodes that trigger when a threshold is reached. The output can actually be a train of signals from the system, rather than values, as results for all outputs in a DNN. This is more akin to how the brain operates, but it’s still an approximation.
“Spiking neural networks, considered by many to be the next generation of artificial intelligence, is based on an explicit incorporation of time in the form of events or spikes for representation of data,” says Nara Srinivasa, CTO of Eta Compute. “When this representation is sparse and the hardware that runs these models is fully asynchronous, these event-driven networks can learn to solve machine-learning-type problems at a fraction of the power consumption of machine-earning approaches today.”
SNNs can often address applications that DNNs and their ilk are less adept at performing. For example, a DNN trained to recognize flowers in images can now be used to scan new images to find things that look like a flower, but it may be difficult to selectively identify a particular type of flower. An SNN can often do the latter; however, it may be less effective identifying anything that looks like a flower.
The challenge for developers new to this space is that high-level ideas like DNNs and machine learning are easy to appreciate. The sticking point is that no one solution that works best all of the time. Likewise, the tradeoffs in designing, implementing, and delivering a system can be difficult to address because of the number of options as well as the implications of choosing among them. In addition, the tradeoffs in training, accuracy, and speed may make some applications possible, while others become out of reach.
Implementation issues are further complicated because hardware optimization can significantly affect the performance of a system. As noted, different possible implementation criteria and hardware optimized for one approach may be unsuitable or even useless for another.
Specialized ML Hardware
Hardware acceleration can significantly improve machine-learning performance across the board. Some hardware is often targeted at training, while other hardware may be optimized for inference chores. Sometimes a system can do double duty. In certain cases, the hardware can reduce the power requirements so that a system can run off of very little power, including battery-operated environments.

2. Google’s TensorFlow Processing Unit (TPU2) delivers 45 TFLOPS. The newer TPU3 is eight times more powerful.
At one end of the spectrum is Google’s TensorFlow Processing Unit (TPU2). TensorFlow is one of the more popular ML frameworks. The TPU2 (Fig. 2) is designed for the cloud where dozens or hundreds of TPU2 boards would be used to handle a range of training and inference chores.
Unlike many ML accelerators, the TPU2 targets a subset of the computing used in a DNN model. Of course, it targets the area that’s the most computationally intensive, allowing the host processor to fill in the blanks. Each of the TPU2 chips has 16 GB of high bandwidth memory (HBM) supporting a pair of cores. Each core has a scalar floating-point unit and 128-×-128, 32-bit floating-point mixed multiply unit (MXU). It can deliver 45 TFLOPS of processing power.
Google has already announced the TPU3. It’s eight times more powerful than the TPU2, and is water-cooled.
At the other end of the spectrum is Intel’s Myriad X visual processing unit. The Myriad X includes 16, 128-bit VLIW SHAVE (Streaming Hybrid Architecture Vector Engine) processors. It also has a pair of 32-bit RISC processors along with hardware accelerators and neural-network hardware. Its 16 MIPI lanes support up to eight HD cameras. The earlier Myriad 2 was used in DJI’s Spark drone (Fig. 3). It allows a drone’s camera to recognize gestures in order to perform functions such as framing and taking a photo.

3. DJI’s SPARK drone uses Intel’s Myriad 2 visual processing unit (VPU) with ML support to recognize gestures such as framing and taking a picture.
These are just two examples of dedicated ML hardware.
GPGPUs and FPGAs Do AI
Dedicated hardware isn’t the only way to support machine learning. In fact, conventional CPUs were used initially, but alternatives typically provide much better performance, making it possible to employ much larger and more complex models in applications. Likewise, many applications require a range of models to operate on different data. Self-driving cars are good example—multiple models would be employed for different functions, from analyzing an engine’s performance to recognizing people and cars around the vehicle.
Two frequently used platforms in ML applications are GPGPUs and FPGAs. As with dedicated hardware, developers need to consider many options and tradeoffs. These types of platforms provide more flexibility since they depend more on the software. This tends to make it easier to support a wider range of models and methodologies as well as support new ones. Dedicated hardware is generally more limited.
These days, the GPGPUs from Nvidia, AMD, Arm, and Intel can be used for computation, not just for delivery of flashy graphics on high-resolution displays. In fact, GPGPUs dedicated to computation with no video outputs are common and target ML applications in the cloud. This works equally well for GPGPUs in desktops, laptops, or even system-on-chip (SoC) platforms.
Part of the challenge for GPGPUs and FPGAs is that they were tuned for different applications. For example, single- and double-precision floating-point matrix operations are quite useful for everything from simulating weather to finding gas and oil from sensor information. Higher precision is usually an advantage.
Unfortunately, DNNs and the like may underutilize this type of precision, as noted earlier. Still, GPGPUs and FPGAs often handle small integers well, and the latest generation of these platforms is being tailored to handle the types of computations needed for ML applications. On the plus side, many applications will require additional processing that these platforms already support to massage incoming data or process results. Overall, such platforms are more adaptable to a wider range of programming chores.
FPGAs have an edge when it comes to adaptability. This can be especially useful where methodologies are still changing, and new approaches may require different hardware acceleration. GPGPUs will work well if the application fits the hardware.
Andy Walsh, Senior Director, Strategic Marketing at Xilinx, notes “Artificial intelligence is a hotspot of innovation in computing today. But to stay best-in-class, both network models and acceleration algorithms must be constantly improved. To keep pace with the design cycles in AI, developers are looking for more than just a chip. They need a computing platform that is highly performant and adaptable.
Recognizing this need, we’ve recently unveiled a new product category that goes far beyond the capabilities of an FPGA. The breakthrough adaptive compute acceleration platform from Xilinx is a highly integrated, multi-core, heterogeneous platform that can be programmed at the hardware and software levels. Using tools familiar to developers, an adaptive compute acceleration platform (ACAP) can be tuned to deliver performance and power efficiency for AI inference that outshines any other processing platform.”

4. Embedded FPGAs (eFPGAs) like Flex Logix Technologies’ EFLX 4K AI are delivering building blocks optimized for today’s ML frameworks.
Embedded FPGAs (eFGPAs) are being quick to embrace machine learning. For example, Flex Logix Technologies' EFLX 4K AI (Fig. 4) has DSP blocks that can deliver 10 times the MACs compared to the EFLX 4K DSP that employs typical FPGA DSP blocks. The AI DSP block eliminates logic not required for ML matrix operations and is optimized for 8-bit configurations common in ML applications. The AI DSP blocks can also be configured as 16-bit MACs, 16-×-8 MACs, or 8-×-16 MACs.
AI eFPGAs allow a designer to incorporate just the amount of ML computational power needed for an application. A smaller, more power-efficient version might be used with a microcontroller, while larger arrays could be used where more performance is needed.
Software Makes AI Work
Regardless of the hardware used, ML and AI applications need software to take advantage of the hardware. On the plus side, vendors of general hardware such as CPUs, GPUs, and FPGAs are delivering software that works with the standard machine-learning frameworks. This means that applications developed on the frameworks can be ported to different hardware, giving developers a choice of what hardware will be used in a particular application.
Choosing which hardware platform to use for an application can be difficult, since different approaches may offer performance and efficiency levels that vary by an order of magnitude. Likewise, the AI portion of an application may only be a fraction of the code involved, even if it requires a significant portion of the computational support.

About the Author

William G. Wong
Senior Content Director - Electronic Design and Microwaves & RF
I am Editor of Electronic Design focusing on embedded, software, and systems. As Senior Content Director, I also manage Microwaves & RF and I work with a great team of editors to provide engineers, programmers, developers and technical managers with interesting and useful articles and videos on a regular basis. Check out our free newsletters to see the latest content.
You can send press releases for new products for possible coverage on the website. I am also interested in receiving contributed articles for publishing on our website. Use our template and send to me along with a signed release form.
Check out my blog, AltEmbedded on Electronic Design, as well as his latest articles on this site that are listed below.
You can visit my social media via these links:
- AltEmbedded on Electronic Design
- Bill Wong on Facebook
- @AltEmbedded on Twitter
- Bill Wong on LinkedIn
I earned a Bachelor of Electrical Engineering at the Georgia Institute of Technology and a Masters in Computer Science from Rutgers University. I still do a bit of programming using everything from C and C++ to Rust and Ada/SPARK. I do a bit of PHP programming for Drupal websites. I have posted a few Drupal modules.
I still get a hand on software and electronic hardware. Some of this can be found on our Kit Close-Up video series. You can also see me on many of our TechXchange Talk videos. I am interested in a range of projects from robotics to artificial intelligence.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: