
There are a number of machine learning (ML) architectures that utilize deep neural networks (DNNs), including AlexNet, VGGNet, GoogLeNet, Inception, ResNet, FCN, and U-Net. These in turn run on frameworks like Berkeley’s Caffe, Google’s TensorFlow, Torch, Microsoft’s Cognitive Toolkit (CNTK), and Apache’s mxnet. Of course, support for these frameworks on specific hardware is required to actually run the ML applications.
Each framework has advantages and disadvantages. For example, Caffe is an easy platform to start with, especially since ones of its popular uses is image recognition. It is also fast and often the first framework supported by hardware. TensorFlow tends to be easier to deploy with simpler model definitions, as well as better support or GPUs. There are also accelerators specifically designed for TensorFlow like Google’s TensorFlow Processing Unit (TPU). It also handles multiple machine configurations better.
Two platforms that support TensorFlow are NVIDIA’s Jetson TX2 and Intel’s Movidius chips (Fig. 1). Intel’s TensorFlow support for Movidius is new. It addresses the range of Movidius chips that have been used in DJI’s SPARK drone for tracking user gestures visually for real-time control of the system. The Movidius Neural Compute Stick Software Development Kit (SDK) now supports TensorFlow as well as Caffe frameworks.

NVIDIA has also added native support for TensorFlow in its latest TensorRT 3 release. TensorRT 3 is part of the NVIDIA Deep Learning SDK. TensorRT is an inference accelerator for NVIDIA GPUs that provides orders of magnitude of performance improvement for inferencing and supports most common frameworks. (Fig. 2). The SDK actually includes a number of other tools such as the cuDNN deep learning primitives; the cuBLAS GPU -accelerated BLAS linear algebra libraries, and the cuSPARSE sparse matrix operations library.
In addition, NVIDIA’s DeepStream SDK with a C++ API and runtime for GPU-accelerated transcoding and deep learning inference is now available.
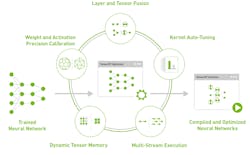
The NVIDIA SDK also supports the Multi-GPU Communication through NCCL that is designed to link up to eight GPUs and NCCL2 that enables multi-GPU multi-node configurations for scaling deep learning training. NVIDIA’s SDK supports Caffe, Chainer, DL4J, Keras, Microsoft CNTK, MatConvNet for MATLAB, mxnet, Minerva, Purine, Theano, and Torch. Developers might also want to check out the NVIDIA Deep Learning GPU Training System (DIGITS). DIGITS 6 supports several frameworks, including TensorFlow, and has a pre-trained UNET model.

About the Author

William G. Wong
Senior Content Director - Electronic Design and Microwaves & RF
I am Editor of Electronic Design focusing on embedded, software, and systems. As Senior Content Director, I also manage Microwaves & RF and I work with a great team of editors to provide engineers, programmers, developers and technical managers with interesting and useful articles and videos on a regular basis. Check out our free newsletters to see the latest content.
You can send press releases for new products for possible coverage on the website. I am also interested in receiving contributed articles for publishing on our website. Use our template and send to me along with a signed release form.
Check out my blog, AltEmbedded on Electronic Design, as well as his latest articles on this site that are listed below.
You can visit my social media via these links:
- AltEmbedded on Electronic Design
- Bill Wong on Facebook
- @AltEmbedded on Twitter
- Bill Wong on LinkedIn
I earned a Bachelor of Electrical Engineering at the Georgia Institute of Technology and a Masters in Computer Science from Rutgers University. I still do a bit of programming using everything from C and C++ to Rust and Ada/SPARK. I do a bit of PHP programming for Drupal websites. I have posted a few Drupal modules.
I still get a hand on software and electronic hardware. Some of this can be found on our Kit Close-Up video series. You can also see me on many of our TechXchange Talk videos. I am interested in a range of projects from robotics to artificial intelligence.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: