High Availability is Not Just for the Data Center
High Availability (HA) is commonplace in many data center applications where downtime costs money. Replication and redundancy are worth the added cost because the cost for downtime is even higher.
For embedded applications, HA has more often been related to safety. Be it planes, trains, or automobiles, safety is a requirement. Electronics have made redundancy much easier to implement, making X-by-wire control feasible and economical. Some HA support in embedded applications is common, such as RAID 1 mirroring of storage.
HA in embedded applications is often a matter of degree and timing. For example, many motor control applications need to maintain very strict timing for both the device being controlled as well as failover, should one of the controlling subsystems fail. At the other end of the spectrum, a door may take anywhere from a microsecond to a few seconds to unlock without any problems, so there is often quite a bit of time available to handle a failure. This could be taken to the extreme, given the cloud and Internet of Things (IoT) devices where replication occurs between the cloud and the device.
High Availability Computation
High availability systems can use replication of all or some components to provide a more reliable system. At the extreme end on the hardware side are high-availability systems implemented with hardware synchronization and checking support. One example is Texas Instrument’s (TI) Hercules line, which utilizes a pair of ARM Cortex-R cores (Fig. 1) that operate in lockstep mode where the hardware checks that both systems generate the same results (see “Lock Step Microcontroller Delivers Safe Motor Control”). These are often used in safety critical areas where the hardware needs to run continuously, and additional latency for checking could cause more problems.
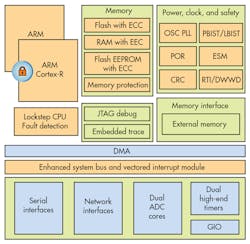
Freescale has a triple-core Qorivva line (see “Multicore Processor Tackles SMP, AMP and Lock Step Mode”) that supports ISO26262 ASIL-D safety integrity functional safety certification. Two of the three cores can operate in lockstep like the Hercules system, with the third operating solo and providing additional system functionality.
Dual-core, lockstep systems can detect errors usually by checking outputs on each clock cycle, but they cannot determine which result is correct when a difference is detected. NASA has often used triple-redundant implementations where a failed device is detected when results from two of the three disagree with the failing device. In this case, the checking hardware is enhanced by the voting hardware that in turn disables a failing device, allowing the other two to continue to run.
This file type includes high resolution graphics and schematics when applicable.
Another mode of operation for a dual core set up is to operate in a master/slave or hot spare mode. In this case, hardware is generally used to detect an error in the CPU such as a memory fault. The system checks for these faults in the master (or primary) system and switches to the slave (or secondary) system.
The approach taken is often dictated by the types of failures a designer has to address and how rapidly the systems need to recover. The lockstep approach is usually designed to support a failover in a single clock cycle. This is often needed in safety critical applications but not for all high-availability applications.
System configuration often dictates how a high-availability system is implemented. For example, Men Micro has an interesting approach that uses a dual-dual system lockstep approach (Fig. 2). It employs two subsystems in a master/slave mode. Each subsystem is like a dual core, lockstep system but operating at the motherboard level for hardware error checking. The master subsystem runs as long as the results from the two internal systems match; otherwise it assumes a failure. This would be similar to a dual-core SoC operating in lockstep detecting a memory error. The slave system becomes the master when an error is detected and the failing system is halted.
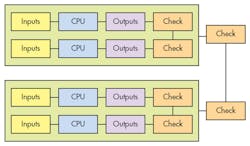
The advantage of this approach is that the subsystems are hot-swappable, much like blade servers or hot-swap disk drives. A failed system can be easily replaced while the other continues to run and the replacement now becomes the slave or hot-spare. Typically some time is required to get the new system into a condition to be the slave since minimally it has to boot up.
Another advantage of this approach is that while the subsystems must run the same applications and have the same I/O, internally there may be hardware differences. That being said, most systems will tend to be very similar or identical. For example, there may be different brands of DRAM or different processor chips used that provide essentially the same functional characteristics for overall system operation. The key is that the software operates in a similar fashion.
Synchronization and voting times for more system- or software-based approaches are not as tight as with chip-based, lockstep mechanisms, but hardware-only mechanisms are significantly faster than pure software-based approaches. On the other hand, software-based solutions provide more flexibility in implementing different synchronization and error-checking systems.
Replication of the I/O can be a challenge especially on the output side, since many devices are harder to replicate. For example, a disk braking system for a single wheel may have only a single rotor, set of pads, and hydraulic system but a redundant processor controlling the hydraulics. It is possible to have a second system or replicate parts of it, such as a second set of pads. The design challenge is to examine both the failure points and the likelihood of failure of each of the components, in addition to the failure modes and their consequences. A car with four independent brakes—one for each wheel—will usually be able to stop a car if one (or possibly two) of these brakes fails depending on where the failure occurs since most cars have a single master cylinder and two separate pressure lines, one for a pair of wheels.
The input side of the equation tends to be a little easier to address since replicating sensors is sometimes less expensive and easier to implement. A motor shaft can easily drive multiple encoders that are used by redundant software systems. Another approach used with some motor control systems is employing sensor feedback to implement virtual encoders. The results of these can be compared with physical encoder inputs. Of course, many motor control systems only use virtual encoders to reduce system cost. Replicating these does not make sense unless alternate software implementations are used.
Fencing and STONITH
Software-based high-availability systems are replacing traditional storage options, like SAN’s, in data centers. They do not require lockstep and error checking hardware, but may employ other means to detect and control multiple systems.
The simplest mechanism for detecting many software failures is heartbeat detection. Many microcontrollers have some hardware support for this approach in the form of a watchdog timer. The timer is started in software with the idea that the application will complete its work and restart the timer before it expires. A watchdog timer can be implemented strictly in software, but a timer interrupt routine is needed to increment the timer and check for expiration. Regardless of whether the timer is hardware or software, the result is to perform an action such as restarting or halting the system.
Systems with two or more cores can implement a heartbeat system in software providing more flexible control. Heartbeat systems can involve servers as well. This is typically what happens with virtual machines (VM) that are often used to implement high availability systems. If the VM’s heartbeat is lost, the VM can be restarted. Likewise, if the heartbeat of the system hosting the VMs is lost then all of the hosted VMs could be restarted on another server.
A simple heartbeat is something like a watchdog timer or a message received within a specific timeframe in response to a query. More complex systems or detection is also possible. For example, the data within a message may have to meet certain criteria like the number of active nodes within a cluster. A three node cluster might be restarted if two of the nodes fail.
The process of managing a system when it fails is called fencing. A system performing the fencing has the ability to detect a failure and then perform some action like resetting the failed system. This is what happens for a microcontroller that has a watchdog timer to restart the system if it times out. This is a very simple case of STONITH (shoot the other/offending node in the head).
There are a variety of STONITH mechanisms available to most designers of systems that provide a variety of services, ranging from restarting to isolating a system. Some examples include controlling the power supply unit (PSU), IPMI (Intelligent Platform Management Interface), and VM control. Network-based PSU and IPMI control is often used in data centers on a management network that is independent of the application network to control the servers. Isolation can also be achieved by controlling network switches or storage services that a system or VM require to operate.
Server operating systems like Linux, Windows, and Solaris include HA services that use these fencing mechanisms. They have typically targeted the data center, but the same tools are found in many embedded HA environments like carrier-grade communication servers.
One system that is popular for managing HA systems on Linux is Pacemaker from Cluster Labs. It supports the orderly start up and shut down of applications and services. Applications are often MVs running on KVM (kernel-based virtual machine). Pacemaker can manage multiple servers within a cluster and multiple clusters. It can scale from small embedded systems to data centers with many clusters and VMs, and it can handle multiple fencing mechanisms. It can even run on small Linux targets like Raspberry Pi.
Fault Tolerant Hardware
One way to minimize downtime is to use one of the forms of local disk RAID support. RAID configurations typically include RAID 0, 1, 5, and 6, or variations of those like RAID 10 that is a combination of RAID 0 and RAID 1. RAID 0 does not provide any fault tolerance but it increases overall transfer rate. RAID 1 is full drive mirroring. It keeps a copy of the data on two disks of the same size. The system continues to work if one disk fails. RAID 5 and 6 use distributed parity. RAID 5 requires at least three disks and continues to work if one fails. RAID 6 uses at least four disks and continues if two disks fail. The type of RAID support to use depends upon the intended application.
Most engineers will be familiar with software RAID or hardware controllers that have RAID support. It is also possible to utilize software RAID support using network storage like iSCSI devices. The use of iSCSI is common in both data centers and the cloud.
High-Availability Storage
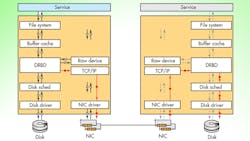
A full system approach is to use services like LINBIT’s DRBD, which provides distributed storage over the network (Fig. 3). DRBD presents a logical block device on each host. This means that any service or application that can write to a hard drive, can be made fully redundant and Highly Available. Various configurations are possible, including active/active and active/passive setups where an active device can be used by local applications, and VMs while a passive device is kept up to date synchronously. In this HA environment, a passive device can be made active if its partner fails. Services and processes would be restarted on the host with the newly activated device without losing data.
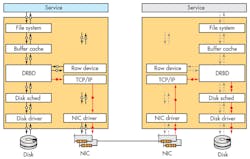
DRBD works with multiple hosts, although two to four host machines tend to be the most common configuration. In addition to fault tolerant hardware, having at least three hosts with the same data provides the ability to survive the loss of one host without restart issues. A two-host active/active configuration can have split-brain problems. This occurs when both hosts are out of sync but both want to be active. This often requires manual intervention to fix. The using of fencing and STONITH support can minimize and/or overcome this, since a failed host will be isolated or restarted while the others maintain data integrity.
Another Linux tool for clusters that provide HA support is CLVM (cluster logical volume manager). This provides a distributed locking mechanism for logical volumes that can be used by local applications and VMs. The latest version can provide RAID support and use network storage like iSCSI devices.
Distribute file systems can also be used with HA systems. Sometimes they are combined with underlying HA storage such as DRBD and CLVM. Some cluster file systems can be used alone, requiring only local storage and a communication mechanism.
Microsoft Windows ReFS (resilient file system) is a distributed file system for Microsoft Servers. Oracle’s Solaris supports a file system named ZFS. ZFS is also available for Linux. Red Hat Enterprise Linux (RHEL) can use GFS2 on CLVM-managed volumes. Another Linux-based cluster file system is Gluster File System. All of these can be used on embedded systems capable of supporting the underlying operating system.
Database services are another form of storage that can often be configured to support HA. The type of underlying storage and network communication required varies between databases, but typically they can use local file systems and TCP/IP networks. Distributed databases services are even available for mobile devices and devices designed for the IoT. Typically device side is a lightweight client that often uses a memory-based or flash-based file system, with data being replicated to the cloud. HA server support allows data replication across servers usually at the table level.
High-Availability Communications
Ethernet and TCP/IP tend to be the communication mechanisms for data centers, as well as for many embedded applications. Multiple channels can be bonded together to provide link aggregation that presents a single logical channel to an environment. This approach can provide additional throughput, in addition to redundancy, for HA environments where automatic failover provides degraded operation when a link fails. Typically multiple switches are employed so there is no single point of failure.
Embedded systems are not restricted to Ethernet, although it is very popular. RapidIO and InfiniBand are used in HA systems as well. Even PCI Express (PCIe) has been tasked with providing the communication mechanism using links like Dolphin Interconnects. PCIe, RapidIO, and InfiniBand have the advantage of low overhead and high throughput. They are switched-based solutions like Ethernet and redundant interfaces, and switches can provide HA support. Native APIs are available, but it is also possible to provide TCP/IP drivers and even Ethernet emulation using these underlying communication links.
Higher level systems can be built these network communication systems. One popular platform is Distributed Data Service (DDS), which uses a publish/subscribe methodology (see “Data Distribution Service Supports OMG’s DDS-XTypes"). DDS can also provide HA support even without underlying HA communication services.
HA applications may or may not interact directly with the underlying HA software and hardware support. HA configurations using tools like Pacemaker can manage application VMs and use HA storage and communications support without modifying the applications. At the other extreme are applications that are tailored to understand the HA support and interact with it more intimately. This is often true of applications using lockstep microcontrollers, but it is even the case of data center applications like database servers.
This file type includes high resolution graphics and schematics when applicable.
Block Level High Availability and Disaster Recovery for any Linux System

Adding full-system high-availability (HA) and disaster recovery (DR) to existing systems can be achieved using Linux-based tools available today. LINBIT has created the module DRBD that is included in the mainline Linux kernel and has been in development since 1999. Whether you are looking to implement an HA system, or extend your current HA infrastructure with disaster recovery, DRBD and DRBD Proxy are both viable options for doing so.
DRBD’s flexibility, robustness, and synchronous replication make it ideal for critical system environments. Synchronous replication is especially helpful for use with databases, as all new writes will be written on two machines before the write is confirmed complete. This is called a fully transaction safe write process and is best used when machines are physically close to each other or connected by a cross over cable.
DRBD is used in thousands of critical applications from security appliances to critical database infrastructure. DRBD presents itself as a normal block device, meaning any application that can be written to a hard drive can be replicated. DRBD can be understood as network-based raid-1, but at the system level instead of disk level. As this is a full-system replica, there are factors that need to be taken into consideration when building an HA cluster. Typically, performance constraints include the speed of the backing storage and the network connecting the machines. DRBD is only going to be able to replicate data as fast as the slowest component in the systems.
As synchronous replication is slow over long-distance connections, LINBIT created DRBD Proxy. DRBD Proxy is designed to allow seamless asynchronous replication. This is done over the WAN connections, and can help overcome throughput and latency constraints. The module utilizes buffering and compression, so that two sites can be kept up to date over anything from fiber to ISDN lines.
While DRBD and DRBD Proxy allow for data to be replicated live across multiple machines, they do not include a cluster manager to switch between the replicated machines in the event of a failure. The tools typically used for this automation of switchover include Heartbeat, Corosync, and Pacemaker cluster resource manager. These open-source tools form the Linux HA Cluster Stack that monitors, starts, and stops processes, resulting in automatic switch over between machines in the event of a failure.
Using this Linux HA cluster stack can reduce IT downtime to seconds instead of minutes or even hours as done in the past with traditional backup solutions. Using the CRM tools with DRBD’s replication allows for a very short time to recovery in the event of a failure.
The flexibility, reliability, and performance that DRBD offers cannot be matched by integrated file system and database replication tools. DRBD is certainly one worth considering for specialized systems that will be used in critical environments.
Jeremy Rust is a sales engineer at LINBIT; assisting engineers in creating tailored high-availability and disaster-recovery solutions.
About the Author

William G. Wong
Senior Content Director - Electronic Design and Microwaves & RF
I am Editor of Electronic Design focusing on embedded, software, and systems. As Senior Content Director, I also manage Microwaves & RF and I work with a great team of editors to provide engineers, programmers, developers and technical managers with interesting and useful articles and videos on a regular basis. Check out our free newsletters to see the latest content.
You can send press releases for new products for possible coverage on the website. I am also interested in receiving contributed articles for publishing on our website. Use our template and send to me along with a signed release form.
Check out my blog, AltEmbedded on Electronic Design, as well as his latest articles on this site that are listed below.
You can visit my social media via these links:
- AltEmbedded on Electronic Design
- Bill Wong on Facebook
- @AltEmbedded on Twitter
- Bill Wong on LinkedIn
I earned a Bachelor of Electrical Engineering at the Georgia Institute of Technology and a Masters in Computer Science from Rutgers University. I still do a bit of programming using everything from C and C++ to Rust and Ada/SPARK. I do a bit of PHP programming for Drupal websites. I have posted a few Drupal modules.
I still get a hand on software and electronic hardware. Some of this can be found on our Kit Close-Up video series. You can also see me on many of our TechXchange Talk videos. I am interested in a range of projects from robotics to artificial intelligence.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: