ARMv8, GPUs And Knights Landing At ISC 2014

The International Supercomputing Conference is the place to be to see the latest massively parallel processors with humongous storage capacity that is delving into big data. Plus it is fun to check out the latest architectures and combinations that are finding they way into the cloud where everyone from academics to experimenters can grab a few billion cycles.
This year's event is no different from the past. All the big names are on hand to show off their new toys. Many of these have been hinted at or highlighted in the past but now we get to see the details, and, in some instances, see real hardware that is shipping.
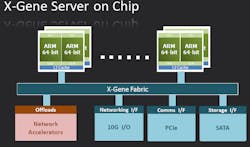
ARM's 64-bit ARMv8 architecture (see “Delivering 64-Bit Arm Platforms”) is finally seeing the light of day with production systems from a range of vendors. AMD has already released their Opteron A1100 based on the Cortex-A57 (see “AMD ARMs 64-Bit Servers”). Applied Micro Circuit's X-Gene (Fig. 1) is based on the ARMv8 architecture and it incorporates Applied Micro's enhancements including a high speed interconnect. X-Gene has found home in platforms like Hewlett-Packard's Moonshot and the Aurora water-cooled HPC system from Eurotech. Eurotech's Brick Technology employs direct hot liquid cooling.
Cirrascale is delivering a system that combines the X-Gene with NVidia's Tesla K20 GPU (see “Expect 3D Printers, 3D Vision, And More In 2013”). The Cirrascale RM1905D 1U server (Fig. 2) runs the X-Gene SoCs on the motherboard and supports a pair of NVidia boards. The interface is via PCI Express.

The Tesla K20 is based on the Kepler GK110. It can deliver 1.17 double precision TFLOPS and 3.95 single precision TFLOPS. It has 5 Gbytes of DDR5 memory and a 208 Gbyte/s memory bandwidth. It incorporates 2496 CUDA cores. CUDA is NVidia's GPU programming language. The Tesla K20 also supports OpenCL.
ARM has garnered quite a few partners but it was not the only thing at ISC 2014. Intel's “Knights Landing” Xeon Phi (Fig. 3) based in Intel's Many Integrated Core (MIC) architecture is being unwrapped at the show. It is a follow on to Knights Corner and the 14 nm chip has 72 cores that are based on the Intel Atom Silvermont architecture. These cores execute four threads and support the AVX-512 vector math (see “Intel's AVX Scales To 1024 bit Vector Math”). The cores are organized in a 2D fabric with two cores per tile or node. There are two AVX-512 units/core. The single core performance is three times that of the previous generation.

It has 16 Gbytes of memory from Micron uses technology similar to the Hybrid Memory Cube (HMC) with a 15 Gbit/s port speed (see “Hybrid Memory Cube Shows New Direction For High Performance Storage”).
Intel tailored the interconnect and memory solution for the new system. The Omni Scale Fabric will be the new interconnect for Xeon Phi going forward. It is functionally similar to InfiniBand. The True Scale technology using by Intel in prior iterations was compatible with InfiniBand. Omni Scale is a different system but it operates the same from a protocol stack view so it will be transparent to most applications. Omni Scale uses Intel's Silicon Photonics optical interconnect for off-board communication.
Knights Landing also has 36 PCI Express v3 channels. This can be used with other peripherals including GPUs. The chip has a 200-W TDP.
The 16 Gbytes of multichannel DRAM (MCDRAM) memory supplied by Micron has five times the bandwidth of of the off-chip DDR4. The Xeon Phi has six DDR4 controllers. The on-chip memory is very dense consuming less than one third the space of conventional DDR while being five times more power efficient. The MCDRAM is comparable to the short reach HMC channel definition.
Intel also recently announced that they had combined a Xeon and FPGA onto a single package. This is being delivered to select customers and the FPGA vendor was not disclosed although Intel has worked closely with Altera in the past to create the Intel E600C system-on-chip that combined an Atom core with an Altera Arria II FPGA. Altera and Xilinx FPGAs have been interfaced directly with Xeon processors using Intel's QuickPath Interconnect (QPI) interface (see “Storage And Computation Capacity Continues To Grow”). In this instance FPGA modules were plugged into a processor socket in a multi processor motherboard.
Developers using OpenCL can take advantage of these FPGA/CPU combinations using tools like Altera's SDK for OpenCL (see “OpenCL FPGA SDK Arrives”). This tool takes OpenCL code that could also run on CPUs or GPUs and converts it to FPGA configuration information.
About the Author

William G. Wong
Senior Content Director - Electronic Design and Microwaves & RF
I am Editor of Electronic Design focusing on embedded, software, and systems. As Senior Content Director, I also manage Microwaves & RF and I work with a great team of editors to provide engineers, programmers, developers and technical managers with interesting and useful articles and videos on a regular basis. Check out our free newsletters to see the latest content.
You can send press releases for new products for possible coverage on the website. I am also interested in receiving contributed articles for publishing on our website. Use our template and send to me along with a signed release form.
Check out my blog, AltEmbedded on Electronic Design, as well as his latest articles on this site that are listed below.
You can visit my social media via these links:
- AltEmbedded on Electronic Design
- Bill Wong on Facebook
- @AltEmbedded on Twitter
- Bill Wong on LinkedIn
I earned a Bachelor of Electrical Engineering at the Georgia Institute of Technology and a Masters in Computer Science from Rutgers University. I still do a bit of programming using everything from C and C++ to Rust and Ada/SPARK. I do a bit of PHP programming for Drupal websites. I have posted a few Drupal modules.
I still get a hand on software and electronic hardware. Some of this can be found on our Kit Close-Up video series. You can also see me on many of our TechXchange Talk videos. I am interested in a range of projects from robotics to artificial intelligence.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: