UMI Scales the Memory Wall in the Chiplet/Multi-Die Era

This article is part of the TechXchange: Chiplets - Electronic Design Automation Insights.
What you’ll learn:
- What are the current challenges involved with incorporating sufficient HBM into multi-die design?
- How a new interconnect technology can address the performance, size, and power issues that could hinder broader adoption of chiplet-based design, including achieving necessary performance without the need for advanced packaging.
- Does a new die-to-memory interconnect solution, called Universal Memory Interface (UMI), hold the promise to address the growing “memory wall?”
A cruel irony is occurring at an accelerating pace as we drive forward into the generative AI era: While the improvements in processor performance to enable the incredible compute requirements of applications like ChatGPT get all of the headlines, a not-so-new phenomenon known as the memory wall risks negating those advances. Indeed, it’s been clearly demonstrated that as CPU/GPU performance increases, wait time for memory also increases, preventing full utilization of the processors.
With the number of parameters in the generative-AI model ChatGPT-4 reportedly close to 1.4 trillion, artificial intelligence has powered head-on into the memory wall. Other high-performance applications aren’t far behind. The rate at which GPUs and AI accelerators can consume parameters now exceeds the rate at which hierarchical memory structures, even on multi-die assemblies, can supply them. The result is an increasing number of idle cycles while some of the world’s most expensive silicon waits for memory.
Traditionally, three approaches have been used to pry open this bottleneck. The easiest—in the days when Moore’s Law was young—was to make faster DRAM chips with faster interfaces. Today, that well is dry. The second approach was to create a wider pathway between the memory array—which can produce thousands of bits per cycle in parallel—and the processor die. Arguably this has been taken near its practical limit with the 1-kb-wide high-bandwidth-memory (HBM) interface.
The third alternative is to use parallelism above the chip level. Instead of one stack of HBM dies, use four, or eight, each on its own memory bus. In this way, the system architect can expand not just the amount of memory directly connected to a processing die, but also the bandwidth between memory and the compute die.
Space Challenges at the SiP and Die Levels
The trouble is, this approach runs into two hard limits, both involving real estate. At the system-in-package (SiP) level, there’s no room left for more memory. We’re already filling the largest available silicon interposers. Making room for more memory would mean leaving out some computing dies.
At the die level exists a different issue. Computing dies—whether CPU, GPU, or accelerator—are prime real estate, usually built in the most advanced and expensive process technology available. Designers want all of that die area for computing—not for interfaces. They’re reluctant to give up any of it, or any of their power budget, for additional memory channels.
So, it’s a dilemma. Architects need the added memory bandwidth and capacity that more memory channels can bring. But they’re out of area on silicon interposers. And compute designers don’t want to surrender more die area for interfaces.
Fortunately, there’s a solution.
Introducing the Universal Memory Interface
Rather remarkably, one new proposal employing proven technology can relieve both the substrate-level and the die-level real-estate issues. And this, in turn, can push open the memory bottleneck. That technology is the Universal Memory Interface (UMI).
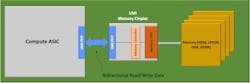
UMI is a high-speed, lane-based interface similar to UCIe or the Open Compute Project’s (OCP) Bunch of Wires (BoW) standard. In fact, UMI’s developer, Eliyan, points out that UMI is a straightforward extension to BoW.
Key differences exist between UMI and these earlier technologies, though. These differences make possible interposer-level speeds across standard organic substrates, a significant reduction in the compute die area given over to memory interfaces, and large potential improvements in both interconnect speed and power.
The Role of NuLink PHY in UMI
NuLink PHY, an Eliyan IP product, was the original PHY that BoW was based on. Being an extension of BoW, UMI gains its unique advantages from an improved version of NuLink PHY.
One important attribute of this PHY is its affinity for organic substrates. Most PHY IP used for inter-die communication is optimized for advanced packaging substrates like silicon interposers. However, the NuLink PHY is designed to not only operate over advanced packaging, but also deliver full data rate across the very different and more challenging electrical environment of organic substrates—over distances up to several centimeters. This has important implications for memory-bound systems.

First, the ability to use organic substrates opens up space. The largest silicon interposer currently in production measures ~2700 mm2. Standard organic substrates can be up to 4X that size. This allows designers to put more HBM stacks in the SiP, increasing memory capacity and parallelism. There may be room for more big computing dies as well.
The two or three centimeters of range also has a vital benefit. Typically, memory stacks will be placed abutting the compute dies they serve to get the best possible data rates through existing interfaces. But, not only does this restrict layouts rather severely, it also creates strong thermal coupling between the notoriously hot compute die and the notoriously heat-sensitive HBM dies, introducing a serious failure mode for the entire system.
Greater range relaxes layout constraints for both die and substrate. And it allows for separation between compute dies and HBM stacks, enabling compute circuitry to run at its maximum speed without overheating the delicate memory.
UMI Approach to Reversible Lanes
Just as significant for interfacing to memory is another function of the NuLink PHY leveraged UMI: dynamically reversible data lanes. Common memory interfaces such as DDR DRAM and HBM use reversible data channels, switching back and forth between read and write modes. But today’s inter-die interface specifications define only unidirectional lanes.
This means that today’s interfaces must devote two lanes to each memory channel: one for read and a second for write. And that means significantly more precious compute-die area and power budget must go to memory interfaces—not to mention substrate interconnect capacity. UMI, in contrast, assigns one reversible lane to each reversible memory lane—a potential savings of a factor of nearly two.
UMI’s Speed, Power, and Versatility Benefits
In addition to these points, the NuLink PHY gives UMI the benefits of its advanced architecture and circuit designs. Roughly, in the same environment and process technology NuLink can operate at twice the speed and half the power of alternative solutions. It’s not necessary to elaborate on the significance of those figures to system designers.
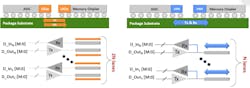
Finally, it should be pointed out that, despite the name, nothing in the UMI specification limits its use between compute dies and memory dies. UMI is just as beneficial as a general-purpose inter-die interconnect.
Exploiting the NuLink PHY, UMI brings a host of advantages to designers of multi-die SiPs that are facing the memory wall. These include multi-centimeter range at full speed over organic substrates, freeing designers from the high cost, size limits, and crowding of silicon interposers; switched bidirectional data lanes to slash the size of most memory interfaces; and inherent high speed at low power compared to the alternatives.
This is why Eliyan is proposing UMI to OCP as an extension to the BoW standard. We believe all memory-bound SiP designs can benefit.
Read more articles in the TechXchange: Chiplets - Electronic Design Automation Insights.
About the Author

Ramin Farjadrad
Co-Founder and CEO, Eliyan
Ramin Farjadrad is the inventor of more than 140 granted and pending patents in communications and networking, and the inventor of the innovative and proven Bunch of Wires (BoW) scheme, which has been adopted by the Open Compute Project (OCP). He has a successful track record of creating differentiating connectivity technologies adopted by the industry as international standards (two Ethernet standards at IEEE, the BoW chiplet connectivity standard at OCP).
Ramin co-founded Velio Communications, which led to a Rambus/LSI Logic acquisition, and Aquantia, which IPO’d and was acquired by Marvell Technologies. He holds a Ph.D. EE is from Stanford.
Comment About the Article
To join the conversation, and become an exclusive member of Electronic Design, create an account today!

Leaders relevant to this article: