Tall Arrays Allow Cross-Platform Manipulation
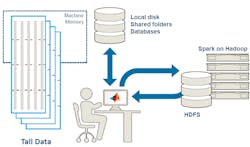
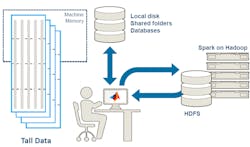
The Mathworks’ MATLAB R2016a had a number of improvements, including Live Editing and big data analytics. The latest iteration, MATLAB R2016b, incorporates a new data type: tall arrays (see figure). Tall arrays allow MATLAB users to access data from a number of sources, ranging from databases to a Hadoop Distributed File System (HDFS). They are not limited by the amount of memory on the host computer.
MATLAB R2006b introduced the concept of distributed arrays. This allowed developers to take advantage of a cluster running a MATLAB application on multiple machines with in-memory data distributed among the machines. This feature is still available, but the challenge is designing the application and distributing the data.
Tall arrays can be used in a variety of ways—from a single system running an application that has access to large amounts of data (that will not fit into the host memory) to a Hadoop system with many processors (that have access to HDFS). The same MATLAB code will run on these and other configurations with MATLAB, managing the data manipulation and program distribution. This greatly simplifies the developer’s job, allowing them to concentrate on the algorithm rather than data management.
Although tall arrays can use an SQL database table or a spreadsheet file as a source, they use MATLAB’s Datastore support added in MATLAB 2014b to define where data is coming from. An application can use any number of convention or tall arrays, so application data could be spread around a number of sources with MATLAB managing the entire system.
Tall arrays are columnar data with rows of elements like a database table or spreadsheet. Support includes mathematical and statistical operations, as well as data manipulation operations. The Mathworks also provides statistical and machine learning algorithms, and tall arrays are supported by the parallel compute toolbox.
Using tall arrays with a Hadoop cluster allows the system to run the application in the cluster, rather than bringing the data into a host PC. This provides significantly more processing power and storage than even the usually multicore server.
Debugging and profiling on a Hadoop cluster is a bit challenging, so developers will likely work on a local PC to develop algorithms that use tall arrays. The algorithms can then be moved to the cluster if very large amounts of data and compute power are needed. The PC provides interactive debugging, tracing, and profiling.
The tall array data type is supported by MATLAB’s packaging system, which lets a developer create a royalty-free application in the same fashion as an application developed using C tools. This requires a bit more configuration to handle various data sources, but a package can be set up to work with any data sources a developer has to work with using the interactive version of MATLAB.
The MATLAB Coder system that generates C code for embedded applications also supports tall arrays. This allows this support to be included in embedded applications.
The Mathworks also added the MATLAB API for Spark to MATLAB 2016b. Apache Spark is directed acyclic graph (DAC) execution engine that is compatible with Hadoop. It is another way to take advantage a Hadoop cluster. This requires significantly more programming compared to using tall arrays.
Developers using the MATLAB API for Spark work at the Spark API level. It includes functions like flatMap and mapParitions compared to tall arrays that use MATLAB array operations.

About the Author

William G. Wong
Senior Content Director - Electronic Design and Microwaves & RF
I am Editor of Electronic Design focusing on embedded, software, and systems. As Senior Content Director, I also manage Microwaves & RF and I work with a great team of editors to provide engineers, programmers, developers and technical managers with interesting and useful articles and videos on a regular basis. Check out our free newsletters to see the latest content.
You can send press releases for new products for possible coverage on the website. I am also interested in receiving contributed articles for publishing on our website. Use our template and send to me along with a signed release form.
Check out my blog, AltEmbedded on Electronic Design, as well as his latest articles on this site that are listed below.
You can visit my social media via these links:
- AltEmbedded on Electronic Design
- Bill Wong on Facebook
- @AltEmbedded on Twitter
- Bill Wong on LinkedIn
I earned a Bachelor of Electrical Engineering at the Georgia Institute of Technology and a Masters in Computer Science from Rutgers University. I still do a bit of programming using everything from C and C++ to Rust and Ada/SPARK. I do a bit of PHP programming for Drupal websites. I have posted a few Drupal modules.
I still get a hand on software and electronic hardware. Some of this can be found on our Kit Close-Up video series. You can also see me on many of our TechXchange Talk videos. I am interested in a range of projects from robotics to artificial intelligence.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: