Can RISC-V Do for GPUs What It’s Done for CPUs?

This article is part of TechXchange: RISC V
What you’ll learn:
- How RISC-V will work as a GPU.
- What issues are involved in designing a GPU using RISC-V?
Anyone who has looked into GPU architecture knows it’s a SIMD construct of vector processors. It’s a super-efficient parallel processor that has been used for everything from running simulations and fabulous games to teaching robots how to acquire AI, and helping clever people manipulate the stock market. It’s even checking my grammar as I write this.
But GPU land has been a proprietary place where the inner workings are the IP and secret sauce of developers like AMD, Intel, Nvidia, and a few others. What if there was a new set of graphics instructions designed for 3D graphics and media processing? Well, there may be.
New instructions are being built on the RISC-V base vector instruction set. They will add support for new data types that are graphics-specific as layered extensions in the spirit of the core RISC-V ISA. Vectors, transcendental math, pixels and textures, and Z/Frame buffer operations are supported. It can be a fused CPU-GPU ISA. Pixilica is calling it the RV64X (Fig. 1), as instructions will be 64 bits long (32 bits will not be enough to support a robust ISA).
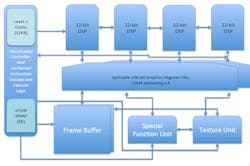
The group says their motivation and goals are driven by the desire to create a small, area-efficient design with custom programmability and extensibility. It should offer low-cost IP ownership and development, and not compete with commercial offerings. It can be implemented in FPGA and ASIC targets and will be free and open source. The initial design, targeted at low-power microcontrollers, will be Khronos Vulkan compliant and support other APIs (OpenGL, DirectX, etc.) over time.
GPU + RISC-V
The target hardware will have a GPU functional unit plus a RISC-V core. The combination appears as a processor with 64-bit-long instructions coded as scalar instructions. The trick is that the compiler will generate SIMD instructions from prefixed scalar opcodes. Among the other features are a variable-issue, predicated SIMD backend; branch shadowing; precise exceptions; and vector front-end. Designs will include a 16-bit fixed-point version and a 32-bit floating-point version. The former would be suitable for FPGA implementations.
“There won’t be any need for the RPC/IPC calling mechanism to send 3D API calls to/from unused CPU memory space to GPU memory space and vice versa,” says the team.
The “fused” CPU-GPU ISA approach has the advantage of potentially using a standard graphics pipeline in microcode as well as the ability to support custom shaders. Even ray-tracing extensions could be included.
The design will employ the Vblock format (from the Libre GPU effort):
- It's a bit like VLIW (only not really).
- A block of instructions is pre-fixed with register tags that give extra context to scalar instructions within the block.
- Sub-blocks include Vector Length, Swizzling, Vector/Width overrides, and predication.
- All of this is added to scalar opcodes!
- There are no vector opcodes (and no need for any).
- In the vector context, it goes like this: If a register is used by a scalar opcode, and the register is listed in the vector context, vector mode is activated.
- Activation results in a hardware-level for-loop issuing multiple contiguous scalar operations (instead of just one).
- Implementers are free to implement the loop in any fashion they desire—SIMD, multi-issue, single-execution; pretty much anything.
The RV32-V vector handles 2- to 4-element/8-, 16- or 32-bit/element vector operations. There will also be specialized instructions for a general 3D graphics rendering pipeline for 64- and 128-bit fixed and float XYZW points; 8-, 16-, 24- and 32-bit RGBA pixels; 8-, 16 bits per component UVW texels; as well as lights and material settings (Ia, ka, Id, kd, Is, ks…).
Attribute vectors are represented as 4-by-4 matrices. The system will natively support 2-by-2 and 3-by-3 matrices. The vector support may also be suitable for numerical simulations using 8-bit integer data types that are common in AI and machine-learning applications.
Custom rasterizers such as splines, SubDiv surfaces, and patches can be included in a design. The approach also allows for inclusion of custom pipeline stages, custom geometry/pixel/frame buffer stages, custom tessellators, and custom instancing operations.
RV64X
The RV64X reference implementation includes:
- Instruction/data SRAM cache (32 kB)
- Microcode SRAM (8 kB)
- Dual function instruction decoder (hardwired implementing RV32V and X; micro-coded instruction decoder for custom ISA)
- Quad vector ALU (32 bits/ALU—fixed/float)
- 136-bit register files (1k elements)
- Special function unit
- Texture unit
- Configurable local frame buffer
The RV64X is a scalable architecture (Fig. 2). Its fused approach is new as is the use of configurable registers for custom data types. The user-defined, SRAM-based micro-code can be used to implement extensions such as custom rasterizer stages, ray tracing, machine vision, and machine learning. A single design could be applied to a standalone graphics microcontroller or a multicore solution with scalable shader units.
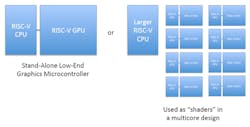
Graphic extensions for RISC-V can resolve the scalability and multi-language issues. This could enable a higher level of use cases, leading to more innovation.
What’s Next
The RV64X specification is still in early development and subject to change. A discussion forum is being set up. The immediate goal is to build a sample implementation with an instruction set simulator. This would run on an FPGA implementation using open-source IP plus custom IP designed as an open-source project. Contact the author, Atif Zafar: [email protected] if you want to become more involved.
About the Author

Jon Peddie
President
Dr. Jon Peddie heads up Tiburon, Calif.-based Jon Peddie Research. Peddie lectures at numerous conferences on topics pertaining to graphics technology and the emerging trends in digital media technology. He is the former president of Siggraph Pioneers, and is also the author of several books. Peddie was recently honored by the CAD Society with a lifetime achievement award. Peddie is a senior and lifetime member of IEEE (joined in 1963), and a former chair of the IEEE Super Computer Committee. Contact him at [email protected].
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: