Cadence’s HiFi DSP Purpose-Built for Next-Gen Voice AI and Audio

What you’ll learn:
- Why voice input is emerging as the next major interface for AI devices and how small language models that run entirely on device are driving the shift.
- Why existing voice interfaces fall short and how fast, efficient DSPs can enable voice controls that approach the context awareness of large language models.
- How Cadence rearchitected the latest generation of its Tensilica HiFi DSP, the iQ, to enable real‑time voice AI and immersive audio.
With recent advances in large language models (LLMs) for audio, voice input is poised to become the new keyboard. To enable seamless, always-on voice interaction with the latest AI devices, chip designers need energy-efficient, easily programmable DSPs capable of running AI locally on the device while performing voice and audio processing, according to Boyd Phelps, SVP and GM of the Silicon Solutions Group at Cadence.
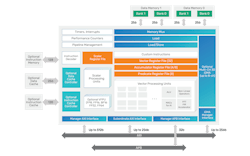
To fill the need, Cadence introduced the next generation of its Tensilica HiFi DSP, the iQ, based on a new architecture purpose-built for emerging voice AI interfaces and immersive audio standards. The HiFi iQ outperforms the company’s current HiFi 5s, offering 2X more raw compute performance and 8X more AI acceleration while reducing power by over 25% for most workloads. The IP promises a 40% performance uplift on many leading audio codecs, which are all becoming more compute intensive.
The execution unit at the heart of the HiFi iQ was upgraded from 128-bit to 256-bit operations to improve its vector processing capabilities, while the number of AI accelerator units was massively increased in the DSP.
The HiFi iQ can run signal-processing algorithms for active noise cancellation (ANC), beamforming, keyword spotting (KWS), and automatic speech recognition (ASR) to enable more accurate natural language processing (NLP).
At the same time, it can also run increasingly advanced small language models (SLMs) and other voice AI models that make sense of speech. These require improvements in both AI acceleration and audio and voice pre- and post-processing functions, which demand more computations performed with low latency and low power at the edge.
Amol Borkar, group director of product management for Cadence’s Tensilica family, said HiFi DSPs are the “de facto” standard for audio, voice, and speech applications, and they are already embedded in billions of audio products every year from smartphones and laptops to cars. But the new HiFi iQ brings a combination of audio processing and AI capabilities that makes it possible to move more of the voice AI pipeline on device.
“We upped the ante in performance because we think that there is going a lot more dependence on running the latest AI models directly on the device, and so we needed something with more muscle on the AI front,” Borkar told Electronic Design.
Is Voice the Interface of the Future for AI?
With the new HiFi iQ, Cadence is trying to keep pace with tech giants and startups rushing to make voice the primary interface for AI, while tackling technical hurdles that have hampered existing voice interfaces.
Today’s voice assistants — Siri, Alexa, and others — are embedded into a wide range of consumer devices, giving users the ability to interact without pushing buttons or tapping touchscreens. However, they have a number of limitations.
These voice interfaces struggle to identify speech in noisy environments and frequently fail to interpret the user’s intent or context in conversational language, said Borkar. Give them anything other than rigid commands, and the result tends to be a misunderstanding, a delayed response, or both. The interactions inevitably feel less like engaging with a voice assistant and more like navigating a menu.
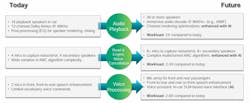
But AI is changing that. Amazon, Google, and others are rebuilding their voice assistants on top of LLMs that are not only more accurate, but they can also comprehend conversational speech, understand context, remember user preferences, and tailor responses in real-time.
Furthermore, Apple is integrating LLMs to create a more personalized version of Siri that can better understand context and intent. And OpenAI is racing to roll out more advanced audio models that can hold conversations, handle interruptions, and, in general, close the gap with chatbots like ChatGPT.
These voice AI interfaces are being integrated into anything and everything. Meta introduced its latest Ray-Ban smart glasses that gives users the ability to ask, “What am I looking at?” and hear the answer or see real-time subtitles in their field of view. A new startup called Sandbar revealed a smart ring that it calls “a mouse for voice” because it can record notes, control music, and help users interact with AI assistants. Other new players are pushing into the same space, rolling out always‑on, always-listening AI devices including screenless “pins.”
Automakers such as Volkswagen and Geely are also adding AI to cars to create conversational voice assistants that can give real-time, context-aware information and control the navigation and other systems. “Voice is being used as an input into a lot of these AI agents,” said Borkar.
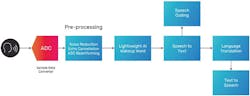
The rise of voice interfaces is also supported by new SLMs. In many cases, the front end of the voice processing pipeline — everything from processing audio at high sampling rates from the ADC to noise reduction, echo cancellation, and beamforming to translating the speech to text and vice versa — runs entirely on device today. Then, the device connects to the cloud where LLMs determine what was said and how to respond.
SLMs are designed to be small enough that they can run locally on devices such as laptops despite not being as general-purpose as LLMs. They tend to be comprised of several hundred million parameters instead of the tens of billions of parameters in LLMs. Last month at CES, Cadence showed a SLM running on one of its HiFi DSPs “context-trained” on a vehicle user manual, allowing drivers to ask the car about itself directly instead of forcing them to flip through the physical manual.
While many voice-controlled devices can understand a small, fixed vocabulary today, the cloud is required for anything more conversational, which inevitably adds latency and uses more power because it depends on constant wireless connectivity.
“These SLMs are being scoped down to specific contexts,” said Borkar, “and they are becoming small enough that you can run them entirely on the device itself and so that you no longer need network connectivity.”
But as voice AI continues to evolve, running it locally requires fast, energy-efficient processors that can not only capture the user’s voice clearly and translate it to text accurately, but also run the SLMs and play audio to respond to the user. What’s key is staying within the tight power budgets of wearables, headphones, and always-on devices.
However, since most of these designs have strict power and thermal constraints, raising the core operating frequency of the DSP or integrating multiple DSP cores into the SoC is often not a viable option, said Borkar.
He added, “Even though these SLMs are becoming small enough that they can run on the embedded device, they still require a significant amount of computing. HiFi DSPs do have AI capabilities but not to the extent of being able to execute these SLMs very fast. They can execute them, but the compute units are much smaller, so it will inevitably be a lot slower, and they may not be sufficient [to allow] for real-time responses from the voice assistant.”
Bringing Voice AI Out of the Cloud and Down to the Device
Cadence said the new HiFi iQ architecture addresses those constraints, positioning it as a key building block for the next wave of voice‑first devices. “We couldn’t just do an incremental enhancement of the HiFi 5 to go to the HiFi iQ,” noted Borkar, “We had to fully re-architect it.”

The HiFi iQ significantly boosts AI performance compared with Cadence’s current flagship HiFi 5s DSP, increasing the number of AI MACs to as many as 256 from around 32. The multiply-accumulate (MAC) units are the core computing engines in AI processors, such as neural processing units (NPUs). The IP giant also said it more than doubled the number of traditional MACs that are fundamental building blocks in DSPs used for audio, voice, and speech processing.
The HiFi iQ allows customers to configure more floating-point units (FPUs) focused on vector processing. Borkar said Cadence also upgraded them to run a wider range of data types, including FP16, FP32, and FP64, as well as new standards such as FP8 and BF16, which are often required to run state-of-the-art voice AI. The iQ is configurable in terms of its memory interfaces and sizes. Most LLMs and SLMs are too large and complex to fit into a single chip, so it’s necessary to move data from external memory for execution.
The HiFi iQ is fully capable of running popular SLMs and even more compact LLMs used in voice control on the DSP itself, acting as an all-in-one AI processor, said Borkar. For an additional boost, it can be easily paired with Cadence’s Neo NPUs or customer-built NPUs to further enhance performance and energy efficiency. He explained, “We added a lot more AI configurability to the iQ on top of offering more AI performance.”
Related to that, the iQ is compatible with the company’s NeuroWeave Software Development Kit (SDK) and TensorFlow Lite for Micro (TFLM), along with several different environments to enable AI model execution. The iQ also leverages the vast ecosystem of partners that have developed software libraries, compilers, codec packages, frameworks, and more for HiFi DSPs to enable easier deployment and faster time-to-market, said Cadence.
On top of that, according to the company, the HiFi iQ brings more than enough performance to the table for traditional audio to run immersive audio codecs like Dolby MS12, Eclipsa Audio, Opus HD, and Audio Vivid with higher efficiency than previous HiFi DSPs like the HiFi 5s. And multi-stream and multi-channel audio playback opens the door to rendering of 3D spatial zones and sound bubbles, delivering more realistic listening experiences.
The new IP is expected to be broadly available in the second quarter of 2026. Cadence also has plans for future HiFi iQ DSPs that can be arranged into cache-coherent multicore configurations.
About the Author

James Morra
Senior Editor
James Morra is the senior editor for Electronic Design, covering the semiconductor industry and new technology trends, with a focus on power electronics and power management. He also reports on the business behind electrical engineering, including the electronics supply chain. He joined Electronic Design in 2015 and is based in Chicago, Illinois.