Software Process Standards Ensure Safe Transportation
The automotive industry has launched functional safety to the front and center of newscasts these days. Late last year, Toyota hastily settled an “unintended acceleration” lawsuit only hours after an Oklahoma jury determined that the automaker acted with “reckless disregard.” Toyota delivered a $3 million settlement to the plaintiffs before the jury could determine punitive damages.1 GM and its faulty ignition switch are commanding equal concern.
Related Articles
- Solve The Software Standards Maze
- MISRA C:2012: Plenty Of Good Reasons To Change
- 10 Standards Organizations That Affect You (Whether You Know It Or Not)
While the evidence in the Toyota case mentions coding standards such as MISRA C, the problems went far deeper than the way the code itself was written. Safety Research & Strategies also noted that Phillip Koopman and Michael Barr, the plaintiff’s software experts, provided fascinating insights into the many problems with Toyota’s software development process and its source code. The list of deficiencies in process and product was lengthy.
So what could have been done differently? Sure, the code could have followed MISRA recommendations. But the implication here is that coding standards aren’t enough on their own. If functional safety is to be ensured, then the whole development life cycle needs to adhere to best practices. For that, we can turn to the process standards.
The myriad industry-specific variations for these standards are perhaps surprising given that critical software has to work and work properly, no matter what industry it is applied to. So why is there a distinction between a critical medical application and one for a railway locomotive or an automobile?
This file type includes high resolution graphics and schematics when applicable.
Industry Process Standards And Software Certification
Most process standards prescribe a methodology for the development of a safety-critical application and usually deal with both hardware and software considerations. Regardless of the industry, process standards have several common threads, including:
• Requirements traceability
• Use of established design principles
• Application of software-coding standards
• Control and data flow analysis• Requirements-based test
• Code coverage analysis
The evidence of a need for these processes has accumulated across several industries. In 2011, a Chinese train rammed another train that had stalled in front of it. State media said a power failure knocked out an electronic safety system that should have alerted the train to the problem.2 In 2009, LG recalled 30,000 Spyder mobile phones due to dropped or poor connections on emergency calls. Also in 2009, Cardinal Health initiated the recall of more than 200,000 Alaris infusion pump systems when the company notified purchasers about hardware and software problems that could prove deadly to patients.
Similar problems in aerospace do happen but they are notably rarer, and it is no coincidence that the DO-178 standard has been around for considerably longer than its counterparts in other industries (see the table). Adherence to DO-178 is “policed” by designated engineering representatives (DERs), who have the power to approve or veto a product’s fitness for purpose.
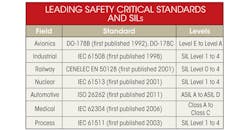
Unlike DO-178, there are usually no “policeman” figures enforcing adherence to the other process standards. For example, right now there is no obligation for automotive software to comply with ISO 26262, IEC 61508, or any other similar standards. Also, there is no overriding authority to say that a car cannot be sold without compliant software. That said, there is no doubting that the “unintended acceleration” lawsuit has been highly effective in focusing the attention of auto manufacturers worldwide and that the interest in ISO 26262 and similar automotive standards has increased dramatically.
For the most part, the standards like ISO 26262, which are derived from IEC 61508, are similar. They set out processes (including a risk management process), activities, and tasks required throughout the software lifecycle, stipulating that this cycle does not end with product release, but continues through maintenance and problem resolution as long as the software is operational. Ultimately, IEC 62304, IEC 61508, and other like standards provide guides and measures used to demonstrate that systems meet their safety requirements.
Safety Integrity Levels
An example of commonality between the standards is the use of classifications according to risk, often called safety integrity levels (SILs). Each of the standards requires a risk assessment to be completed for every software project to decide the appropriate assessment safety level of each part of the system. The more significant the risk of failure for that system, the more rigorous the process needs to be and the more thorough the testing that will be necessary.
However, these SILs also highlight how each standard is tuned to existing best practice in the industry it targets. In each case, in assigning an appropriate SIL, there is a need to balance the likelihood of failure and the consequences should it occur. What differs between the standards is the process for determining the level of risk.
For example, in IEC 61508, a requirement for SIL 3 is defined as corresponding to an equivalent failure rate range of 1 x 10–8 to 1 x 10–7 failures per hour when subject to continuous operation, but only 1 x 10–4 to 1 x 10–3 failures per hour for systems that operate intermittently. While this works for industrial safety compliance, it’s not a concept that can be applied readily to aircraft.
In aerospace, the DO-178 requirement of Software Level A corresponds to a failure rate requirement of 1 x 10–9 per flying hour. In layman’s terms, that implies that the consequences of a Level A failure are such that it would be almost impossible.
The ISO 26262 approach to the derivation of automotive safety integrity levels (ASILs) draws on the automotive industry’s own best practice of mathematically derived dependability data such as statistical process control and six sigma availability (Fig. 1).
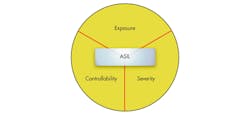
The ASIL is assigned based on the risk of a hazardous event occurring taking account of the frequency of the situation, the impact of possible damage, and the extent to which the situation can be controlled or managed. This definition neatly addresses a criticism of unqualified dependability data in that, for example, 99.999% availability can imply very different things depending on the distribution of the failures.
For instance, a claim of five-nines dependability for a car’s braking system has very different implications if the 0.001% failure (about 5.25 minutes per year) occurs all at once or if it is spread across 1 million distinct instances of 316 µs (also 0.001% failure). One 5.25-minute failure can mean a catastrophe, while 1 million separate 316 µs failures may have no effect on the system’s dependability. In ASIL terms, that means that the severity of the latter failure mode would be nil.
The medical industry’s approach also draws on the sector’s existing best practice, so IEC 62304 draws on established industry-specific practices to complement the principles of IEC 61508. Unlike ISO 26262 or even IEC 61508 itself, IEC 62304 does not define common numerical values for acceptable failure rates (a SIL rating). Instead, it defines safety classifications according to the level of harm a failure could cause a patient, operator, or other person. These classifications are analogous to the Food and Drug Administration (FDA) classifications of medical devices: A (no possible injury or damage to health), B (possibility of non-serious injury or harm), and C (possibility of serious injury or harm, or death).
Other Distinguishing Features
Existing best practise is only one influential factor in the differences between process standards. For example, ISO 26262 is focused on the automotive sector, which deals with much higher volume products in comparison to the comparatively low-volume production of airplanes and medical devices.
The starting point for even the IEC 61508 document on which ISO 26262 was based is a philosophy aimed at one-off or low-volume systems. It regards each potentially hazardous piece of equipment or system as equipment under control (EUC). The EUC is combined with an EUC control system (ECS), which is typically an electronic unit. This combined EUC-ECS system then is controlled by a third supervisor system, the safety related function (SRF). Its purpose is to watch over the EUC-ECS system, ensuring that no potential hazards stem from it (Fig. 2).
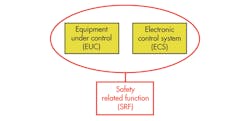
In contrast, the starting point of the ISO 26262 standard assumes that projects consist of developments of, or modifications to, cars or car parts. There is a presumption of high-volume systems that usually existed before, but not in the identical form. Therefore, the basic philosophy of ISO 26262 regards the vehicle itself as inherently safe on the grounds that cars already exist with an acceptable level of safety, and it is “proven in use” this way.3
The basis for the standard is that any modification or addition should not compromise this assumption of safety. That applies even to a completely new vehicle, since it follows that if each new addition to it adheres to this philosophy then the sum of the safe component parts will also be safe.
To summarize, the philosophies of the two standards are dictated by the nature of the industry they apply to and by a pragmatic assessment of how best practices might be applied given the circumstances implied by those industries.
More Similarities Than Differences
Despite these examples of divergence, very many best practices for safety-critical applications are common across the different industries. For example, requirements traceability is widely accepted through the process standards as a development best practice to ensure that all requirements are implemented and that all development artefacts can be traced back to one or more requirements. The railway industry’s EN 50128 is typical in that it requires bi-directional traceability and has a constant emphasis on the need for the derivation of one development tier from the one above it and for the links between these tiers to be maintained at all times:
“10.4.18 Within the context of this standard, and to a degree appropriate to the specified software safety integrity level, traceability shall particularly address: i) traceability of requirements to the design or other objects which fulfil them; ii) traceability of design objects to the implementation objects which instantiate them. The output of the traceability process shall be the subject of formal configuration management.”
Bi-directional traceability helps determine that all source requirements have been completely addressed and that all lower-level requirements can be traced to a valid source. It also covers the relationships to other entities such as intermediate and final work products, changes in design documentation, and test plans.
Last-minute changes of requirements or code made to correct problems identified during test tend to put such ideals in disarray. Despite good intentions, many projects fall into a pattern of disjointed software development in which requirements, design, implementation, and testing artefacts are produced from isolated development phases.
Without a coherent mechanism to dictate otherwise, this isolation results in tenuous and implied links between requirements, the development stages, and/or the development teams, such as that link created by a developer reading a design specification and using that to drive the implementation.
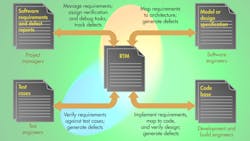
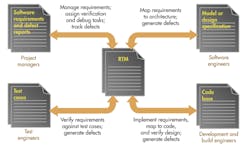
Placing a requirements traceability matrix (RTM) at the heart of a project addresses this issue and encourages the links to be physically recorded and managed (Fig. 3). This alternative view of the development landscape illustrates the fundamental centrality of the RTM. The overhead associated with the RTM and maintenance can be daunting, but the use of appropriate tools can ensure that the RTM is automatically maintained and up-to-date at all times.
Conclusion
High-profile instances of software failure are constant reminders of the need to apply best practices to all safety-critical projects. In many ways, the plight of Toyota in having to deal with the “unintended acceleration” lawsuit is just as loud a wakeup call to safety-critical software projects, not just the automotive sector.
And yet there are differences between those sectors. There is a need for the automotive industry to deal with much higher volume and a much shorter development cycle than aerospace, and that needs to be reflected in what they do. Conversely, unlike automotive companies, medical device developers need to meet the requirements of the FDA and so their risk classification categories need to reflect that.
Nonetheless, there are more similarities than differences between the industry standards. For example, it is common sense whatever the industry to trace requirements and hence ensure that the system does what it is required to do. There are further similarities throughout the development process, design, development, coding and test. Happily, that means tools and techniques proven in one sector provide the same level of assistance in one industry as the next.
References
1. “Toyota Unintended Acceleration and the Big Bowl of ‘Spaghetti’ Code,” Safety Research & Strategies Inc., www.safetyresearch.net/2013/11/07/toyota-unintended-acceleration-and-the-big-bowl-of-spaghetti-code/
2. “Chinese anger over alleged cover-up of high-speed rail crash,” Tania Branigan, The Gardian, July 25, 2011, www.theguardian.com/world/2011/jul/25/chinese-rail-crash-cover-up-claims
3. “Common Implementation of Different Safety Standard Approaches,” W. Sebron, H. Tshurtz, and G. Schedl, www.fh-campuswien.ac.at/index.php?download=4587.pdf
Mark Pitchford has more than 25 years of experience in software development for engineering applications. He has worked on many significant industrial and commercial projects in development and management, both in the U.K. and internationally including extended periods in Canada and Australia. For the past 10 years, he has specialised in software test and works throughout Europe and beyond as a field applications engineer with LDRA. He can be reached at [email protected].
About the Author
Mark Pitchford
Technical Specialist, LDRA
Mark Pitchford has over 25 years’ experience in software development for engineering applications. He has worked on many significant industrial and commercial projects in development and management, both in the UK and internationally. Since 2001, he has worked with development teams looking to achieve compliant software development in safety- and security-critical environments, working with standards such as DO-178, IEC 61508, ISO 26262, IIRA, and RAMI 4.0.
Mark earned his Bachelor of Science degree at Trent University, Nottingham, and he has been a Chartered Engineer for over 20 years. He now works as Technical Specialist with LDRA Software Technology.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: